2. Android ASR Application with Fine-tuned Wav2Vec2
1. Mission
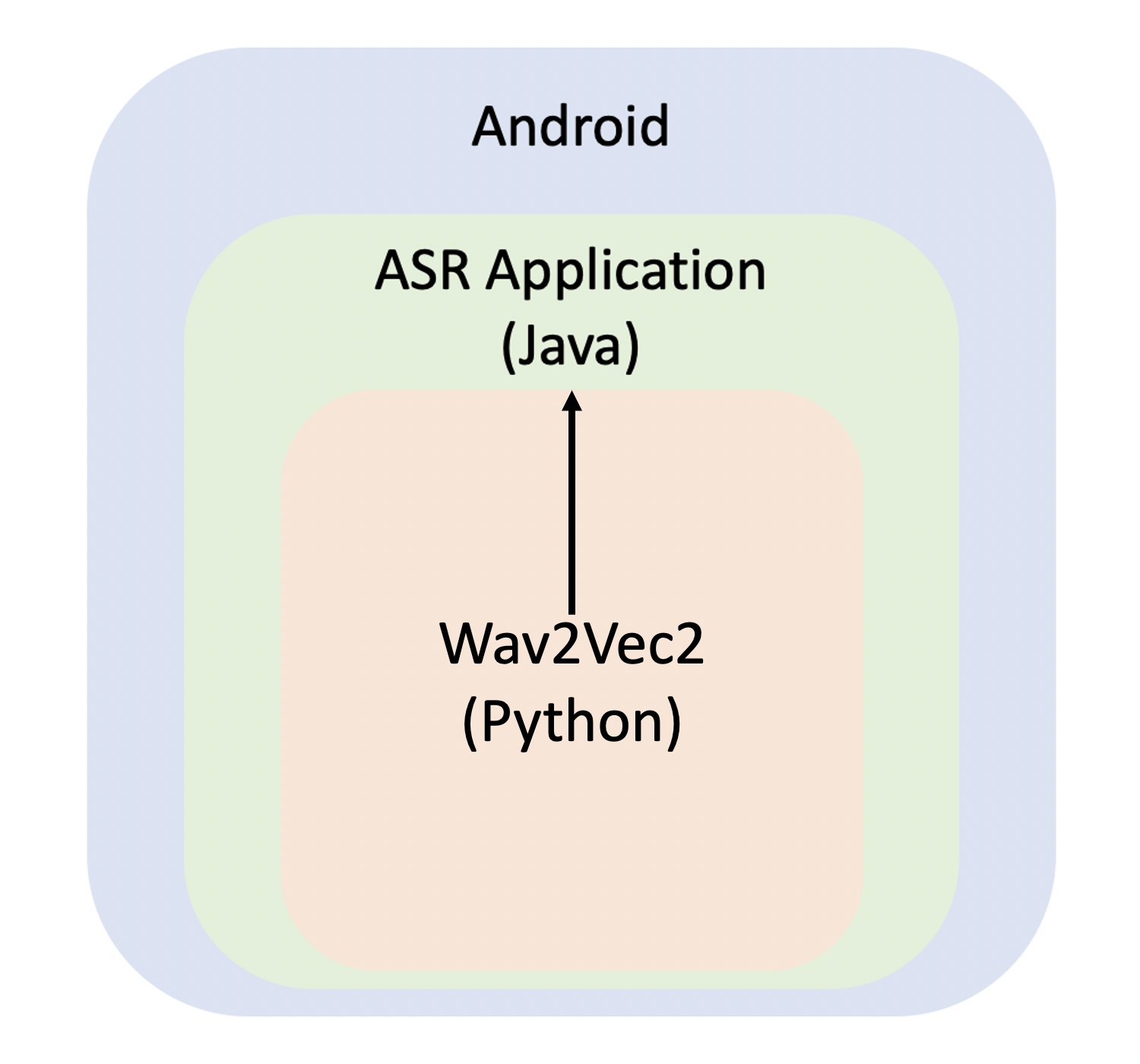
- Android에서 ASR Application 만들기 → Java
- ASR 모델 만들기 → Wav2Vec2 (Python)
- Wav2Vec2 모델을 Java로 변환하여 이식하기
2. Wav2Vec2
1) Wav2Vec2란
- Wav2Vec2는 ASR(Automatic Speech Recognition)을 위해 사전 훈련된(pre-trained) 모델
- 레이블이 지정되지 않은(unlabeled) 50,000시간 이상의 음성에서 음성 표현을 학습힌다.
