1. Introduction to MongoDB
1. NoSQL이란?
- NoSQL은 Not Only SQL 즉, SQL뿐만 아니다라는 의미를 지니고 있다.
- 이는 SQL을 사용하는 관계형 데이터베이스 시스템이(RDBMS) 아닌 데이터베이스를 의미한다.
- 대표적인 관계형 데이터베이스로는 MySQL, Oracle, PostgreSQL 등이 있고, NoSQL로는 MongoDB, Redis, HBase 등이 있다.
- NoSQL은 다음과 같이 RDBMS에서는 하기 힘든 작업을 쉽게 지원하는 장점이 있다.
1] 수평 확장 가능한 분산 시스템
2] Schema-less
3] 완화된 ACID
- 또한, RDBMS와 NoSQL을 자세히 비교하면 다음과 같다.
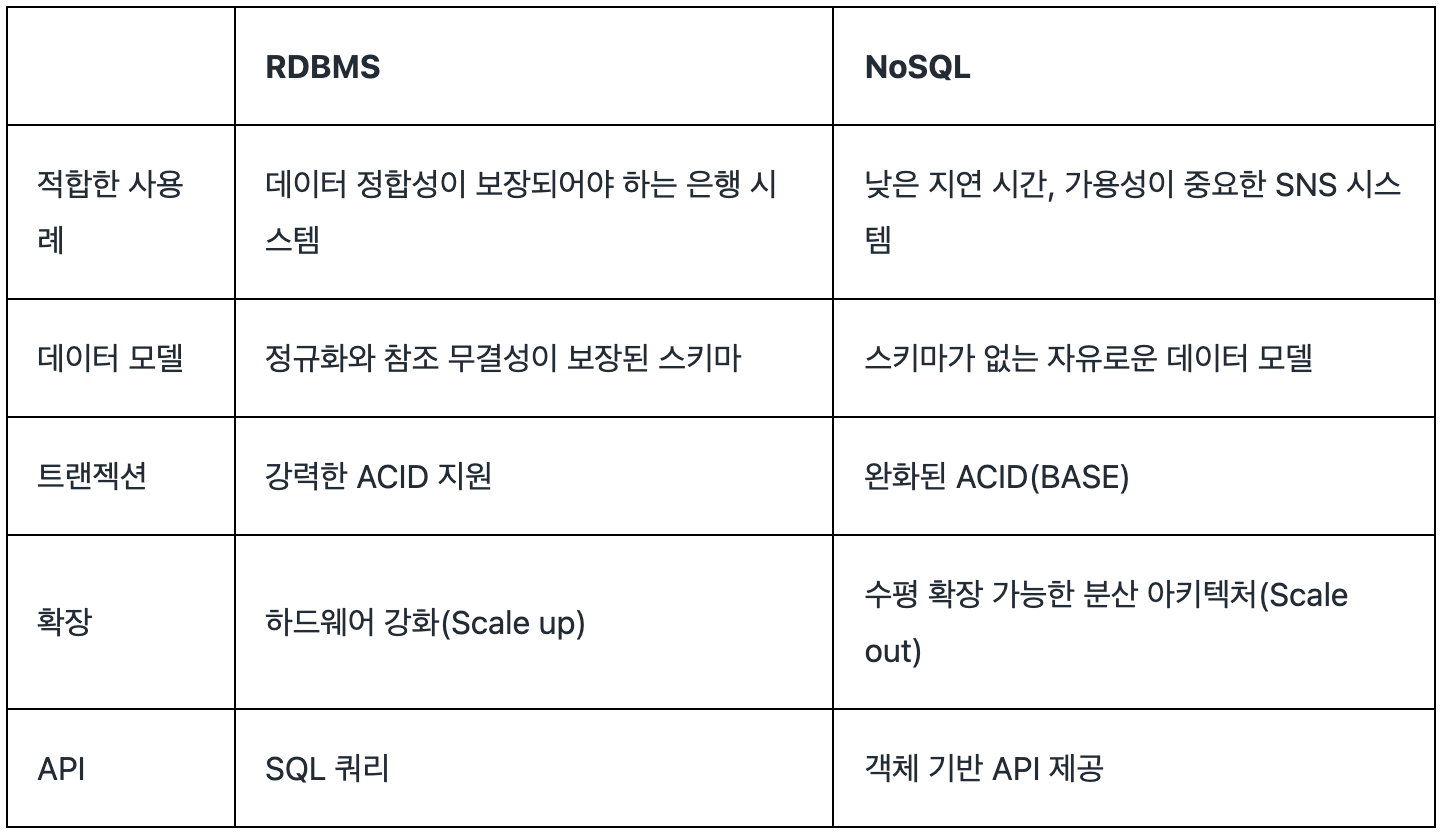
- 물론 MySQL Replication이나 MySQL Cluster가 존재하기 때문에 수평 확장이 불가능한 것은 아니다.
- 또한 NoSQL에서도 ACID가 불가능한 것은 아니다.
2. MongoDB란
- MongoDB는 NoSQL 데이터베이스로 다음과 같은 세 가지 특징을 가지고 있다.
1] Documents
2] BASE
3] Open Source
- 데이터는 Documents 기반으로 구성되어 있고, ACID 대신 BASE를 택하여 성능과 가용성을 우선시한다.
