3. Multipass Decoding
Info
이 글에서는 1차로 여러 개의 후보군을 만들고 2차에서 자세히 탐색해 디코딩 품질을 높이는 Multipass Decoding 기법을 살펴본다. 이 기법은 비터비 알고리즘의 단점을 보완한 것이다.
1. Concepts
기존 음성 인식 모델을 잘 학습했다 하더라도 입력 음성에 대해 최적의 추정 결과를 내기란 쉬운 일이 아니다. 그도 그럴 것이 시퀀스 탐색 범위가 너무 넓기 때문이다. 입력 음성 피처로 탐색 대상 음소 시퀀스 범위를 좁히더라도 그 경우의 수는 음소 수와 시퀀스 길이에 비례해 폭증할 것이다.
더군다나 매 시간(time), 상태(state)에 대해 베스트 경로 하나만을 탐색하는 비터비 알고리즘은 최적 시퀀스 도출을 장담할 수 없다. 기존 음성 인식 모델은 Context-Dependent Acoustic Model로 모델링하는 경우가 많은데, 상태(state)가 음소보다 작은 단위의 subphone이기 때문에, 비터비 알고리즘으로 운 좋게 가장 확률이 높은 subphone 시퀀스를 찾았다 하더라도 이것이 가장 확률이 높은 word 시퀀스가 아닐 수도 있다. 예컨대 다음과 같다.
- 가자
- 가즈아
- 가즈으아
- 가즈으아아
- …
위와 같이 같은 단어라 할지라도 화자나 상황 등에 따라 다양한 방식으로 발음이 될 수 있다. 따라서 발음 방법이 다양한 단어들이 등장할 확률이 낮아지게 되는데, 매 시간, 상태에 대해 최적 상태열 하나만을 남기는 비터비 알고리즘은 결과적으로 발음 방법이 다양한 단어 내지 단어 시퀀스에 대해 패널티를 부여하는 셈이 되어 디코딩 결과가 상당히 부정확해질 수 있는 것이다.
아울러 기존 음성 인식 시스템은 입력 음성과 음소 사이의 관계를 추론하는 음향 모델(Acoustic Model)과 더불어 단어 시퀀스 사이의 정합성을 판단하는 언어 모델(Language Model)을 동시에 적용해 디코딩 품질을 높이고 있다. 상태를 subphone으로 모델링한 음성 인식 시스템에 비터비 디코딩을 적용할 경우 바이그램(bigram) 이상 단위의 언어모델을 사용할 수 없다. 히든 마코프 모델(Hidden Markov Model)의 마코프 가정에 의해 직전 상태와 현재 상태 사이의 전이만을 따질 수 있기 때문이다.
이 문제에 대응하기 위해 제시된 대안은 멀티패스 디코딩(multipass decoding), 스택 디코딩(stack decoding) 혹은 \(A^{*}\) 디코딩 두 가지이다. 둘 모두 1개 이상의 복수 후보 시퀀스를 고려할 수 있고 바이그램 이상의 언어 모델을 적용할 수 있는 장점이 있다. 전자는 이 글에서 살펴보고, 스택 디코딩(stack decoding) 혹은 \(A^{*}\) 디코딩은 별도 글에서 설명한다.
2. N-best list
멀티패스 디코딩(multipass decoding)이란 디코딩 단계를 크게 두 가지로 나눠, 1차에서는 복수의 후보 시퀀스들을 빠르게 탐색하고 2차에서 별도의 고품질 모델의 도움을 받아 세밀하게 탐색하는 기법이다. 그 컨셉은 그림1과 같다. 1차에서 탐색 공간(search space)을 효과적으로 줄이고, 2차에서 디코딩 품질을 높이는 기법이다. 1차에서 탐색된 후보 시퀀스들을 N-best list라 불린다.
