4. Nginx + Streamlit
1. Mission
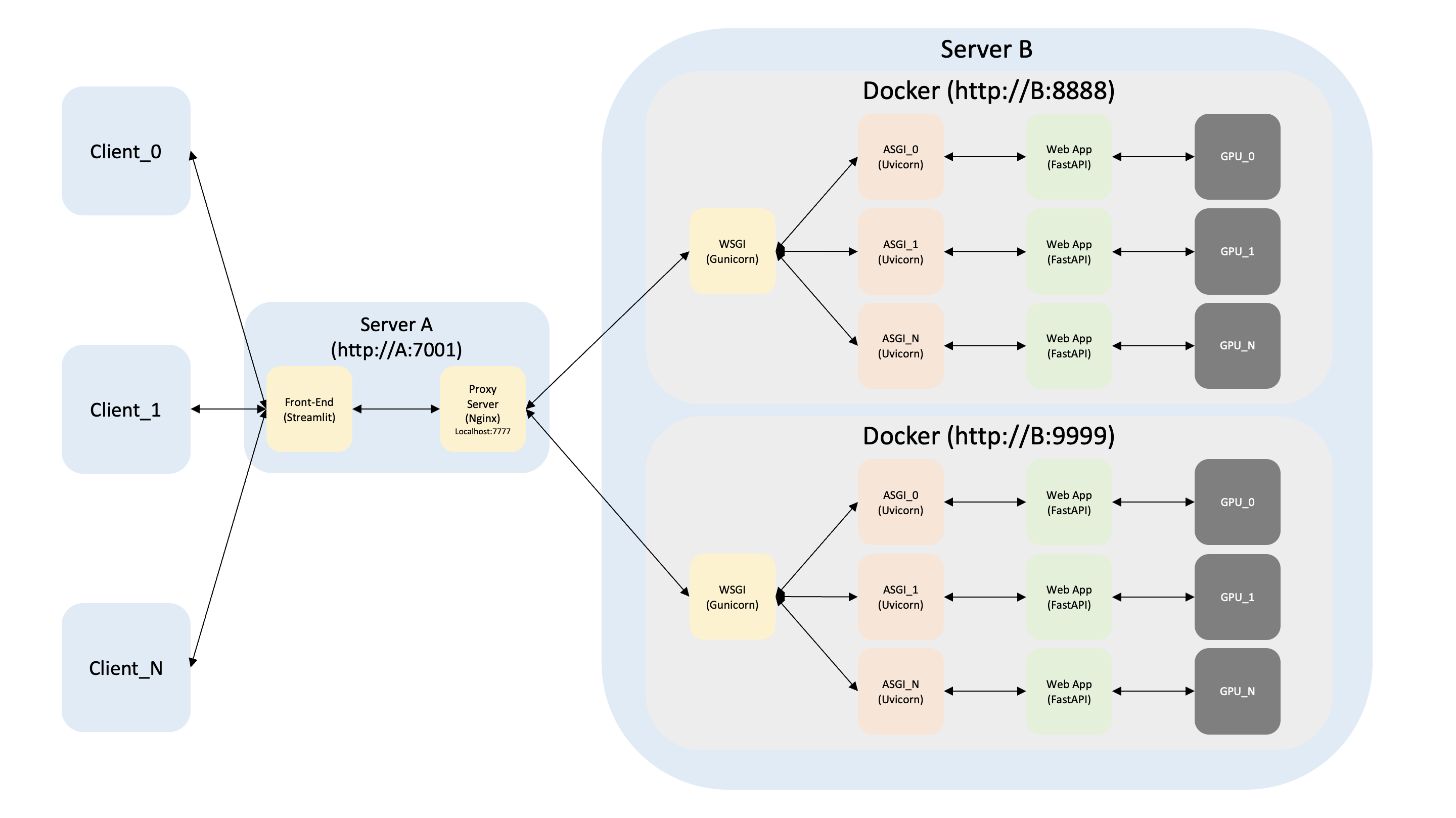
- 현재까지 구축된 서버 A의 프론트 엔드를 만들어 줄 것인데, 테스트이므로 간단하게 Streamlit을 이용하여 만들어 준다.
- Nginx 포트를 7777번으로 변경해 준 후 프론트 엔드 포트를 7001로 다시 설정한다.