- 그리고 오픈 소스라는 점 덕분에 무료로 이용이 가능하다.
1) Documents
- MongoDB는 Documents 기반 데이터베이스이다.
- Database > Collections > Documents > Fields 계층으로 이루어져 있으며 Documents는 RDBMS의 Rows에 해당한다.
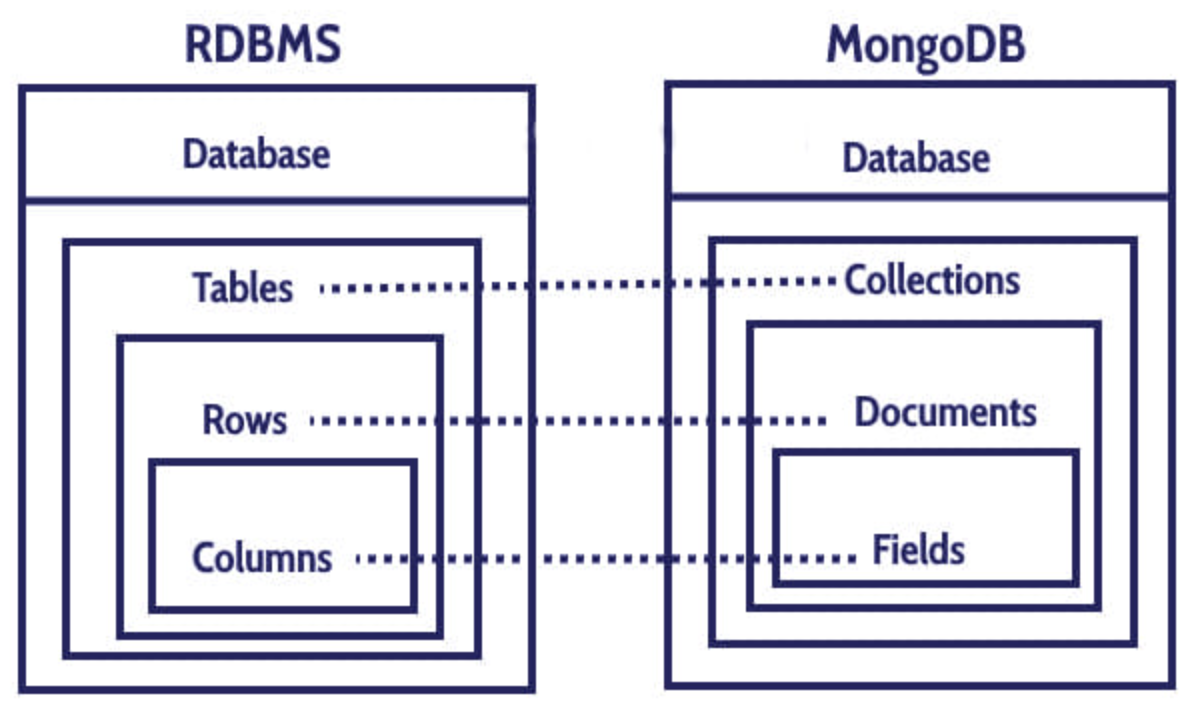
- 이러한 Documents 기반 데이터베이스는 RDBMS와는 다르게 자유롭게 데이터 구조를 잡을 수 있다.
- MongoDB는 JSON(BSON) 형식으로 데이터가 쌓이기 때문에 Array 데이터나 Nested 데이터를 쉽게 넣을 수 있다.
- 위 데이터 구조에서
ObjectID라는 생소한 타입을 볼 수 있다. ObjectID는 RDBMS의 Primary Key와 같이 고유한 키를 의미하는데, 차이점은 Primary Key는 DBMS가 직접 부여한다면ObjectID는 클라이언트에서 생성한다는 것이다.- 이는 MongoDB 클러스터에서 Sharding 된 데이터를 빠르게 가져오기 위함인데 Router(mongos)는
ObjectID를 보고 데이터가 존재하는 Shard에서 데이터를 요청할 수 있다. - 참고로
ObjectID를 넣지 않고 저장한다면 데이터가 그대로 저장된다.

ObjectID는 세 영역으로 나눠져 있다.
1] UNIX Timestamp
4바이트로 UNIX Timestamp 정보를 담고 있다.
2] Random Value
5바이트로 Random Value 정보를 담고 있다.- 첫
3바이트는 클라이언트의 머신별로 고유한 키(MAC 주소나 IP 주소)를 이용하여 랜덤 값을 만들어 사용한다. - 다음
2바이트는 PID를 이용하여 랜덤 값을 만들어 사용한다.
3] Count
- 마지막
3바이트는 Auto Increment 되는 값으로 구성된다.
ObjectID가 서로 충돌하려면 같은 시간, 같은 기기에서 만들어 낸 해시 값이 일치하고, 우연히 같은 PID를 가지고 있으며 정말 우연히 Count가 일치해야 한다.- 즉, 충돌할 가능성이
0에 가깝다는 것이다.
2) BASE
- BASE는 ACID와 대립되는 개념으로 다음과 같이 이루어져 있다.
1] Basically Available
- 기본적으로 언제든지 사용할 수 있다는 의미를 가진다.