- BERT의 마스킹된(masked) 언어 모델링과 유사하게 이 모델은 feature 벡터를 무작위로 마스킹하여 상황에 맞는 음성 표현을 학습한다.

- Wav2Vec2는 레이블이 지정된(labeled) 데이터를 10분 정도 사용하여 LibriSpeech의 깨끗한 테스트 세트에서 5% 미만의 단어 오류율(WER: Word Error Rate)을 달성했다.
- end-to-end 언어 모델 없이 Wav2Vec2를 사용하는 것이 훨씬 간단하다.
- Wav2Vec2는 sequence-to-sequence 문제와 ASR 및 필기 인식(Handwriting Recognition)에서 신경망을 훈련하는 데 사용되는 알고리즘인 CTC(Connectionist Temporal Classification)를 사용하여 미세 조정(fine-tuned)된다.
3. Fine-tuned Wav2Vec2 구현
1) Python 라이브러리
$(base) conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch -y
$(base) conda install -c huggingface transformers -y
$(base) pip install datasets soundfile jiwer
2) Create Wav2Vec2CTCTokenizer
- ASR 모델은 음성을 텍스트로 변환하기 때문에, 음성 신호를 모델의 입력 형식으로 처리하는 feature 추출기(extractor)와 텍스트를 모델의 출력 형식으로 처리하는 토크나이저(tokenizer)가 필요하다.
- Transformers에서, Wav2Vec2 모델에는
Wav2Vec2CTCTokenizer라는 토크나이저와Wav2Vec2FeatureExtractor라는 feature 추출기가 함께 제공된다. - 먼저, 모델의 예측을 디코딩하는 토크나이저를 생성해 보자.
DatasetDict({
train: Dataset({
features: ['file', 'text', 'phonetic_detail', 'word_detail', 'dialect_region', 'sentence_type', 'speaker_id', 'id'],
num_rows: 4620
})
test: Dataset({
features: ['file', 'text', 'phonetic_detail', 'word_detail', 'dialect_region', 'sentence_type', 'speaker_id', 'id'],
num_rows: 1680
})
})
- 많은 ASR 데이터세트는 각 오디오 파일인
file에 대한 target 텍스트text만 제공한다. - Timit은
