4. Stack Decoding
Info
스택 디코딩(Stack Decoding)은 비터비 알고리즘(Viterbi Algorithm)을 보완한 기법이다. 이 글에서 간단히 살펴본다.
1. Motivation
비터비 알고리즘(Viterbi Algorithm)은 매 시점(time), 모든 상태(state)에 대해 베스트 경로 하나만을 남기면서 디코딩을 수행한다. 그런데 매 순간, 상태의 최적이 전체 최적이 아닐 가능성이 있다. 스택 디코딩(Stack Decoding)은 이렇듯 비터비 알고리즘의 단점을 보완한 기법인데, 스택 디코딩 과정을 개략적으로 나타낸 그림은 그림1과 같다.
그림1 MOTIVATION

그림1을 보면 START에서 확장된 노드(lattice라고도 불림)는 I, the, is, of, are, dogs 등이다. 첫 번째 시점 기준에서 끝까지 디코딩을 수행했을 때 기대되는 스코어 값들이 높은 단어들을 나열한 것이다. 만약 첫 번째 시점 기준에서 가장 높은 확률값이 높은 단어가 dogs였다면 첫 번째 단어가 dogs이고 이를 전제로 했을 때 두 번째 시점 기준에서 끝까지 디코딩을 수행했을 때 기대되는 스코어 값들이 높은 단어들을 다시 리스트업한다. 이렇게 선택된 단어가 do, want, can't라면 이들 각각에 대해 다시 같은 방식으로 탐색을 계속해 나간다.
요컨대 스택 디코딩은 현재 시점 기준에서 끝까지 디코딩을 수행했을 때 기대되는 스코어 값들이 높은 단어들을 차례대로 확장해가면서 탐색하는 알고리즘이다. 매 시점, 상태마다 베스트 경로 하나만을 남기는 비터비 알고리즘과 달리 탐색 범위가 꽤 넓어지는 셈이다. 스택 디코딩은 \(**A^{∗}\) 알고리즘**이라고도 불린다.
2. Algorithm
스택 디코딩 알고리즘은 다음과 같다.
1] [START] 노드 기준 자식 노드를 탐색하고, 이들 노드와 스코어 값을 우선순위 큐(priority queue)에 넣는다.
2] 우선순위 큐 가운데 가장 높은 스코어 값을 지닌 자식 노드를 팝(pop)하고, 이 노드의 자식 노드를 탐색한 뒤, 이들 노드와 확률값을 큐에 넣는다.