- 즉, 가용성이 필요하다는 뜻이다.
2] Soft State
- 외부의 개입이 없어도 정보가 변경될 수 있다는 의미를 가진다.
- 네트워크 파티션 등 문제가 발생되어 일관성(Consistency)이 유지되지 않는 경우 일관성을 위해 데이터를 자동으로 수정한다.
3] Eventually Consistent
- 일시적으로 일관적이지 않은 상태가 되어도 일정 시간 후 일관적인 상태가 되어야 한다는 의미를 가진다.
- 장애 발생 시 일관성을 유지하기 위한 이벤트를 발생시킨다.
- 이처럼 BASE는 ACID와는 다르게 일관성을 어느정도 포기하고 가용성을 우선시한다.
- 즉, 데이터가 조금 맞지 않더라도 일단 내려준다는 뜻이다.
3. MongoDB는 분산 시스템이 핵심
- 웹 서비스가 발전하면서 데이터 무결성을 버리면서까지 더 많은 데이터, 빠른 성능, 수평 확장이 필요한 데이터베이스가 필요해졌다.
1) CAP 이론
- CAP 이론은 어떤 분산 시스템이더라도 일관성(Consistency), 가용성(Availability), 분할 내성(Partition tolerance)를 모두 만족할 수 없다는 이론이다.
(1) 일관성(Consistency)
- 모든 노드가 같은 시간에 같은 데이터를 볼 수 있다는 의미를 지닌다.
- 즉, 데이터가 업데이트된 후 다른 노드에 동기화되어 모든 사용자가 최신 데이터를 본다면 일관성이 있는 시스템이다.
- 이를 위해서는 동기화가 되는 동안 유저는 대기해야 하는데, 대기 시간이 길어질 경우 가용성이 떨어지는 시스템이다.
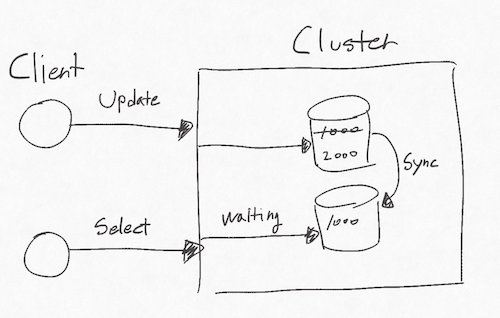
(2) 가용성(Availability)
- 모든 요청에 성공 혹은 실패 결과를 반환할 수 있다는 의미를 지닌다.
- 하나의 노드가 망가져도 다른 노드를 통해 데이터를 제공할 수 있다면 가용성이 있는 시스템이다.
- 만약 다시 노드가 살아났을 때 다른 노드와 데이터가 다르다면 일관성이 떨어지는 시스템이다.
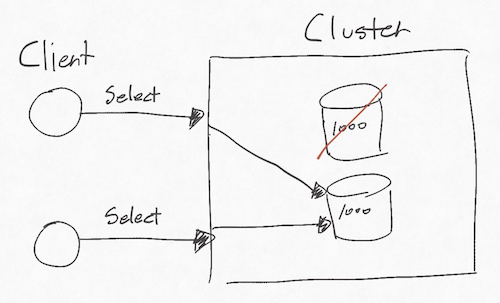
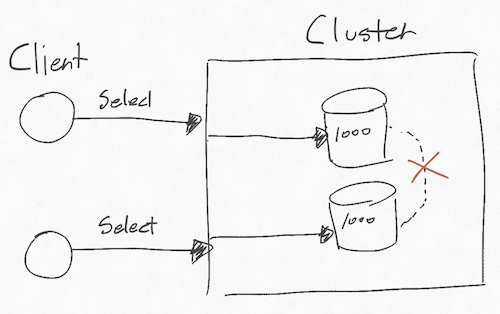
(3) 분할 내성(Partition tolerance)
- 통신에 실패해도 시스템이 계속 동작해야 한다는 의미를 지닌다.
- 노드가 망가진 것이 아닌 노드를 연결시켜 주는 네트워크가 고장나는 경우를 의미한다.
- 둘 사이의 통신이 망가져서 동기화가 불가능해진다면 일관성이 떨어진다.
- 만약 통신이 복구되고 동기화되는 것을 기다린다면 가용성이 떨어진다.
- 즉, 둘 다 만족할 수 없다.
2) CAP 이론의 한계
- CA라는 시스템은 네트워크 장애가 절대 발생하지 않아야 하기 때문에 사실상 불가능하다.
- 따라서 P는 무조건 발생한다고 본 후에 결정해야 한다.
- 그리고 CP, AP 둘 중 하나에 치우쳐진 시스템은 좋지 않다.
- 상황에 따라 유연하게 변하거나 개발자가 원하는 형태로 설정할 수 있는 방식이 가장 이상적이다.
- 그렇기에 대부분의 분산 시스템은 상황에 따라 일관성(C)과 가용성(A)의 우선 순위를 다르게 설정한다.