phonetic_detail등과 같이 각 오디오 파일에 대한 더 많은 정보를 제공한다. - 하지만 현재 테스트에서는 필요한 정보만 사용할 것이므로 다음과 같이 불필요한 정보는 제거한다.
Code
timit = timit.remove_columns(
[
"phonetic_detail",
"word_detail",
"dialect_region",
"id",
"sentence_type",
"speaker_id",
]
)
- 간략하게 테스트 코드를 작성하여 실행해 보자.
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(timit["train"].remove_columns(["file"]))
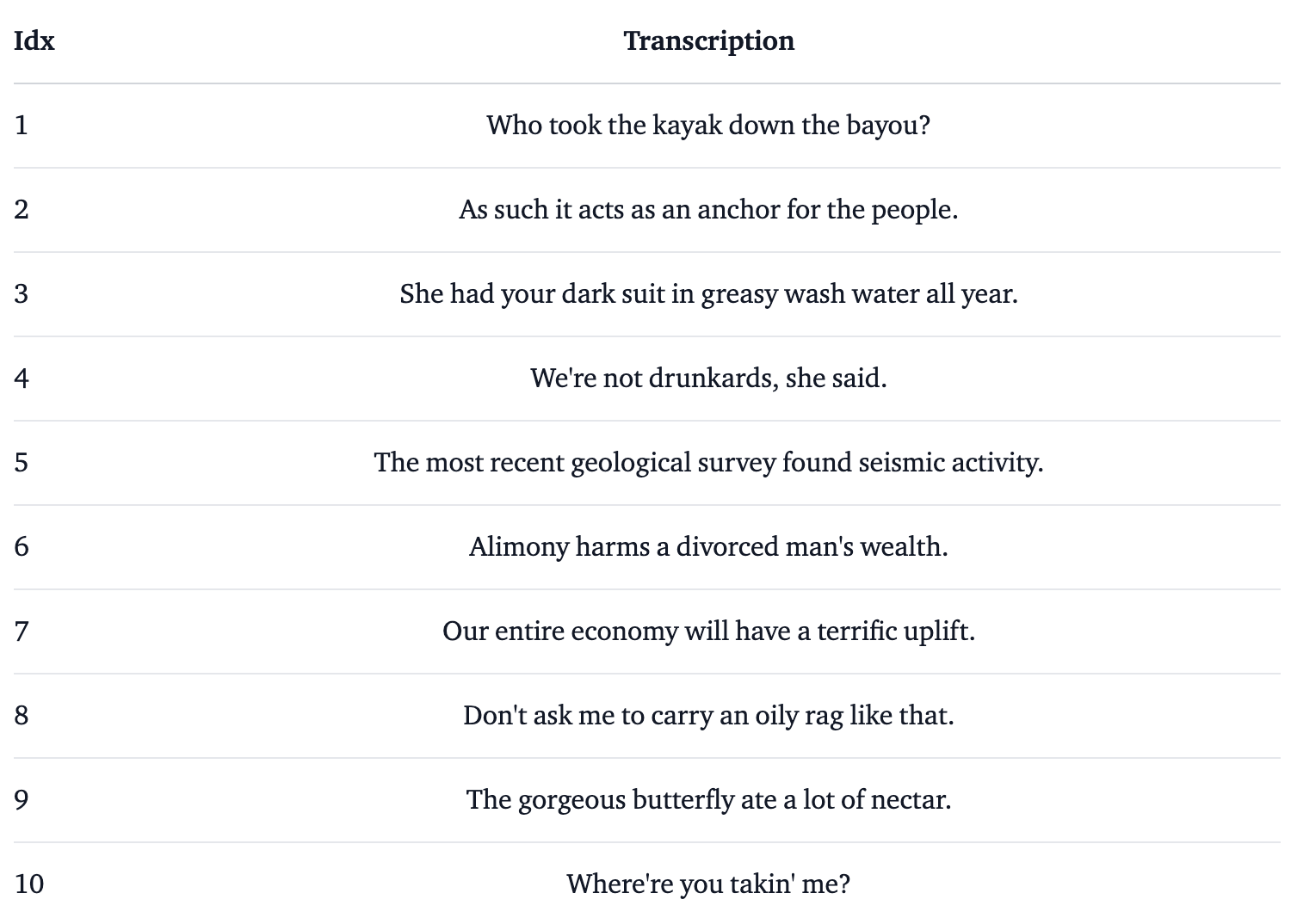
- 전사(transcriptions)에서 대부분의 특수 문자를 제거하고 소문자로만 정규화했다.
- CTC에서는 음성 청크(chunks)를 문자로 분류하는 것이 일반적이므로 여기에서도 동일한 작업을 수행한다.
- 훈련 및 테스트 데이터의 모든 고유한 문자를 추출하고 이 문자 집합에서 vocabulary를 구축해 보자.
- 모든 전사를 하나의 긴 전사로 연결한 다음 문자열을 문자 집합으로 변환하는 매핑 함수를 작성한다.
- 매핑 함수가 한 번에 모든 전사에 액세스할 수 있도록
batched=True인수를map()함수에 전달하는 것이 중요하다.
Code
def extract_all_chars(batch):
all_text = " ".join(batch["text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = timit.map(
extract_all_chars,
batched=True,
batch_size=-1,
keep_in_memory=True,
remove_columns=timit.column_names["train"],
)
- 이제 훈련 데이터세트와 테스트 데이터세트에 있는 모든 개별 문자의 합집합을 만들고, 결과 목록을 enumerated dictionary로 변환한다.
- 모든 알파벳,
`(공백)과'`(따옴표)와 같은 특수 문자를 추출했다. `에 고유한 토큰 클래스가 있다는 것을 더 명확하게 하기 위해 더 눈에 잘 띄는 문자|`(파이프)를 제공한다.
- 또한 모델이 나중에 Timit의 훈련 세트에서 만나지 못한 문자를 처리할 수 있도록
unknown토큰도 추가한다. - 마지막으로 CTC의 빈 토큰에 해당하는 패딩 토큰도 추가한다.
- 빈 토큰은 CTC 알고리즘의 핵심 구성 요소이다.
- 이것으로 vocabulary는 30개의 토큰으로 구성된다.
- 이는 사전 훈련된 Wav2Vec2 체크포인트 위에 추가할 선형 레이어의 출력 차원이 30임을 의미한다.
- 이제 vocabulary를 JSON 파일로 저장해 보자.