3] [END]로 끝나는 시퀀스가 우선순위 큐에서 가장 높은 스코어 값이 될 때까지 2번을 반복한다.
알고리즘을 예시로 이해해 보자. 그림2는 위의 알고리즘 1을 수행한 결과이다. 이로써 큐에는 [([START] If, 30), ([START] Alice, 40), ([START] In, 4), ([START] Every, 25)]가 들어 있다. 우선순위 큐에 들어가 있는 각 스코어 값은 해당 시점의 각 문자열 시퀀스가 주어진 상태에서 끝까지 디코딩을 수행했을 때 기대되는 점수들이다.
그림2 STACK DECODING (1)

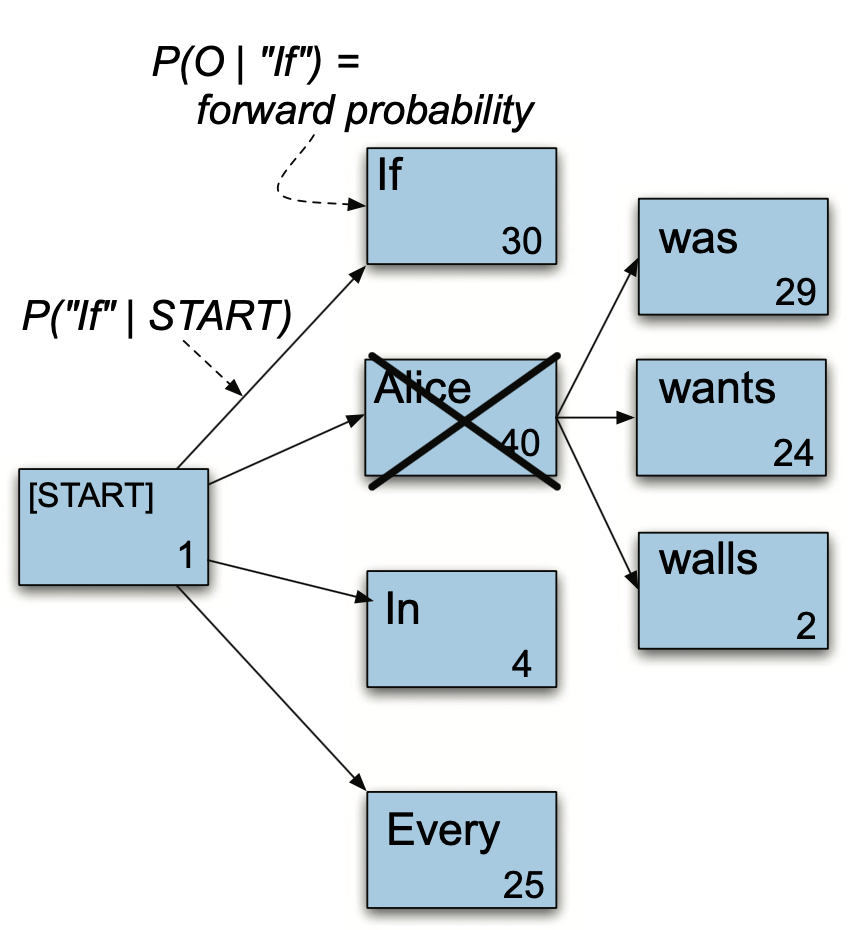
우선순위 큐에서 가장 높은 스코어 값을 지닌 문자열 시퀀스를 팝한다. [START] Alice(40)이다. 그리고 해당 노드의 자식 노드를 탐색하고, 이들 노드와 스코어 값을 큐에 넣는다. 이로써 우선순위 큐에는 [([START] If, 30), ([START] In, 4), ([START] Every, 25), ([START] Alice was, 29), ([START] Alice wants, 24), ([START] Alice walls, 2)]가 들어 있다.
그림3 STACK DECODING (2)
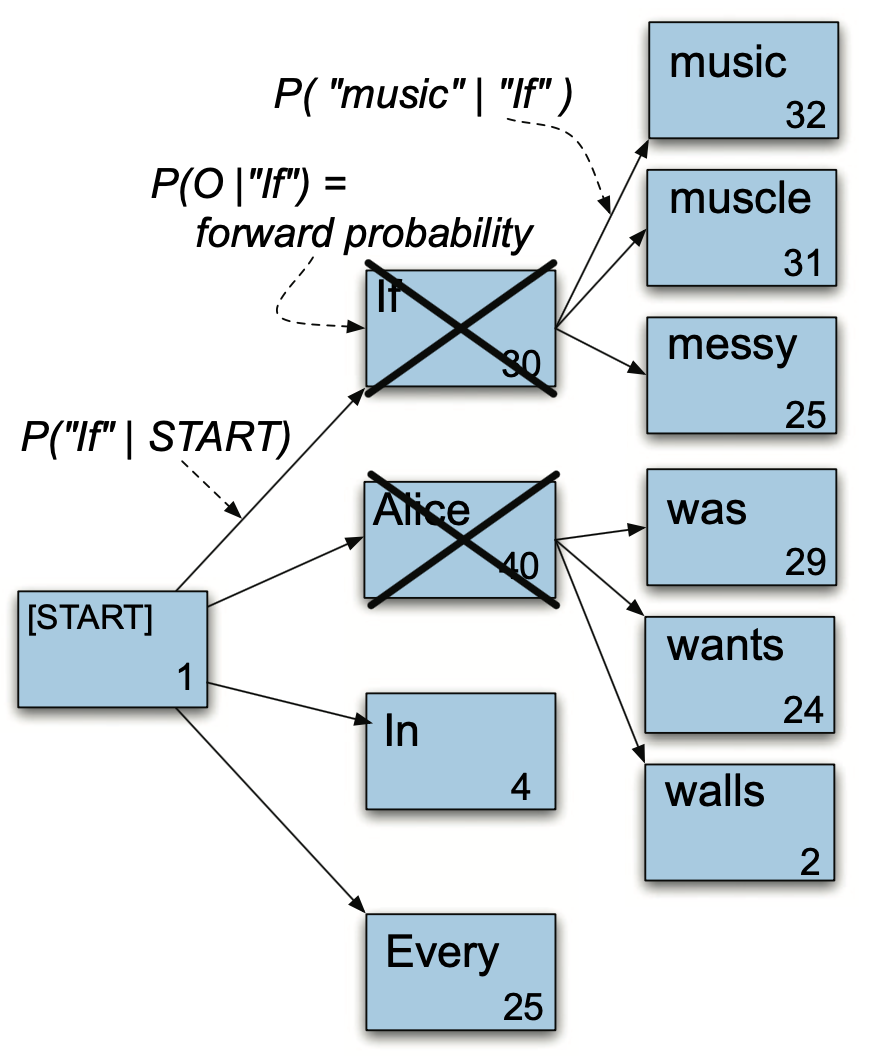
우선순위 큐에서 가장 높은 스코어 값을 지닌 문자열 시퀀스를 팝한다. [START] If(30)이다. 그리고 해당 노드의 자식 노드를 탐색하고, 이들 노드와 스코어 값을 큐에 넣는다. 이로써 우선순위 큐에는 [([START] In, 4), ([START] Every, 25), ([START] Alice was, 29), ([START] Alice wants, 24), ([START] Alice walls, 2), ([START] If music, 32), ([START] If muscle, 31), ([START] If messy, 25)]가 들어 있다.
