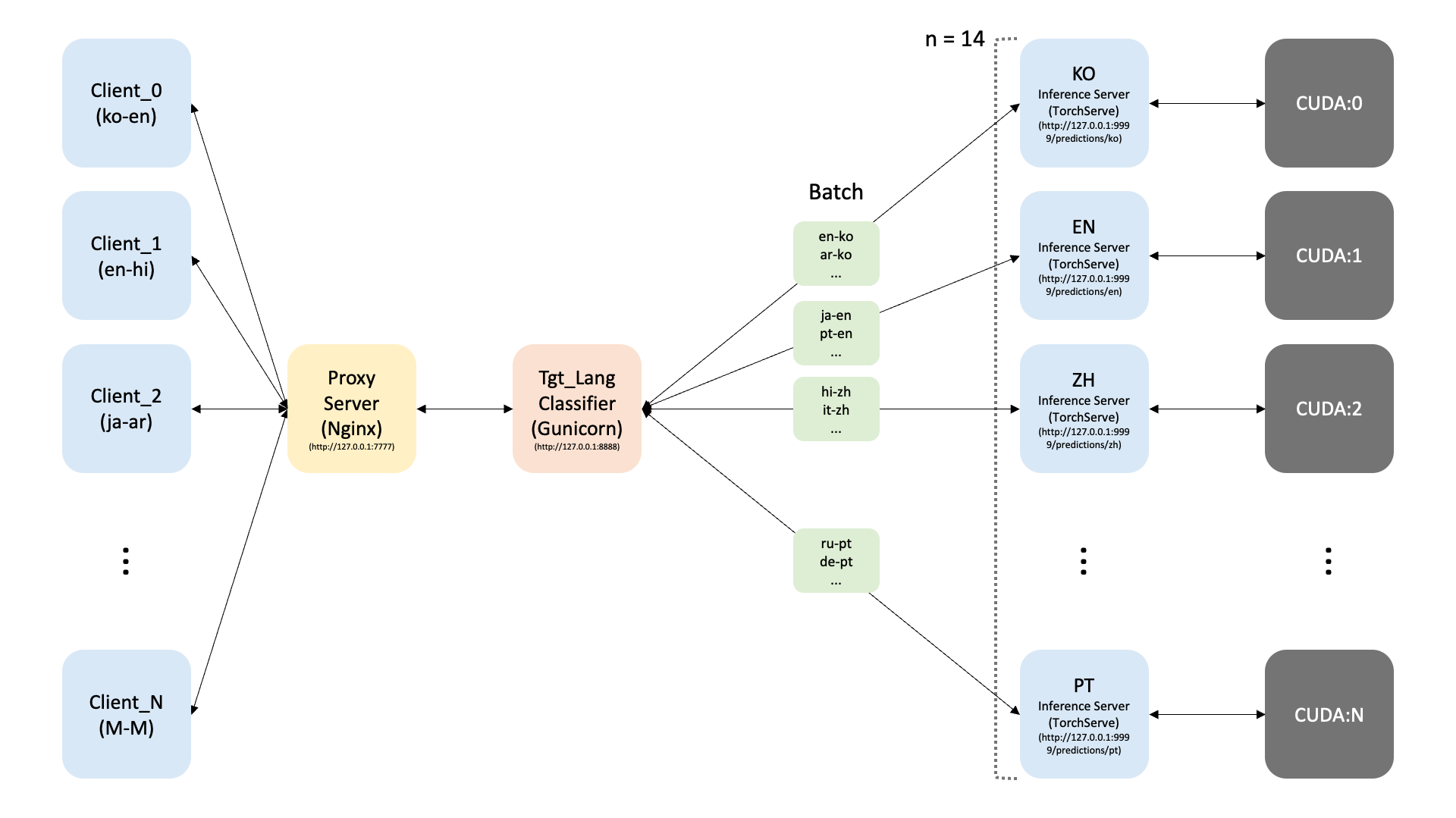
#!/bin/bashmodel_names="ko en zh es fr ru id ja vi de it hi ar pt"model_dir=../model/voiceprint/m2m100_418M
model_ver=1.0
if["$1"="new"];thenif[-f./model_dirlist.txt];thenrm./model_dirlist.txt
fiecho|ls$model_dir>./model_dirlist.txt
readarrayfiles<./model_dirlist.txt
if[-f./model_dirlist.txt];thenrm./model_dirlist.txt
fifiles_len=${#files[@]}foridsin${!files[@]}doif[["${files[$ids]}"=~".bin"]];thenmodel_file=${files[$ids]}files_len=$((files_len-1))elsefile_name=${files[$ids]}if[$ids=$files_len];thenextra_files_args=$extra_files_args$model_dir/$file_nameelseextra_files_args=$extra_files_args$model_dir/$file_name,
fifidoneextra_files_args=`echo$extra_files_args|tr-d' '`if[-d./logs];thenrm-rf./logs
echoDirectory./logsRemoved!!!