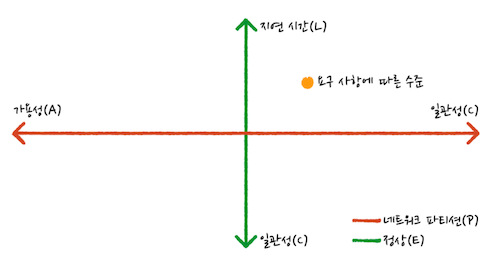
3) PACELC 이론
- 그래서 기본적으로 네트워크 파티션 상황은 반드시 발생한다는 것을 가정하고 그에 따른 선택을 정리한 이론이 PACELC 이론이다.
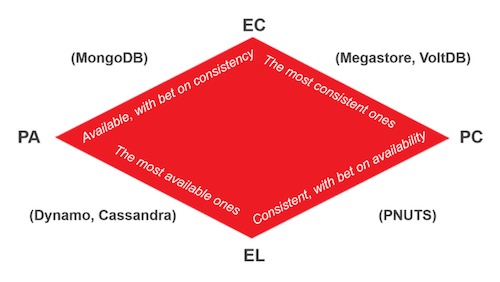
- PACELC는 다음과 같이 이루어져 있다.
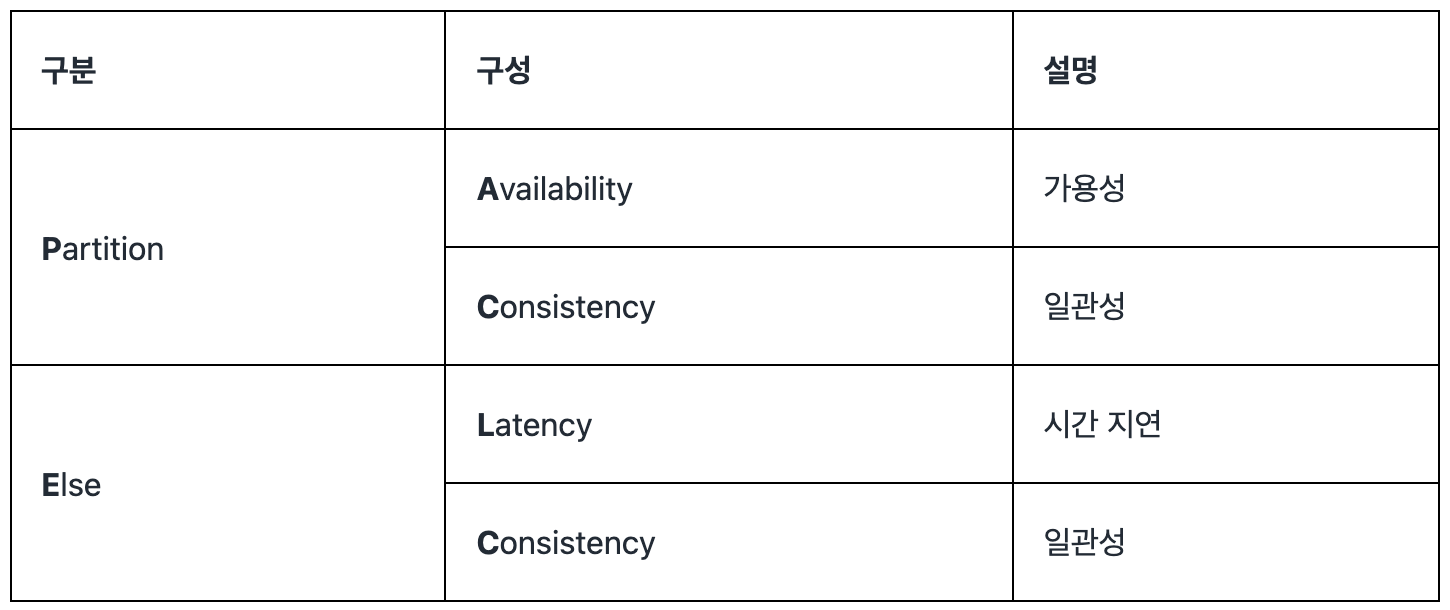
- 여기서
Partition은 네트워크 파티션이 발생한 상태를 의미하고Else는 정상 상태를 의미한다. - 만약
PA / EL시스템이라면 네트워크 파티션 상황일 때 가용성A를 더 우선시하고 평상시에도 지연 시간L을 더 신경쓰므로 가용성A를 우선시한다는 뜻이 된다. - 왜냐하면 일관성
C를 신경쓰느라 지연 시간L이 늦어질수록 가용성A가 떨어지기 때문이다. - 정리하자면 MongoDB는
PA / EC시스템이므로 네트워크 파티션 상황일 때 가용성A를 더 우선시하고 평상시에는 일관성C를 우선시한다.
4) MongoDB Replica Set
- MongoDB는 클러스터를 구성하기 위한 가장 간단한 방법으로 Replica Set을 이용할 수 있다.
- Replica Set은 다음과 같은 두 방법을 이용하여 구성할 수 있다.
1] P-S-S
2] P-S-A
- 이뿐만 아니라 Sharded 클러스터를 구성할 수도 있다.
- 먼저 P-S-S 시스템이다.