- 참고로 Transformers에 대해 알아보면서 아키텍처(Architectures)와 체크포인트(Checkpoints), 모델(Models)에 대해 계속 접할 것이다.
- 이러한 용어들은 모두 다음과 같이 다른 의미를 가진다.
1] Architectures
- 모델의 뼈대를 의미하며, 각 레이어와 모델 내에서 발생하는 작업에 대한 정의이다.
2] Checkpoints
- 주어진 아키텍처에서 로드될 가중치를 의미한다.
3] Models
- 아키텍처와 체크포인트 모두를 의미하는 포괄적인 용어이다.
- 예를 들어, 'BERT'는 아키텍처인 반면, Google 팀에서 훈련한 가중치 세트인 'bert-base-cased'는 체크포인트이다.
- 하지만 포괄적으로 'BERT 모델'과 'bert-base-cased 모델'이라고도 할 수 있다.
- 마지막 단계에서, 이 JSON 파일을 사용하여
Wav2Vec2CTCTokenizer클래스의 객체를 인스턴스화한다.
Code
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer(
"./vocab.json", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|"
)
- 여기까지 완료되었으면, feature 추출기를 생성해 보자.
3) Create Wav2Vec Feature Extractor
- 음성은 연속적인(continuous) 신호이기 때문에 이를 컴퓨터에서 처리하려면 먼저 이산화되어야(discretized) 하는데, 이를 일반적으로 샘플링(sampling)이라고 한다.
- 샘플링 레이트(sampling rate)는 초당 측정되는 음성 신호의 데이터 포인트 수를 정의한다는 점에서 중요한 역할을 한다.
- 따라서 더 높은 샘플링 레이트로 샘플링을 하면 실제 음성 신호에 대한 근사치가 향상되지만 처리해야 하는 더 많은 값이 필요하다.
- 사전 훈련된 체크포인트는 입력 데이터가 훈련된 데이터와 동일한 분포에서 어느 정도 샘플링될 것으로 예상한다.
- 하지만 두 가지 다른 속도로 샘플링된 동일한 음성 신호는 매우 다른 분포를 갖는다.
- 예를 들어, 샘플링 속도를 두 배로 늘리면 데이터 포인트가 두 배 길어진다.
- 따라서 ASR 모델의 사전 학습된 체크포인트를 미세 조정하기 전에, 모델을 사전 학습하는 데 사용된 데이터의 샘플링 속도가 모델을 미세 조정하는 데 사용된 데이터세트의 샘플링 속도와 일치하는지 확인하는 것이 중요하다.
- Wav2Vec2는 16kHz로 샘플링된 LibriSpeech 및 LibriVox의 오디오 데이터에 대해 사전 학습되었다.
- 미세 조정 데이터세트인 Timit도 우연하게 16kHz로 샘플링되었다.
- 만약 미세 조정 데이터세트가 16kHz보다 낮거나 높은 경우, 사전 훈련에 사용된 데이터의 샘플링 속도와 일치하도록 음성 신호를 업샘플링하거나 다운샘플링해야 한다.
- Wav2Vec2 feature 추출기 객체를 인스턴스화하려면 다음과 같은 매개변수가 필요하다.
1] feature_size
- 음성 모델은 feature 벡터의 시퀀스를 입력으로 사용한다.
- 이 시퀀스의 길이는 다양하겠지만, feature 사이즈는 그렇지 않아야 한다.
- Wav2Vec2의 경우 feature 사이즈는 1이다.
2] sampling_rate
- 모델이 학습되는 샘플링 속도이다.
3] padding_value
- 배치 추론의 경우 더 짧은 입력을 특정 값으로 채워야 한다.
4] do_normalize
- 입력이 zero-mean-unit-variance 정규화되어야 하는지 여부이다.
- 일반적으로 음성 모델은 입력을 정규화할 때 더 잘 수행된다.
5] return_attention_mask
- 모델이 배치 추론을 위해
attention_mask를 사용해야 하는지 여부이다. - 일반적으로 모델은 패딩된 토큰을 마스크하기 위해 항상
attention_mask를 사용해야 한다. - 그러나 Wav2Vec2의 경우
attention_mask를 사용하지 않을 때 더 나은 결과를 얻을 수도 있다.
Code
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor(
feature_size=1,
sampling_rate=16000,
padding_value=0.0,
do_normalize=True,
return_attention_mask=False,
)
- 이제 Wav2Vec2의 feature 추출 파이프라인이 정의되었다.