그림1 N-BEST DECODING
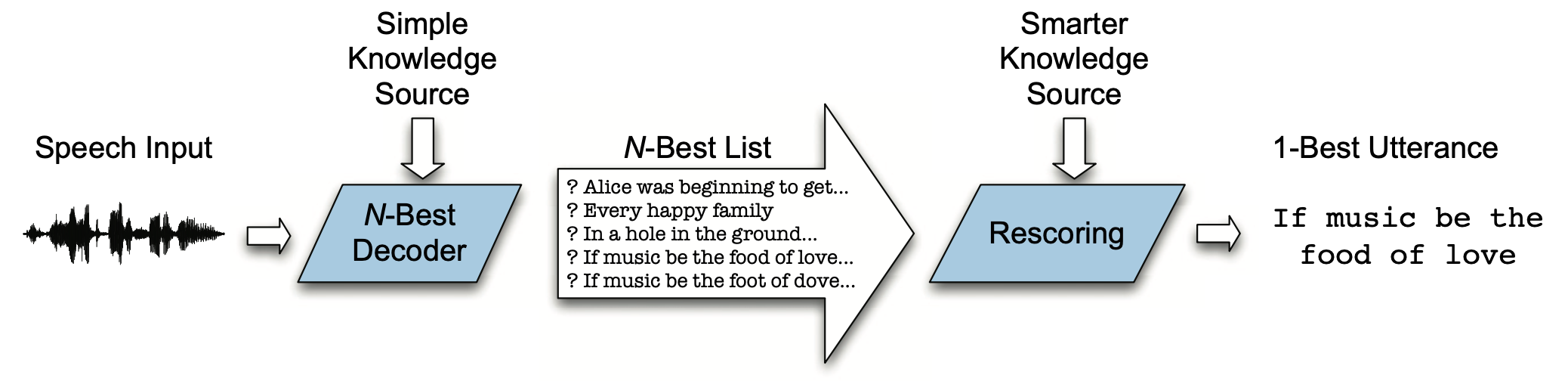
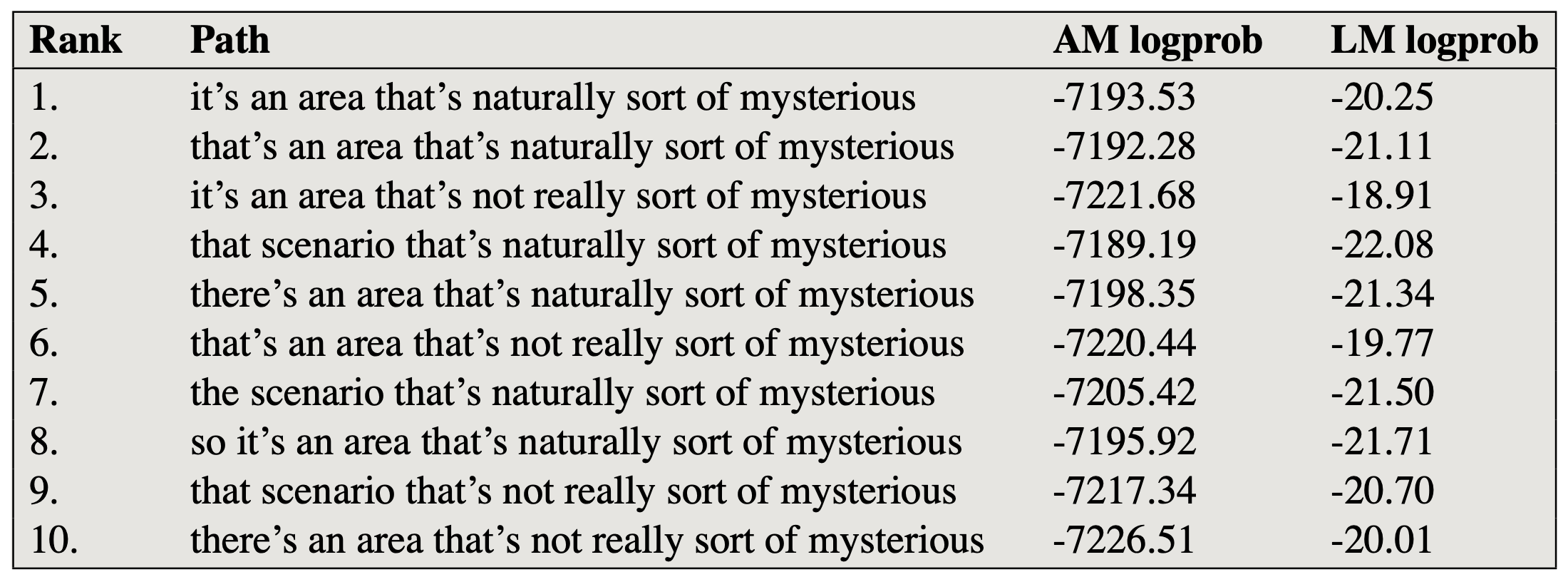
그림2는 1차에서 빠르게 훑은 후보 시퀀스 10개 목록의 예시이다. 상태가 subphone으로 모델링되어 있기 때문에 이를 단어 단위로 바꾸고 이전 히스토리(history)가 동일한 경로(path)들의 음향 모델/언어 모델 로그 확률은 합쳐준 결과이다. 그림2처럼 리스트업을 할 수 있다면 2차 정밀 검토에서 아래 10개 후보 가운데 최적의 후보를 하나 선택함으로써 디코딩 품질을 높일 수 있다.
그림2 N-BEST LIST
가장 간단한 방식의 멀티패스 디코딩은 후보 경로를 1개만 남기는 비터비 알고리즘의 탐색 범위를 넓혀 \(n\)개를 고려하는 것이다(N-best 디코딩). 이는 beam search와 유사하다. 그러나 \(n\)이 커진다면 굳이 1차와 2차로 나눠서 검토할 필요가 없을 정도로 계산량이 많아져 비효율적이다. 아울러 음향 모델 리턴값은 문장 전체에 대한 로그 확률(AM logprob)이기 때문에 1차 검토 시 단어 단위로 학습된 언어모델의 리턴값을 반영하기 어렵다. 같은 단어라 하더라도 시작-끝 duration이 다를 수도 있는데, 여기에 대한 구분도 역시 쉽지 않다.
N-best 디코딩의 단점을 극복하고자 Word Lattice, Word Graph/Finite-state Machine, Confusion Network 등이 제안됐다. 차례대로 살펴본다. 모두 1차 탐색용으로 쓰인다.
3. Word Lattice
Word Lattice는 후보 단어 시퀀스들에 관련된 정보가 함께 내포된 그래프(graph)이다. 음향 모델이 subphone으로 모델링 되었다고 하더라도 단어 수준의 래티스, 즉 그래프를 만들어 낸다. Word Lattice는 그림3처럼 크게 두 가지 표현 방식이 있다. 하나는 노드(node)를 단어, 에지(edge)를 단어 간 전이(transition)으로 그리는 것이다. 나머지는 노드를 시간(time), 에지를 단어로 보는 것이다. 그림3 하단의 Word Lattice는 나라는 단어가 1~3 시점까지 지속됨(duration)을 의미한다.