그림4 STACK DECODING (3)
이러한 방식으로 [END]로 끝나는 시퀀스가 우선순위 큐에서 가장 높은 스코어 값이 될 때까지 디코딩을 수행한다.
3. 기타 경로 탐색 알고리즘과의 비교
스택 디코딩은 너비우선탐색(Breath First Search), 다익스트라 알고리즘(Dijkstra’s algorithm), Greedy Best-First Search 등과 비교된다.
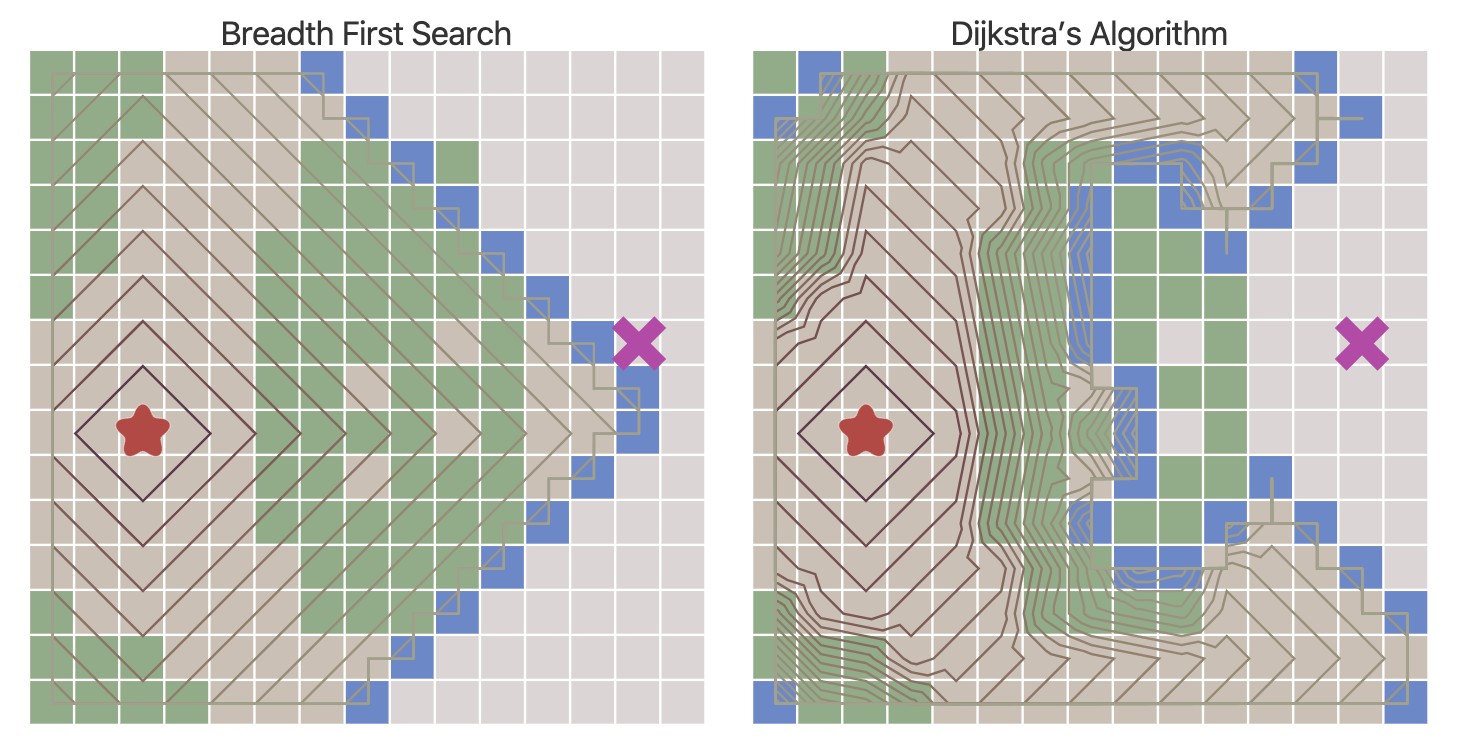
우선 너비우선탐색과 다익스트라 알고리즘을 먼저 보자. 그림5와 같다. 너비우선탐색은 기준 노드에 인접한 모든 노드를 순서대로 방문하는 그래프 순회(traverse) 기법이다. 다익스트라 알고리즘은 기준 노드의 인접 노드 가운데 시작노드에서부터의 거리가 최소인 인접 노드를 우선 방문한다.