- Wav2Vec2를 사용자 친화적으로 사용하기 위해서는 feature 추출기와 토크나이저를 단일
Wav2Vec2Processor클래스로 래핑한다.
Code
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
- 이제 데이터세트를 준비해 보자.
4) Preprocess Data
- Wave2Vec2.0은 1차원 배열 형식의 오디오 파일을 예상한다.
- 그러므로 모든 오디오 파일을 데이터세트 객체에 로드해 보자.
- 먼저, 다운로드한 오디오 파일의 직렬화 형식을 확인한다.
- 오디오 파일은
.WAV형식으로 저장된다. librosa,soundfile및audioread와 같은 오디오 파일을 읽고 처리하는 몇 가지 Python 라이브러리가 있다.- 오디오 파일은 일반적으로 해당 값과 음성 신호가 디지털화된 샘플링 속도를 모두 저장한다.
- 데이터세트에 둘 다 저장하고 그에 따라
map()함수를 작성한다.
Code
import soundfile as sf
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = sf.read(batch["file"])
batch["speech"] = speech_array
batch["sampling_rate"] = sampling_rate
batch["target_text"] = batch["text"]
return batch
timit = timit.map(
speech_file_to_array_fn, remove_columns=timit.column_names["train"], num_proc=4
)
- 오디오가 올바르게 로드되었는지 확인하기 위해 몇 가지 오디오 파일을 들어보자.
Code
import IPython.display as ipd
import numpy as np
import random
rand_int = random.randint(0, len(timit["train"]))
ipd.Audio(
data=np.asarray(timit["train"][rand_int]["speech"]), autoplay=True, rate=16000
)
- 전반적으로 녹음된 오디오는 비교적 명확하게 들린다.
- 음성 입력의 모양, 전사 및 해당 샘플링 속도를 출력해 보자.
- 데이터는 1차원 배열이고, 샘플링 속도는 16kHz이며 target 텍스트는 정규화된다.
- 마지막으로, 훈련을 위해 모델이 예상하는 형식으로 데이터세트를 처리할 수 있다.
map()함수를 다시 사용한다.- 먼저, 모든 데이터 샘플이 동일한 샘플링 속도(16kHz)를 가지는지 확인한다.
- 두 번째, 로드된 오디오 파일에서
input_values를 추출한다. - 세 번째,
id에 레이블을 지정하기 위해 전사를 인코딩한다.
Code
def prepare_dataset(batch):
# check that all files have the correct sampling rate
assert (
len(set(batch["sampling_rate"])) == 1
), f"Make sure all inputs have the same sampling rate of {processor.feature_extractor.sampling_rate}."
batch["input_values"] = processor(
batch["speech"], sampling_rate=batch["sampling_rate"][0]
).input_values
with processor.as_target_processor():
batch["labels"] = processor(batch["target_text"]).input_ids
return batch
timit_prepared = timit.map(
prepare_dataset,
remove_columns=timit.column_names["train"],
batch_size=8,
num_proc=4,
batched=True,
)
5) Training & Evaluation
- 학습 파이프라인을 설정할 수 있도록 다음과 같이 준비되어야 한다.
1] 데이터 수집기(Data Collator)
- 대부분의 NLP 모델과 달리 Wav2Vec2는 출력 길이보다 입력 길이가 훨씬 더 크다.
- 예를 들어, 입력 길이가 50,000인 샘플의 출력 길이는 100 이하가 된다.
- 입력 크기가 큰 경우 훈련 배치를 동적으로 할당하는 것이 훨씬 효율적이다.
- 따라서 Wav2Vec2를 미세 조정하려면 특별한 패딩 데이터 수집기가 필요하다.
2] 평가 지표(Evaluation Metric)
- 모델은 훈련하는 동안 WER로 평가되어야 하며, 이에 따라
compute_metrics함수를 정의해야 한다.
3] 사전 훈련된 체크포인트(Pre-trained Checkpoint)
- 사전 훈련된 체크포인트를 로드하고 훈련을 위해 올바르게 구성해야 한다.
4] 훈련 구성(Training Configuration)
6) Set-up Trainer
- 먼저, 데이터 수집기를 정의하는 것부터 시작해 보자.
- 일반적인 데이터 수집기와 달리 이 데이터 수집기는
input_values및labels를 다르게 처리하므로 별도의 패딩 함수를 적용한다. - 이는 음성에서 입력과 출력이 동일한 패딩 함수로 처리되어서는 안 되기 때문이다.