fiif[-d./model_store];thenrm-rf./model_store
echoDirectory./model_storeRemoved!!!
fiif[!-d./model_stre];thenmkdir./model_store
echoDirectory./model_storeMade!!!
fiechoTorchModelArchiverStart...
formodel_namein$model_namesdoif[-f./$model_name.mar];thenrm./$model_name.mar
fitimetorch-model-archiver--model-name$model_name--version$model_ver--serialized-file$model_dir/$model_file--handler./handlers/$model_name.py--extra-files"$extra_files_args"mv./$model_name.mar./model_store
echo./$model_name.marMovedto./model_store
donefitorchserve--start--model-store./model_store--ts-config./config.properties&&sleep5s\&&\formodel_namein$model_namesdocurl-XPOST"localhost:8081/models?url="$model_name".mar&batch_size=64&max_batch_delay=100"done
4) config.properties 수정
config.properties도 Batch Inference에 맞게 수정한다.
# Configure TorchServe listening address and port
inference_address=http://127.0.0.1:9999
management_address=http://127.0.0.1:8081
metrics_address=http://127.0.0.1:8082
# Limit GPU usage
number_of_gpu=4
# Load models at startup
model_store=./model_store
#load_models=en.mar
# Other properties
# Worker / Capacity
default_workers_per_model=1
job_queue_size=4096
default_response_timeout=86400
5) setup_config.json 생성
모델이 있는 /root/Project/model/voiceprint/m2m_418M 디렉터리에 setup_config.json을 생성한다.
importmultiprocessing# Python Module:Variablewsgi_app="classifier:app"# Host:Portbind="127.0.0.1:8888"# Worker Class == Default: "sync"worker_class="gevent"# Num of Workers# workers = int(multiprocessing.cpu_count() * 0.1)workers=16# Num of Worker Connectionsworker_connections=1024# Timeout == 0(Deactivate)timeout=86400
4. Nginx 서버
1) nginx.conf 수정
다음과 같이 nginx.conf를 수정한다.
user www-data;
worker_processes 10; # 동시에 Requests 받을 수 있는 수 = worker_processes * worker_connections
pid /run/nginx.pid;
include /etc/nginx/modules-enabled/*.conf;
# worker_rlimit_nofile 2048;
events {
worker_connections 4096; # Reverse Proxy이므로 2배 설정
multi_accept on;
use epoll;
}
http {
##
# Basic Settings
##
sendfile on;
tcp_nopush on;
tcp_nodelay on;
##
# Server Settings
##
server {
listen 7777;
server_name localhost;
location / {
proxy_pass http://127.0.0.1:8888/$1;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
##
# Timeout Settings
##
# keepalive_timeout 86400; # Connection 시간
# keepalive_reqeusts 100 # Connection 횟수
client_body_timeout 86400; # Client로부터 request body를 받는 시간
send_timeout 86400; # Client에게 response body를 보내는 시간
reset_timedout_connection off; # Timeout으로 Connection이 끊긴 경우 리셋
proxy_connect_timeout 86400; # Proxy 서버와 연결되는 시간 (75초를 초과할 수 없음)
proxy_send_timeout 86400; # Proxy 서버에 요청을 보내는 시간
proxy_read_timeout 86400; # Proxy 서버에서 응답을 받는 시간
types_hash_max_size 2048;
# server_tokens off;
# server_names_hash_bucket_size 64;
# server_name_in_redireict off;
include /etc/nginx/mime.types;
default_type application/octet-stream;
##
# SSL Settings
##
ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3; # Dropping SSLv3, ref: POODLE
ssl_prefer_server_ciphers on;
##
# Logging Settings
##
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log;
##
# Gzip Settings
##
gzip on;
# gzip_vary on;
# gzip_proxied any;
# gzip_comp_level 6;
# gzip_buffers 16 8k;
# gzip_http_version 1.1;
# gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript;
##
# Virtual Host Configs
##
# include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
}
#mail {
# # See sample authentication script at:
# # http://wiki.nginx.org/ImapAuthenticateWithApachePhpScript
#
# # auth_http localhost/auth.php;
# # pop3_capabilities "TOP" "USER";
# # imap_capabilities "IMAP4rev1" "UIDPLUS";
#
# server {
# listen localhost:110;
# protocol pop3;
# proxy on;
# }
#
# server {
# listen localhost:143;
# protocol imap;
# proxy on;
# }
#}