그림3 WORD LATTICE
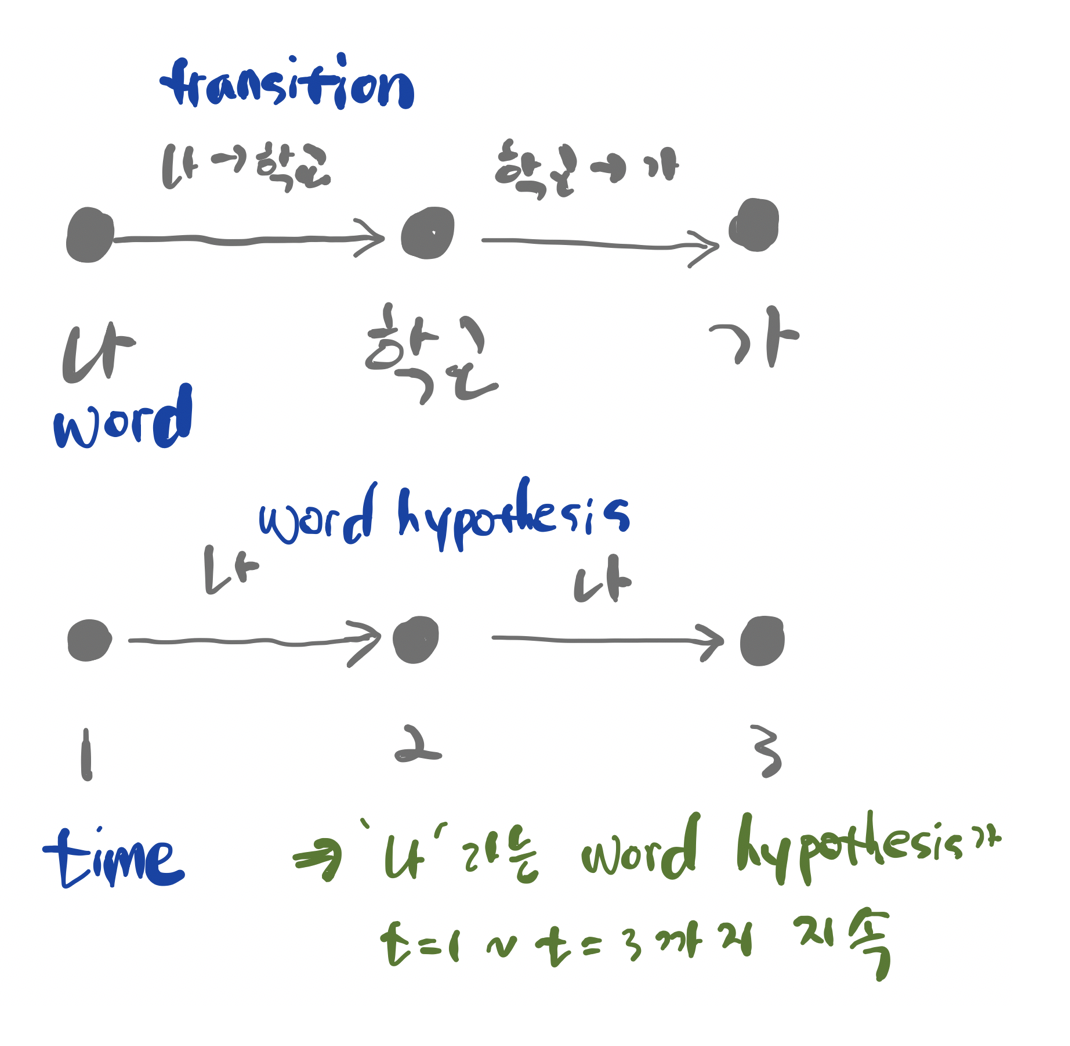
그림4는 그림3 하단의 방식대로 Word Lattice를 그린 것이다. 음향 모델이 각 시점별로 subphone 시퀀스들을 예측할 수 있는데, 그 가운데 \(n\)개의 후보 시퀀스를 찾아 해당 시퀀스들을 단어 단위로 병합(merge)하면 그림4와 같은 Word Lattice를 구할 수 있다. 그림4에는 다 표시되지 않았지만 에지에는 단어와 전이 스코어(음향 모델 + 언어 모델의 가능도값) 정보가 기재돼 있다.
Word Lattice가 내포할 수 있는 정보는 꽤 많다. SO IT's, IT's, THERE's, THAT's를 보면 동일한 구간 내에 다양한 단어 후보들이 존재할 수 있다. SO IT's를 보면 같은 단어라도 각기 다른 duration 정보를 가질 수 있다. THE SCENARIO, THAT SCENARIO의 경우 같은 단어라도 다른 컨텍스트(context)를 가질 수 있다.