- 일반적인 데이터 수집기와 유사하게 레이블의 토큰을
-100으로 채워 손실을 계산할 때 해당 토큰이 고려되지 않도록 한다.
Code
import torch
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
max_length (:obj:`int`, `optional`):
Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
max_length_labels (:obj:`int`, `optional`):
Maximum length of the ``labels`` returned list and optionally padding length (see above).
pad_to_multiple_of (:obj:`int`, `optional`):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volta).
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
max_length: Optional[int] = None
max_length_labels: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
pad_to_multiple_of_labels: Optional[int] = None
def __call__(
self, features: List[Dict[str, Union[List[int], torch.Tensor]]]
) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lenghts and need
# different padding methods
input_features = [
{"input_values": feature["input_values"]} for feature in features
]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
with self.processor.as_target_processor():
labels_batch = self.processor.pad(
label_features,
padding=self.padding,
max_length=self.max_length_labels,
pad_to_multiple_of=self.pad_to_multiple_of_labels,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(
labels_batch.attention_mask.ne(1), -100
)
batch["labels"] = labels
return batch
- 데이터 수집기를 초기화한다.
- 이제 평가 지표를 정의한다.
- 앞서 언급했듯이, ASR의 주요 지표는 WER이다.
- 모델의 가장 가능성 있는 예측에 관심이 있으므로 로짓의
argmax()를 취한다. - 또한,
-100을pad_token_id로 바꾼다. - 그리고 id를 디코딩하여 인코딩된 레이블을 원래 문자열로 다시 변환하는 동시에 연속적인 토큰이 CTC 스타일의 동일한 토큰으로 그룹화되지 않도록 한다.
Code
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
- 이제 사전 훈련된 Wav2Vec2 체크포인트를 로드할 수 있다.
- 토크나이저의
pad_token_id는 모델의pad_token_id를 정의하거나Wav2Vec2ForCTC의 경우 CTC의 빈 토큰이어야 한다. - GPU 메모리를 절약하기 위해 PyTorch의 그래디언트 체크포인트를 활성화하고 손실 감소를 "mean"으로 설정한다.
- Wav2Vec2의 첫 번째 구성 요소는 원시 음성 신호에서 음향적으로 의미 있지만 맥락적으로는 독립적인 특징을 추출하는 데 사용되는 CNN 레이어 스택으로 구성된다.
- 모델의 이 부분은 사전 훈련 중에 이미 충분히 훈련되어 있기 때문에 더 이상 미세 조정할 필요가 없다.
- 따라서 특성 추출 부분의 모든 매개변수에 대해
requires_grad를False로 설정할 수 있다.
- 마지막 단계에서는 훈련과 관련된 모든 매개변수를 정의한다.
- 일부 매개변수에 대한 설명은 다음과 같다.
1] group_by_length
- 유사한 입력 길이의 훈련 샘플을 하나의 배치로 그룹화하여 훈련을 보다 효율적으로 만든다.
- 이는 모델을 통해 전달되는 쓸모없는 패딩 토큰의 전체 수를 줄여 학습 시간을 크게 단축할 수 있다.
2] learning_rate 및 weight_decay
- 미세 조정이 안정될 때까지 경험적으로 조정된다.
- 이러한 매개변수는 Timit 데이터세트에 크게 의존한다.
Code
from transformers import TrainingArguments
training_args = TrainingArguments(
# output_dir="/content/gdrive/MyDrive/wav2vec2-base-timit-demo",
output_dir="./wav2vec2-base-timit-demo",
group_by_length=True,
per_device_train_batch_size=32,
evaluation_strategy="steps",
num_train_epochs=30,
fp16=True,
save_steps=500,
eval_steps=500,
logging_steps=500,
learning_rate=1e-4,
weight_decay=0.005,
warmup_steps=1000,
save_total_limit=2,
)
- 이제 모든 인스턴스를 Trainer에 전달할 수 있으며, 학습을 시작할 준비가 다 되었다.
Code
from transformers import Trainer
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=timit_prepared["train"],
eval_dataset=timit_prepared["test"],
tokenizer=processor.feature_extractor,
)
- 모델이 화자 비율(speark rate)과 독립적이기 위해 CTC에서는 동일한 연속 토큰을 단일 토큰으로 그룹화한다.