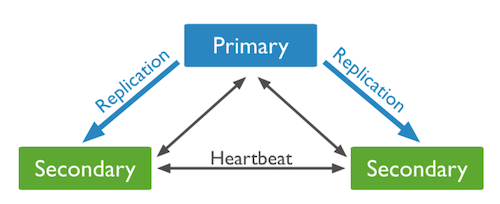
- P-S-S 시스템은 하나의 Primary와 여러 개의 Secondary로 이루어진 Replica Set이다.
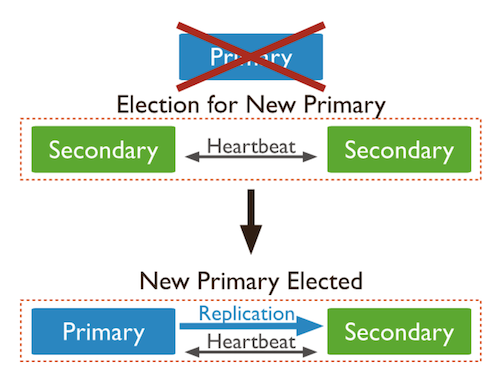
- 만약 Primary가 죽을 경우 투표를 통해 남은 Secondary 중 새로운 Primary를 선출한다.
- 여기서 만약 Secondary가 하나만 남아 있다면 새로운 Primary를 선출할 수 없어서 서버 장애가 발생한다.
- 다음은 P-S-A 시스템이다.
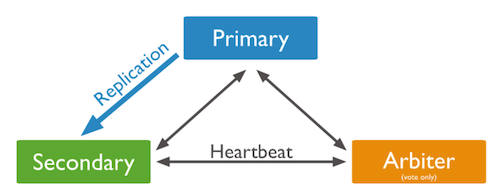
- P-S-A 시스템은 하나의 Primary와 Arbiter 그리고 여러 개의 Secondary로 이루어진 Replica Set이다.
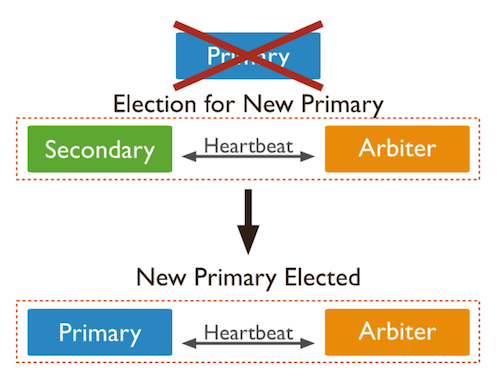
- P-S-A 시스템에서는 Primary가 죽은 경우 Arbiter가 Secondary와 함께 투표해서 Secondary 중 새로운 Primary를 선출한다.
- P-S-A 시스템에서는 Secondary가 하나만 남아 있더라도 Arbiter가 남아 있어서 남은 Secondary를 Primary로 선출할 수 있어서 정상적으로 서비스가 동작한다.
4. MongoDB 패턴
- MongoDB는 Documents라는 방식을 사용하기 때문에 RDBMS와는 다른 방식으로 모델링을 해야 한다.
1) Model Tree Structure
- 같은 Collection에서 데이터가 서로를 참조하는 Tree 구조를 가지고 있을 때 사용할 수 있는 패턴은 다섯 가지가 있다.
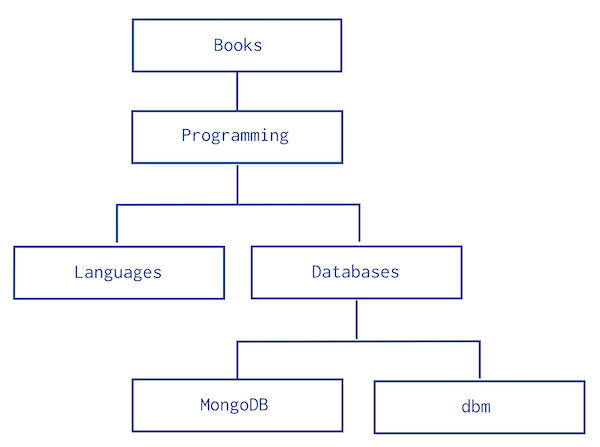
- Parent References는 다음과 같은 구조를 가진다.
[
{ "_id": "MongoDB", "parent": "Databases" },
{ "_id": "dbm", "parent": "Databases" },
{ "_id": "Databases", "parent": "Programming" },
{ "_id": "Languages", "parent": "Programming" },
{ "_id": "Programming", "parent": "Books" },
{ "_id": "Books", "parent": null }
]
- 부모 Document를 바로 찾아야 하는 경우에 적합하다.
- 만약 하위 트리를 모두 찾아야 하는 경우에는 적합하지 않다.
- Child References는 다음과 같은 구조를 가진다.
[
{ "_id": "MongoDB", "children": [] },
{ "_id": "dbm", "children": [] },
{ "_id": "Databases", "children": ["MongoDB", "dbm"] },
{ "_id": "Languages", "children": [] },
{ "_id": "Programming", "children": ["Databases", "Languages"] },
{ "_id": "Books", "children": ["Programming"] }
]
- 자식 Document를 바로 찾아야 하는 경우에 적합하다.
- 부모 Document도 찾을 수 있지만 Parent References보다 탐색 성능이 느리다.
- Array of Ancestors는 다음과 같은 구조를 가진다.