Word Lattice의 품질을 평가하는 지표로는 Lattice Error Rate(LER)이라는 것이 있다. LER은 Word Lattice상 후보 시퀀스들 가운데 최소 Word Error Rate를 가리킨다. 2차 정밀 검토를 아무리 잘한다 하더라도 1차 검토 리스트가 좋지 않으면 2차 검토가 무의미하기 때문이다.
그림4 WORD LATTICE
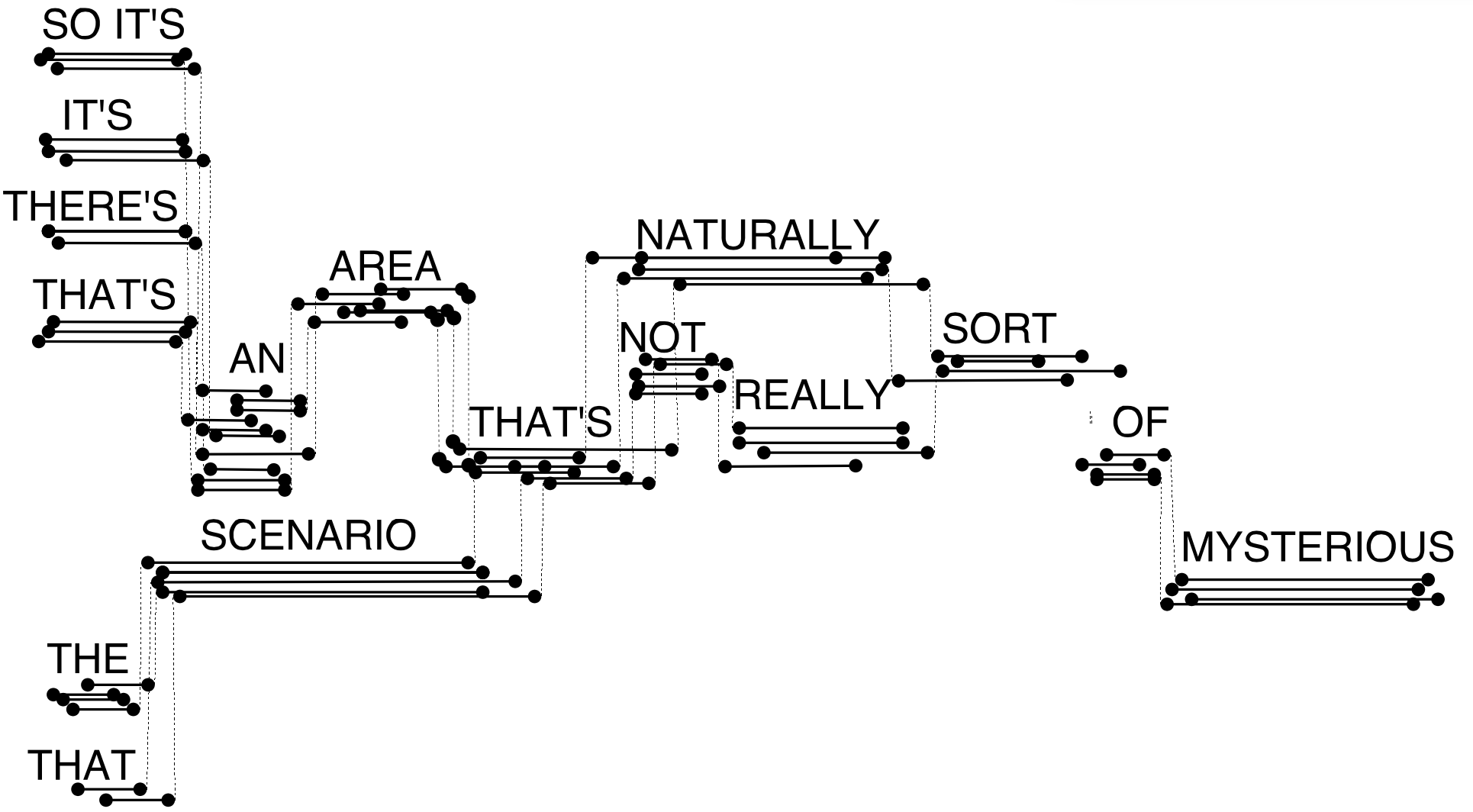
Word Lattice에는 Lattice Density라는 개념이 있다. Word Lattice의 에지 개수를 정답 단어 시퀀스 길이(=단어 수)로 나눠준 것이다. 그림4의 경우 후보 시퀀스들이 꽤 많이서 Lattice Density가 높은 편이다. 그만큼 불필요한 정보가 많다는 것이다.