- 그러나 인코딩된 레이블은 모델의 예측 토큰과 일치하지 않으므로 디코딩 시 그룹화하지 않아야 하며, 이것이
group_tokens=False매개변수를 전달해야 하는 이유이다. - 이 매개변수를 전달하지 않으면
hello와 같은 단어가 잘못 인코딩되고helo로 디코딩된다. - 빈 토큰을 사용하면 모델이 두 개의
l사이에 빈 토큰을 삽입하도록 하여hello와 같은 단어를 예측할 수 있다. - 우리 모델의
hello에 대한 CTC-conform 예측은[PAD] [PAD] h e e l l [PAD] l o o [PAD]이다.
7) Training
- Google Colab에 할당된 GPU를 사용할 시 90~180분이 소요된다.
- 훈련된 모델은 Timit의 테스트 데이터에서 만족스러운 결과를 산출하지만 최적으로 미세 조정된 모델은 아니다.
- 구현의 목적은 모든 영어 데이터세트에서 Wav2Vec2의
base,large및large-lv60체크포인트를 미세 조정할 수 있는 방법을 보여주는 것이다. - Google Colab을 사용하여 모델을 미세 조정하려는 경우 비활성으로 인해 학습이 중지되지 않는지 확인해야 한다.
- 이를 방지하기 위해 다음과 같은 코드를 [검사] → [콘솔 탭 및 코드 삽입]에 붙여넣은 후 훈련을 실시한다.

- 최종 WER은 0.3 미만이어야 한다.
8) Evaluate
- 마지막 부분에서는 테스트 세트에서 미세 조정된 모델을 평가한다.
- 프로세서와 모델을 로드한다.
Code
processor = Wav2Vec2Processor.from_pretrained(
"patrickvonplaten/wav2vec2-base-timit-demo"
)
model = Wav2Vec2ForCTC.from_pretrained("patrickvonplaten/wav2vec2-base-timit-demo")
- 이제
map()함수를 사용하여 모든 테스트 샘플의 전사를 예측하고, 데이터 세트 자체에 예측을 저장한다.
Code
def map_to_result(batch):
model.to("cuda")
input_values = processor(
batch["speech"], sampling_rate=batch["sampling_rate"], return_tensors="pt"
).input_values.to("cuda")
with torch.no_grad():
logits = model(input_values).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_str"] = processor.batch_decode(pred_ids)[0]
return batch
results = timit["test"].map(map_to_result)
- 이제 전체 WER을 계산해 보자.
- 18.6% WER이면 나쁘지 않다.
- 모델에서 어떤 오류가 발생했는지 보기 위해 몇 가지 예측 결과를 살펴보자.

- 예측된 전사가 target 전사와 음향적으로 매우 유사하지만 종종 철자 또는 문법 오류가 포함되어 있다.
- 우리가 언어 모델을 사용하지 않고 순수하게 Wav2Vec2에 의존했기 때문이다.
- 마지막으로 CTC의 작동 방식을 더 잘 이해하려면 모델의 정확한 출력을 자세히 살펴보는 것이 좋다.
- 모델을 통해 첫 번째 테스트 샘플을 실행하고 예측된 id를 가져와 해당 토큰으로 변환해 보자.
model.to("cuda")
input_values = processor(
timit["test"][0]["speech"],
sampling_rate=timit["test"][0]["sampling_rate"],
return_tensors="pt",
).input_values.to("cuda")
with torch.no_grad():
logits = model(input_values).logits
pred_ids = torch.argmax(logits, dim=-1)
# convert ids to tokens
print(" ".join(processor.tokenizer.convert_ids_to_tokens(pred_ids[0].tolist())))
[PAD] [PAD] [PAD] [PAD] [PAD] [PAD] t t h e e | | b b [PAD] u u n n n g g [PAD] a [PAD] [PAD] l l [PAD] o o o [PAD] | w w a a [PAD] s s | | [PAD] [PAD] p l l e e [PAD] [PAD] s s e n n t t t [PAD] l l y y | | | s s [PAD] i i [PAD] t t t [PAD] u u u u [PAD] [PAD] [PAD] a a [PAD] t t e e e d d d | n n e e a a a r | | t h h e | | s s h h h [PAD] o o o [PAD] o o r r [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
- 출력을 보면 CTC가 실제로 어떻게 작동하는지 확인할 수 있다.
4. Android ASR Application 구현
- 링크를 따라 실행시키면 된다.
https://github.com/pytorch/android-demo-app/tree/master/SpeechRecognition