2. Nginx 포트 변경
1) default.conf 설정 변경
sudo vim /etc/nginx/conf.d/default.conf
upstream gunicorns {
server 34.64.164.5:8888 max_fails=3 fail_timeout=3s;
server 34.64.164.5:9999 max_fails=3 fail_timeout=3s;
}
server {
listen 7777;
server_name localhost;
location / {
proxy_pass http://gunicorns;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
2) Nginx 재실행
sudo service nginx restart
3. Streamlit
1) Conda 설치 및 초기화
- 현재 서버 A에는 Python이 설치되어 있지 않기 때문에 Anaconda를 설치한 후 진행한다.
cd /tmp
curl -O https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh
bash Anaconda3-2021.05-Linux-x86_64.sh
source ~/.bashrc
2) Streamlit 설치
$(base) conda update conda -y
$(base) pip install streamlit
3) Streamlit 테스트
import streamlit as st
def main():
st.write("Hello World")
if __name__ == "__main__":
main()
$(base) streamlit run streamlit.py --server.port 7001
You can now view your Streamlit app in your browser.
Network URL: http://10.178.0.4:7001
External URL: http://34.64.231.182:7001
- 7001번 포트 접속 시 Streamlit으로 작성된 화면이 확인되며, 필요한 경우
Dockerflie도 만들어 둔다.
4) Nginx + Streamlit
from pydantic import BaseModel
from fastapi import FastAPI
from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
import os, time
import torch
app = FastAPI()
class ModelInference:
def __init__(self, model_name: str):
self.PID = os.getpid()
print(f"PID: {self.PID} / Downloading Model...")
self.model_name = model_name
self.tokenizer = M2M100Tokenizer.from_pretrained(self.model_name)
self.model = M2M100ForConditionalGeneration.from_pretrained(self.model_name)
self.model.to("cuda")
print(f"PID: {self.PID} / Downloaded Model!")
def predict(self, src_lang: str, src_text: str, tgt_lang: str):
self.tokenizer.src_lang = src_lang
encoded_text = self.tokenizer(src_text, return_tensors="pt").to("cuda")
generated_tokens = self.model.generate(
**encoded_text,
forced_bos_token_id=self.tokenizer.get_lang_id(tgt_lang),
num_beams=5,
)
translated = str(
self.tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
).strip("]['")
return translated
model_class = ModelInference("facebook/m2m100_418M")
class Text(BaseModel):
src_lang: str
src_text: str
tgt_lang: str
@app.post("/")
async def main(text: Text):
src_lang = text.src_lang
src_text = text.src_text
tgt_lang = text.tgt_lang
start = time.time()
translated = model_class.predict(src_lang, src_text, tgt_lang)
end = time.time()
print(
f"\nPID: {model_class.PID}\nSrc_Lang: {src_lang} / Src_Text: {src_text}\nTgt_Lang: {tgt_lang} / Translated: {translated}\nTime: {end - start} sec.\n"
)
return {"translated": translated}
- 속도 향상을 위해 쓰레드를 관리하고 싶다면 다음과 같은 코드를 추가하면 된다.
torch.set_grad_enabled(False)
torch.set_num_threads(각워커당쓰레드수)
- FastAPI가 아니라 Flask를 사용해야 하는 경우 다음과 같이 스크립트를 작성하면 된다.
from flask import Flask, request
from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
import os, time
import torch
app = Flask(__name__)
class ModelInference:
def __init__(self, model_name: str):
self.PID = os.getpid()
print(f"PID: {self.PID} / Downloading Model...")
self.model_name = model_name
self.tokenizer = M2M100Tokenizer.from_pretrained(self.model_name)
self.model = M2M100ForConditionalGeneration.from_pretrained(self.model_name)
self.model.to("cuda")
print(f"PID: {self.PID} / Downloaded Model!")
def predict(self, src_lang: str, src_text: str, tgt_lang: str):
self.tokenizer.src_lang = src_lang
encoded_text = self.tokenizer(src_text, return_tensors="pt").to("cuda")
generated_tokens = self.model.generate(
**encoded_text,
forced_bos_token_id=self.tokenizer.get_lang_id(tgt_lang),
num_beams=5,
)
translated = str(
self.tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
).strip("]['")
return translated
model_class = ModelInference("facebook/m2m100_418M")
@app.route("/", methods=["POST"])
def main():
p = request.get_json(force=True)
src_lang = p["src_lang"]
src_text = p["src_text"]
tgt_lang = p["tgt_lang"]
start = time.time()
translated = model_class.predict(src_lang, src_text, tgt_lang)
end = time.time()
print(
f"\nPID: {model_class.PID}\nSrc_Lang: {src_lang} / Src_Text: {src_text}\nTgt_Lang: {tgt_lang} / Translated: {translated}\nTime: {end - start} sec.\n"
)
return {"translated": translated}
if __name__ == "__main__":
app.run(host="0.0.0.0", port="80", debug=True)
- Flask를 사용하는 경우
gunicorn.conf.py를 다음과 같이 수정하여 Uvicorn을 사용하지 않도록 한다.