[
{
"_id": "MongoDB",
"ancestors": ["Books", "Programming", "Databases"],
"parent": "Databases"
},
{
"_id": "dbm",
"ancestors": ["Books", "Programming", "Databases"],
"parent": "Databases"
},
{
"_id": "Databases",
"ancestors": ["Books", "Programming"],
"parent": "Programming"
},
{
"_id": "Languages",
"ancestors": ["Books", "Programming"],
"parent": "Programming"
},
{ "_id": "Programming", "ancestors": ["Books"], "parent": "Books" },
{ "_id": "Books", "ancestors": [], "parent": null }
]
- 조상 Document를 바로 알 수 있어야 하는 경우와 자식 Document를 모두 찾아야 하는 경우에 적합하다.
- Breadcrumb 등에 쓸 수 있다.
- 만약 여러 부모 Document를 가진 경우에는 적합하지 않다.
- Materialized Paths는 다음과 같은 구조를 가진다.
[
{ "_id": "Books", "path": null },
{ "_id": "Programming", "path": ",Books," },
{ "_id": "Databases", "path": ",Books,Programming," },
{ "_id": "Languages", "path": ",Books,Programming," },
{ "_id": "MongoDB", "path": ",Books,Programming,Databases," },
{ "_id": "dbm", "path": ",Books,Programming,Databases," }
]
- Array of Ancestors와 유사하다.
- Array 타입이 아닌 String 타입을 이용하는데 정규식을 이용하여 하위 항목을 찾을 수 있다.
- 하위 트리를 찾을 때 Array of Ancestors보다 빠르다.
- 단, 공통 부모를 찾아야 하는 경우에는 더 느려질 수 있다.
- Nested Sets는 조금 특이한 구조를 가진다.
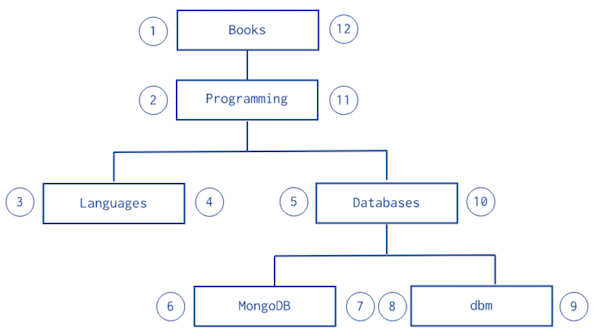
[
{ "_id": "Books", "parent": 0, "left": 1, "right": 12 },
{ "_id": "Programming", "parent": "Books", "left": 2, "right": 11 },
{ "_id": "Languages", "parent": "Programming", "left": 3, "right": 4 },
{ "_id": "Databases", "parent": "Programming", "left": 5, "right": 10 },
{ "_id": "MongoDB", "parent": "Databases", "left": 6, "right": 7 },
{ "_id": "dbm", "parent": "Databases", "left": 8, "right": 9 }
]
- 하위 트리를 찾는데 가장 빠르고 효율적이다.
- 하지만 구조가 변경되는 경우 다시 데이터 번호를 매기는 데 비용이 크기 때문에 데이터가 추가, 삭제, 변경되지 않는 정적인 구조에 적합하다.
2) Model Relationships
- MongoDBeh RDBMS와 마찬가지로
1:1,1:N,N:M구조를 구성할 수 있다. - 참조 방식만 제공하는 RDBMS와 다르게 MongoDB는 참조와 포함 두 가지를 제공한다.
- 참조는 Foreign Key처럼 키를 이용하여 참조하는 것이고 포함은 Document에 Object로 데이터를 포함하는 것을 의미한다.

1:1을 구성한다면 가급적 Sub Document로Embed하는 것이 좋다.- 만약 Document의 크기가 너무 크다면 어쩔 수 없이 분리한다.
1:N은 위 순서도를 참고하여 구성한다.Link를 선택했을 때 자주 쓰이는 데이터가 있다면 후술할 Extended Reference 패턴이나 Subset 패턴을 이용한다.1:N은 다음과 같이 구성할 수 있다.
// 1이 N을 참조하는 방식
// Movie Collection
{
title: 'Star Wars',
reviews: [1, 2, 3]
}
// Review Collection
[
{
_id: 1,
comment: 'Good'
},
{
_id: 2,
comment: 'Good'
},
{
_id: 3,
comment: 'Good'
}
]
// N이 1을 참조하는 방식
// Movie Collection
{
title: 'Star Wars',
}
// Review Collection
[
{
_id: 1,
title: 'Star wars',
comment: 'Good'
},
{
_id: 2,
title: 'Star wars',
comment: 'Good'
},
{
_id: 3,
title: 'Star wars',
comment: 'Good'
}
]
- MongoDB에서
N:M은1:N에서1이N을 참조하는 방식으로 서로 참조하면 구성된다.
3) Modeling Pattern
- MongoDB는 Subquery나 Join과 같은 기능을 제공해 주지 않는다.
- Aggregation을 이용하면 엇비슷하게 사용할 수 있지만 여러 Collection을 참조하게 되면 성능이 크게 느려지기 때문에 권장하지 않는다.
- 이때 최대한 여러 Collection을 참조하는 것을 방지하고 데이터를 단순화하기 위해 Modeling Pattern을 이용할 수 있다.
