3. Post Processing
Info
음성 인식 결과를 후처리해 좀 더 읽기 좋은 텍스트를 만드는 과정을 살펴본다.
1. Motivation
성능이 좋은 음성 인식기를 만드는 것만큼 후처리(post processing) 역시 중요하다. 그림1의 첫 번째 표가 음성 인식 결과인데, 문장이 어디까지 이어지고 있는지 알기 어렵고 말 소리와는 직접 관련 없는 단어(um 등)까지 끼어 있다. 후처리의 목적은 그림1의 두 번째 표처럼 읽기 편한 텍스트로 변환하고자 하는 데 있다.
그림1 POST PROCESSING MOTIVATION
2. Tasks
후처리에는 다양한 세부 과제들이 있다. 차례대로 살펴보자. 아래 세부 과제들이 만들어 내는 정보 내지 결과를 meta-data 혹은 rich transcription이라고 부른다.
1] Diarization: 화자 레이블을 다는 작업이다. 그림1에서 A:, B:를 표시해줘 복수의 화자가 대화하고 있음을 알린다.
2] Sentence segmentation: 문장을 분리하는 작업이다. 음성 인식 결과는 텍스트와 달리 문장부호(punctuation)가 없고 실수로 말하는 단어가 많아서 생각보다 어려울 수 있다. 음성 멈춤이나 문장 끝 억양(intonation) 등 특성으로 문장 경계를 나누는 모델을 별도로 구축하는 것도 방법이다.
3] Truecasing: 대소문자 맞추기(영어 한정).
4] Punctuation detection: 물음표, 느낌표, 마침표, 쉼표 등 문장부호를 적절히 넣어주는 작업이다.
5] Disfluency detection: 텍스트와 달리 음성은 화자가 잘못 말한 단어가 얼마든지 끼어있을 수 있다. 이를 캐치해 제거하거나 폰트 변화 등으로 표시해 준다. 혹은 음성 인식 결과 오류를 바로 잡는 역할을 하기도 한다.
3. Sentence segmentation / Punctuation detection
위의 다섯 가지 과제 가운데 문장 분리(sentence segmentation) 태스크를 조금 더 살펴보자. 문장 분리는 음성 인식 결과로 출력된 각 단어 사이사이 모두에 대해 문장 경계인지(sentence boundary) 아닌지(sentence-internal) 가려내는 이진 분류(binary classification) 문제로 볼 수 있다. 그 컨셉은 그림2와 같다.
그림2 SENTENCE SEGMENTATION
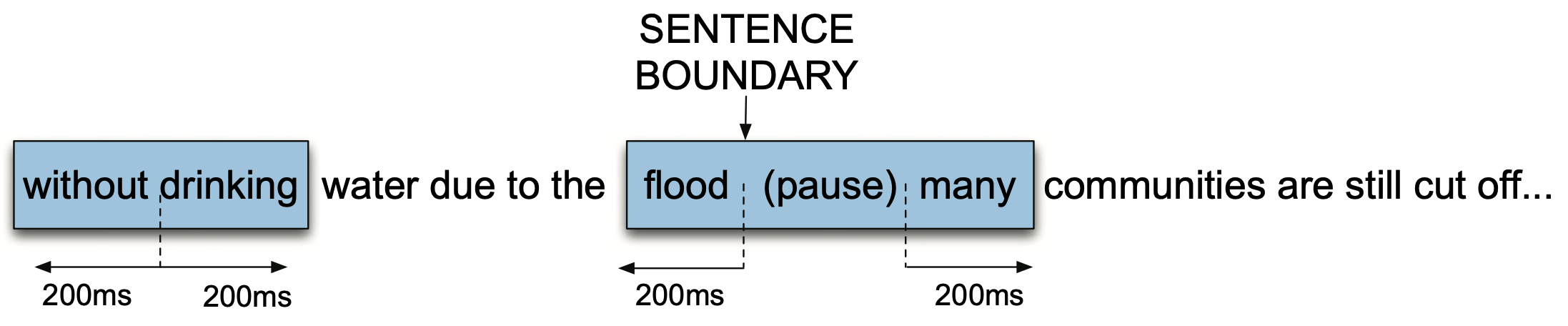
문장 분리 모델에 사용할 수 있는 피처는 다음과 같은 종류를 쓸 수 있다.
1] Duration: 현재 분석 대상 구간(그림2에서 각 단어 사이사이) 앞에 있는 음소의 길이 정보. 보통 문장 마지막 단어는 길게 발음하는 경향이 있다.
2] Pause: 현재 분석 대상 구간에 휴지(pause)가 끼어 있는지, 있다면 얼마나 긴지에 대한 정보. 대개 사람들은 다음 문장을 말할 때 살짝 시간을 둔다.
3] F0 features: 현재 분석 대상 구간의 피치(pitch) 변화. 문장이 끝날 때는 대개 피치가 발화자의 F0 베이스라인에 가깝게 떨어진다(final fall).
문장 부호 탐지(Punctuation detection) 역시 문장 분리 모델과 문제 정의 및 피처 사용 양상이 유사하다. 다만 문장 부호 탐지 모델이 분류해야 할 범주는 여러 개(마침표, 쉼표, 물음표, 느낌표 등)라는 점에서 문장 분리와 다르다.
4. Disfluency detection
Disfluency detection은 화자가 잘못 발화한 내용을 없애거나 교정하거나 별도로 표시해주는 작업이다. 그 종류는 그림3과 같다. 문장 중간에 별 의미 없이 말한 '아, 음' 같은 간투사(間投詞), 반복된 단어, 문장의 재시작 등 등이 그 대상이다. 이들은 음성 인식 결과를 텍스트화했을 때 이해에 큰 도움이 되지 않으므로 섬세한 후처리가 필요하다.
그림3 DISFLUENCY DETECTION (1)

그림4는 Disfluency detection을 개념적으로 나타낸 것이다. 문장 분리 모델 구축 때와 마찬가지로 다양한 음성 특질(feature)을 활용해 단어와 단어 사이의 경계를 문장 중단(interuption), 문장 재개(repair), 문장 계속(sentence-internal) 등 범주별로 분류한다. Disfluency detection에 쓰이는 피처로는 품사 등 텍스트 정보, 피치(pitch) 등 음성 정보를 모두 활용한다.
그림4 DISFLUENCY DETECTION (2)