그림5를 보면 너비우선탐색은 거리(비용)에 관계없이 인접 노드를 순차 탐색하는 반면 다익스트라 알고리즘은 인접 노드 방문 순서를 따질 때 시작노드에서부터의 거리(비용)에 따라 달리 적용하는 걸 확인할 수 있다. 따라서 너비우선탐색은 구성 요소 간 우선순위가 없는 일반 큐(queue)를 사용하는 반면, 다익스트라 알고리즘은 우선순위 큐를 자료 구조로 사용한다.
그림5 BREATH FIRST SEARCH VS DIJKSTRA’S ALGORITHM
이번엔 너비우선탐색과 Greedy Best-First Search를 비교해 보자. 그림6과 같다. Greedy Best-First Search는 인접 노드 방문 순서를 정할 때 현재 탐색 노드에서부터 종료 노드까지의 기대 비용을 고려한다. 이는 휴리스틱(heuristic) 비용 함수 \(h\)로 실현이 되는데, 그림6의 예시에서는 Greedy Best-First Search의 \(h\)로 탐색 대상 노드에서부터 종료 노드에 이르는 맨하탄 거리(Manhattan distance)를 사용한 것이다.
Greedy Best-First Search에서는 이렇듯 경로 탐색에 개발자의 사전 지식을 반영할 수 있다. 물론 \(h\)를 잘못 설계할 경우 너비우선탐색보다 더 많은 시간이 소요될 수 있다. Greedy Best-First Search는 인접 노드 방문 우선 순위가 \(h\)에 따라 달라지기 때문에 다익스트라 알고리즘과 마찬가지로 우선순위 큐를 자료 구조로 사용한다.
그림6 BREATH FIRST SEARCH VS GREEDY BEST-FIRST SEARCH

스택 디코딩은 다익스트라 알고리즘과 Greedy Best-First Search의 비용 함수를 모두 사용한다. 인접 노드 방문 순서를 정할 때 (1) 시작노드에서부터 탐색 대상 노드 사이의 거리(비용) (2) 탐색 대상 노드에서부터 종료 노드에 이르는 기대 거리(비용)을 더해 함께 따진다. 스택 디코딩 역시 우선순위 큐를 자료 구조로 사용한다.
4. Score Function
음성 인식 모델을 위한 스택 디코딩 알고리즘 설명 예시에서 각 노드의 스코어 값들은 (1) 시작노드에서부터 탐색 대상 노드에 이를 가능성 (2) 탐색 대상 노드에서부터 종료 노드에 이를 가능성을 더한 값에 해당한다. 이 값은 높을수록 좋다. 현재 탐색 대상인 부분 경로(partial path), 즉 문장 일부를 \(p\)라고 할 때 전자는 \(g(p)\), 후자는 \(h^{∗}(p)\)로 실현된다. 수식1과 같다.
수식1 SCORE FUNCTION
수식1에서 \(g(p)\)는 \(p\)에 해당하는 전방 확률(forward probability)로 구할 수 있다. \(h^{∗}(p)\)는 다양한 구현 방식이 있을텐데, 간단하게는 문장 완성까지 남은 단어 개수에 비례하도록 스코어를 부여하는 방식이 있을 것 같다.
5. Tree-Structured Lexicons
스택 디코딩을 수행할 때 자식 노드를 탐색하는 것 역시 만만치 않은 계산 비용이 든다. 이를 위해 제시된 것이 Tree-Structured Lexicons이다. 그림7과 같이 전방 확률이 높은 음소 시퀀스를 미리 저장해 두고 자식 노드를 탐색할 때 바로바로 꺼내어 쓸 수 있도록 준비해 두는 것이다. 자식 노드 탐색 시 계산량이 많은 전방 확률들을 일일이 구할 필요가 없기 때문에 효율적이고 빠른 디코딩이 가능해 진다.
그림7 TREE-STRUCTURED LEXICONS

한편 그림7은 Context-Dependent Subphone을 나타낸다. 구체적으로는 subphone 세 개를 연이어 사용하는 triphone 구조이다. Current subphone(Previous subphone, Next Subphone)이다.