import multiprocessing
# Python Module:Variable
wsgi_app = "server:app"
# Host:Port
bind = "0.0.0.0:80"
# Worker Class == Sync
worker_class = "sync"
# Num of Workers
# workers = int(multiprocessing.cpu_count() * 0.1)
workers = 3
# Timeout == 0(Deactivate)
timeout = 0
- 이제 Nginx와 통신할 수 있도록
streamlit.py 스크립트를 작성하면 된다.
import json, time
import requests
import streamlit as st
import pandas as pd
from multiprocessing import Process, Queue
from torchtext.data import get_tokenizer
from torchtext.data.metrics import bleu_score
def request_text(
idx: int,
GMT: str,
URL: str,
src_lang: str,
src_text: str,
tgt_lang: str,
result_queue: Queue,
):
data = {"src_lang": src_lang, "src_text": src_text, "tgt_lang": tgt_lang}
response = requests.post(URL, data=json.dumps(data))
result = response.json()["translated"]
print(
f"\nIndex: {idx} / GMT: {GMT}\nSrc_Lang: {src_lang} / Src_Text: {src_text}\nTgt_lang: {tgt_lang} / Translated: {result}\n"
)
result_queue.put((idx, result))
def main():
# st.set_page_config(layout="wide")
URL = "http://127.0.0.1:7777"
lang_codes = {
"Korean": "ko",
"English": "en",
"Chinese": "zh",
"Spanish": "es",
"French": "fr",
"Rusian": "ru",
"Indonesian": "id",
"Japanese": "ja",
"Vietnamese": "vi",
"German": "de",
"Italian": "it",
"Hindi": "hi",
"Arabic": "ar",
"Portuguese": "pt",
}
st.title("Many to Many Translator")
language_option = st.selectbox("Choose a Source Language", list(lang_codes.keys()))
if language_option:
src_text = st.text_area(
"Enter text", value="", height=None, max_chars=None, key=None
)
ref_text = ""
if language_option == "Korean" or language_option == "English":
bleu_button = st.checkbox("Check BLEU Score")
if bleu_button:
ref_text = st.text_area(
"Enter reference:", value="", height=None, max_chars=None, key=None
)
col1, col2, col3, col4, col5 = st.columns(5)
if col5.button("Translate text"):
if src_text == "":
st.write("Please enter text for tanslation")
else:
with st.spinner("Running translation..."):
start = time.time()
src_lang = lang_codes.pop(language_option)
GMT = time.ctime(time.time())
print(f"GMT: {GMT}\nSource Language: {language_option}\n")
result_queue = Queue()
idx_list, translated_list, bleu_list = [], [], []
procs = []
procs = [
Process(
target=request_text,
args=(
idx,
GMT,
URL,
src_lang,
src_text,
lang_code,
result_queue,
),
)
for idx, (lang, lang_code) in enumerate(lang_codes.items())
]
for proc in procs:
proc.start()
for proc in procs:
proc.join()
while not result_queue.empty():
idx, translated = result_queue.get()
idx_list.append(idx)
translated_list.append(translated)
translated_list = list(
pd.DataFrame(
{"idx": idx_list, "Translated": translated_list}
).sort_values(by=["idx"], axis=0)["Translated"]
)
if len(ref_text) > 0:
tokenizer = get_tokenizer("basic_english")
reference_corpus = [[tokenizer(ref_text)]]
translated_corpus = [tokenizer(translated_list[0])]
bleu_list.append(
str(
bleu_score(
translated_corpus,
reference_corpus,
max_n=1,
weights=[1.0],
)
)
)
for _ in range(len(lang_codes.keys()) - 1):
bleu_list.append("")
df = pd.DataFrame(
{
"Language": list(lang_codes.keys()),
"Translated Text": translated_list,
"BLEU Score": bleu_list,
}
)
else:
df = pd.DataFrame(
{
"Language": list(lang_codes.keys()),
"Translated Text": translated_list,
}
)
st.table(df)
end = time.time()
col1, col2, col3, col4, col5 = st.columns(5)
col5.write(f"{end - start:.5f} sec.")
if __name__ == "__main__":
main()
$(base) streamlit run streamlit.py --server.port 7001
- 현재 테스트 서버 A의 public IP는
34.64.231.182이므로 http://34.64.231.182:7001에 접속해 보자.

- 한국어로 두고 "반가워"라고 입력해 보니 다음과 같이 확인된다.
