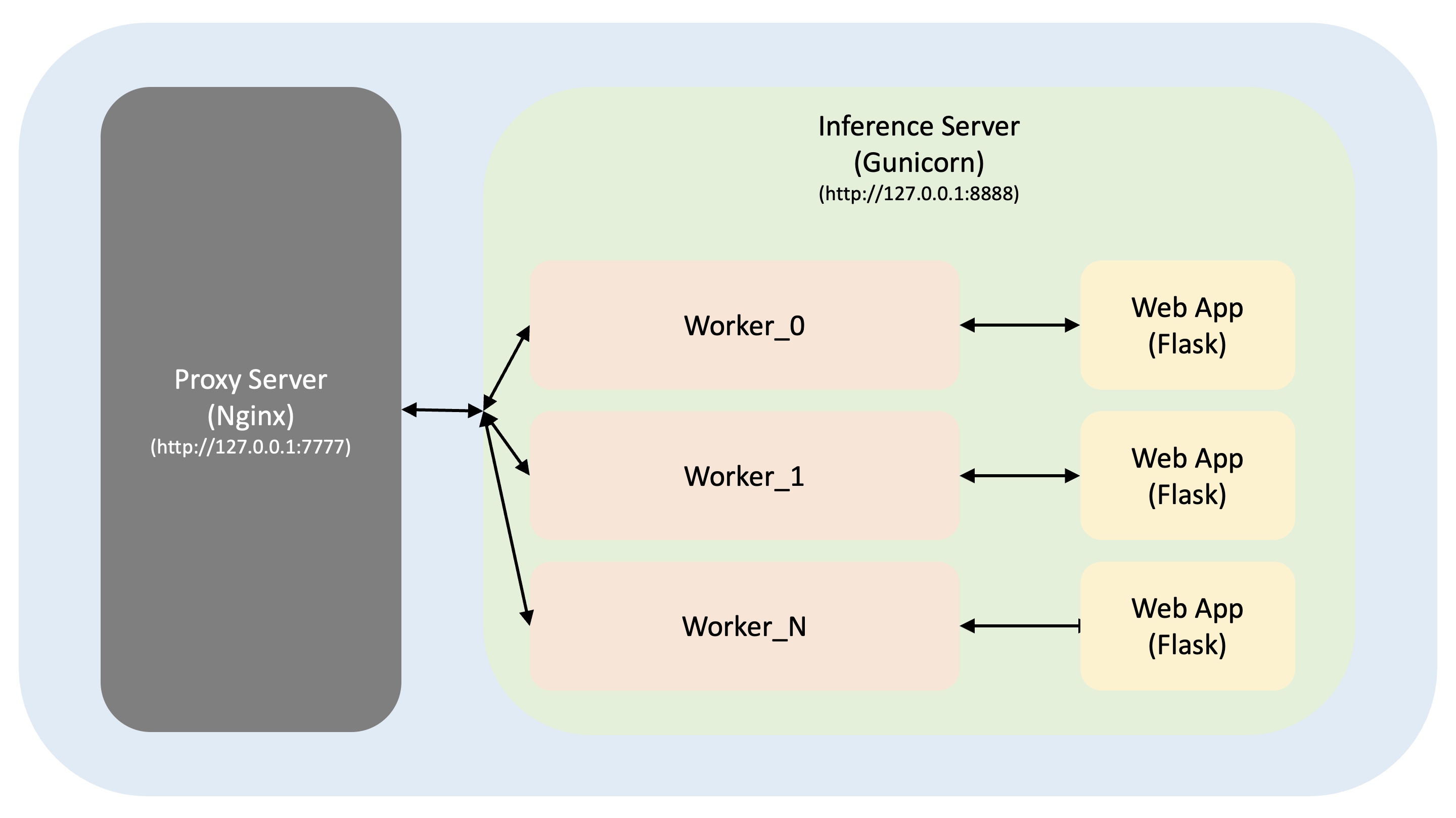
3. Nginx + Gunicorn + Flask
1. Mission
2. Gunicorn + Flask
1) Dependencies 설치
다음과 같이 Dependencies를 설치한다.
$( torchserve) pip install flask gunicorn
2) server_flask.py 작성
다음과 같이 Python 스크립트를 작성한다.
from flask import Flask , request
from transformers import M2M100ForConditionalGeneration , M2M100Tokenizer , AutoTokenizer
import os , time
import torch
torch . set_grad_enabled ( False )
torch . set_num_threads ( 4 )
app = Flask ( __name__ )
class ModelInference :
def __init__ ( self , model_name : str ):
self . PID = os . getpid ()
print ( f "PID: { self . PID } / Downloading Model..." )
self . model_name = model_name
self . tokenizer = AutoTokenizer . from_pretrained ( self . model_name )
self . model = M2M100ForConditionalGeneration . from_pretrained ( self . model_name )
self . model . to ( "cpu" )
self . quantized_model = torch . quantization . quantize_dynamic ( self . model , { torch . nn . Linear }, dtype = torch . qint8 )
del self . model
print ( f "PID: { self . PID } / Downloaded Model!" )
def predict ( self , src_lang : str , src_text : str , tgt_lang : str ):
self . tokenizer . src_lang = src_lang
encoded_text = self . tokenizer ( src_text , return_tensors = "pt" ) . to ( "cpu" )
generated_tokens = self . quantized_model . generate ( ** encoded_text , forced_bos_token_id = self . tokenizer . get_lang_id ( tgt_lang ), num_beams = 2 )
translated = str ( self . tokenizer . batch_decode ( generated_tokens , skip_special_tokens = True )) . strip ( "]['" )
return translated
model_class = ModelInference ( "/root/Project/model/voiceprint/m2m100_418M" )
@app . route ( "/" , methods = [ "POST" ])
def main ():
p = request . get_json ( force = True )
src_lang = p [ "src_lang" ]
src_text = p [ "src_text" ]
tgt_lang = p [ "tgt_lang" ]
start = time . time ()
translated = model_class . predict ( src_lang , src_text , tgt_lang )
end = time . time ()
print (
f " \n PID: { model_class . PID } \n Src_Lang: { src_lang } / Src_Text: { src_text } \n Tgt_Lang: { tgt_lang } / Translated: { translated } \n Time: { end - start } sec. \n "
)
return { "translated" : translated }
if __name__ == "__main__" :
app . run ( host = "0.0.0.0" , port = "80" , debug = True )
3) gunicorn.conf.py 작성
다음과 같이 모델 서버의 구성을 지정할 수 있다.
import multiprocessing
# Python Module:Variable
wsgi_app = "server_flask:app"
# Host:Port
bind = "127.0.0.1:8888"
# Worker Class == Default: "sync"
worker_class = "gevent"
# Num of Workers
# workers = int(multiprocessing.cpu_count() * 0.1)
workers = 16
# Num of Worker Connections
worker_connections = 1024
# Timeout == 0(Deactivate)
timeout = 0
4) Gunicorn + Flask 실행
3. Nginx + Gunicorn + Flask 테스트
1) client.py 실행
다음과 같이 Python 스크립트를 실행한다.
$( torchserve) python client.py gunicorn