4. Word Graph / Finite-state Machine
Word Graph 혹은 Finite-state Machine은 Duration(시작/끝)이 살짝 다른 비슷한 lattice path들을 병합해놓은 것이다. 그 컨셉은 그림5과 같다. 이 모델에서는 병합 과정에서 시간 정보를 제거한다.
그림5 WORD GRAPH
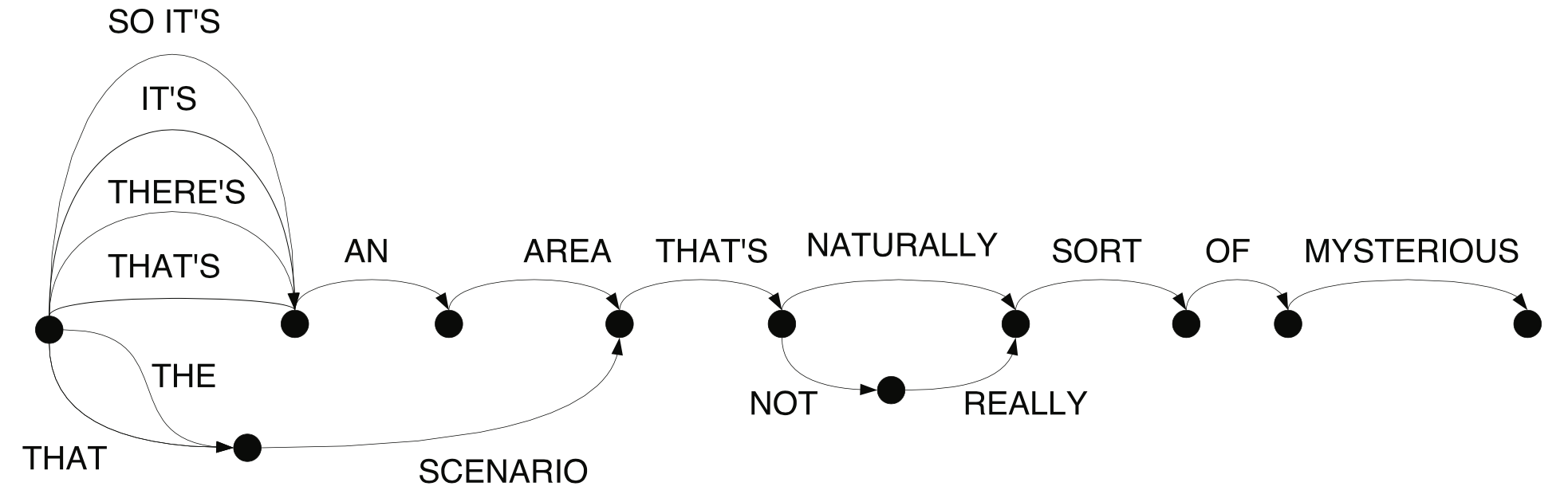
5. Confusion Network
Word Graph 혹은 Finite-state Machine는 불필요한 정보를 꽤 없애긴 했지만, 디코딩 결과가 얼마나 정확한지(confident) 정보는 알 수 없다. Word Graph 혹은 Finite-state Machine에서 상태 간 전이(transition) 스코어를 그 합이 1이 되도록 확률로 정규화한 모델을 Confusion Network라고 한다. 이 구조에서는 후보 시퀀스 각각에 대해 confidence 값을 부여할 수 있다. Confusion Network의 컨셉은 그림6과 같다.
그림6 CONFUSION NETWORK