- Attribute 패턴은 동일한 필드를 묶어서 인덱싱 수를 줄이는 패턴이다.
- 예를 들어 다음과 같이 데이터가 구성되어 있다.
{
title: "Star Wars",
director: "George Lucas",
...
release_US: ISODate("1977-05-20T01:00:00+01:00"),
release_France: ISODate("1977-10-19T01:00:00+01:00"),
release_Italy: ISODate("1977-10-20T01:00:00+01:00"),
release_UK: ISODate("1977-12-27T01:00:00+01:00"),
...
}
- 각국의 개봉 날짜로 검색이 필요한 경우 성능을 위해 인덱스를 걸어줘야 한다.
- 하지만 이런 경우 인덱스가 너무 많아져서 관리가 복잡하고 용량이 증가하게 된다.
- 이를 방지하기 위해 Attribute 패턴을 사용할 수 있다.
{
title: "Star Wars",
director: "George Lucas",
...
releases: [
{
location: "USA",
date: ISODate("1977-05-20T01:00:00+01:00")
},
{
location: "France",
date: ISODate("1977-10-19T01:00:00+01:00")
},
{
location: "Italy",
date: ISODate("1977-10-20T01:00:00+01:00")
},
{
location: "UK",
date: ISODate("1977-12-27T01:00:00+01:00")
},
...
],
...
}
- 단순히 하나의 필드에 묶어서 관리하는 것을 의미한다.
- 이 경우 인덱스를 두 개로 줄일 수 있다.
- Extended Reference 패턴은 서로 관계가 있는 Document에서 자주 사용되는 데이터를 저장해 두는 패턴이다.
- MongoDB에서는 성능을 위해 Join 대신 쿼리를 두 번 날려 연관 데이터를 불러오는 방식을 많이 사용하는데, 데이터가 많아질수록 불리하기 때문에 데이터가 많아지고 자주 참조가 필요할수록 Extended Reference 패턴을 사용해야 한다.

- 위 Collection을 살펴봤을 때, 주문을 하면 Order Collection에 데이터가 쌓이고 어떤 고객이 주문했는지
customer_id필드에 기록된다. - 만약 주문 내역을 사용자에게 보여줄 때 고객 정보도 보여줘야 한다면 Join이 필요해진다.
- MongoDB에서 Join의 성능은 열악하기 때문에 곤란한 상황이 되어버린다.
- 이때 사용할 수 있는 것이 Extended Reference 패턴이다.

- Extende Reference 패턴은 위 그림처럼 필요한 데이터를 연관된 Collection에서 일부분 Document에 저장하는 것을 의미한다.
- Subset 패턴은 관계가 있는 Document 사이에 자주 사용되는 데이터를 부분적으로
Embed하는 패턴이다.

- 상품에 관한 Collection이 있고 해당 Collection에 리뷰를
Embed형태로 저장한다고 가정해 보자. - 이때 리뷰는 엄청 많아질 수 있기 때문에 별도의 Collection으로 분리해야 한다.
- 분리하는 경우 두 번 쿼리를 날려야 한다.
- 만약 빠르게 최신
5개의 리뷰만 보여주고 싶다면 다음과 같이 하면 된다.

- 최신
5개의 리뷰만 상품 Document에 저장해 두면 된다. - 이렇게 하면 빠르게 사용자에게 데이터를 전달할 수 있다.
- 사용자에게는
더 보기메뉴를 누를 수 있도록 UI를 제공하면 된다. - 참고로 만약 데이터 수정이 발생한다면 양쪽을 모두 수정해야 한다.
- Computed 패턴은 미리 통계 수치를 데이터 삽입할 때 계산하는 패턴이다.
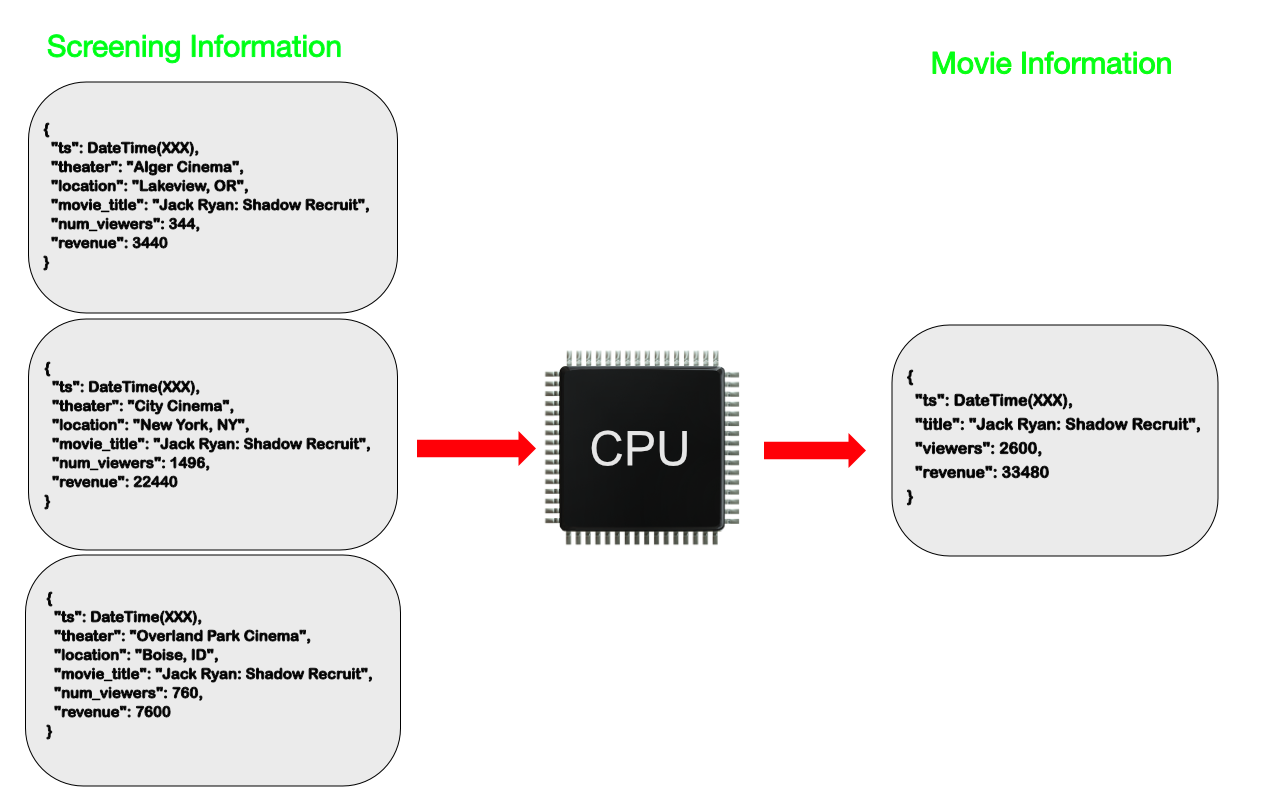
- 위 그림처럼 관객 수 합계가 필요하다면 Read할 때 집계 함수를 사용할 수도 있지만 별도의 필드에 미리 저장해 두는 방법도 있다.
- 집계 함수는 데이터가 많을수록 성능이 느리기 때문에 조금 오차가 발생해도 괜찮다면 Computed 패턴을 쓰는 것이 좋다.
- Bucket 패턴은 하나의 필드를 기준으로 Document를 묶는 패턴이다.
- 실시간으로 데이터가 들어오는 시계열 데이터에 적합하다.
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
}
{
sensor_id: 12345,
timestamp: ISODate("2019-01-31T10:02:00.000Z"),
temperature: 41
}
- 위와 같은 형태로 로그성 데이터를 수집할 때 Computed 패턴을 사용하려면 별도의 Collection에 데이터를 만들어서 저장해야 한다.
- 하지만 Bucket 패턴을 이용하면 쉽게 해결할 수 있다.
{
sensor_id: 12345,
start_date: ISODate("2019-01-31T10:00:00.000Z"),
end_date: ISODate("2019-01-31T10:59:59.000Z"),
measurements: [
{
timestamp: ISODate("2019-01-31T10:00:00.000Z"),
temperature: 40
},
{
timestamp: ISODate("2019-01-31T10:01:00.000Z"),
temperature: 40
},
...
{
timestamp: ISODate("2019-01-31T10:42:00.000Z"),
temperature: 42
}
],
transaction_count: 42,
sum_temperature: 2413
}
- 위 구조를 보면
sensor_id를 기준으로 하나의 Document로 묶은 모습이다. - 이때
transaction_count와sum_temperature필드처럼 집계를 위한 필드도 구성할 수 있다. - 이 경우 필드 추가, 삭제에도 용이하고 인덱스 크기도 절약이 가능하다.
- 단, 조심해야 할 점으로 JSON(BSON) 크기 제한을 벗어나지 않도록 조심해야 하는데, 위 구조처럼
start_date,end_date를 이용하여 기준점을 가지고 묶는 것이 좋다.
- Schema Versioning 패턴은 Document에 버전 정보를 기록하는 패턴인다.
- 서비스를 운영하다 보면 스키마가 변경될 가능성이 높다.
- 이때 Schema Versioning 패턴을 사용하면 기존 데이터를 급하게 마이그레이션 하지 않아도 괜찮다.
{
"_id": "<ObjectId>",
"name": "Darth Vader",
"home": "503-555-0100",
"work": "503-555-0110",
"mobile": "503-555-0120"
}
- 위 데이터의 필드를 변경해야 한다고 가정해 보자.
- 만약 데이터가 10억 개가 넘는다면 마이그레이션을 하는 것도 꽤 큰 작업이 된다.
- 이런 경우 Schema Versioning 패턴을 이용하면 다음과 같이 구성할 수 있다.
{
"_id": "<ObjectId>",
"schema_version": "2",
"name": "Anakin Skywalker (Retired)",
"contact_method": [
{ "work": "503-555-0210" },
{ "mobile": "503-555-0220" },
{ "twitter": "@anakinskywalker" },
{ "skype": "AlwaysWithYou" }
]
}
schema_version필드를 둬서 버전을2로 설정했다.- 이후 애플리케이션에서 Find할 때
schema_version조건을 넣는다면 충돌없이 작업이 가능하다.