3. Deep Speech
Info
중국 대표 IT 기업 '바이두(baidu)'에서 공개한 End-to-End 음성 인식 모델 Deep Speech2 모델을 소개한다. 이 모델은 이전 기법(Deep Speech) 대비 성능을 대폭 끌어 올려 주목을 받았다. 이뿐 아니라 학습 등 실전 테크닉 팁도 대거 방출해 눈길을 끈다.
1. Introduction
저자들이 밝힌 Deep Speech2의 핵심 성공 비결은 세 가지이다. 이 글에서는 1번 위주로 살펴본다.
1] 음성 인식에 유리한 모델 아키텍처
2] 대규모(1만 시간 가량) 학습 데이터 적용
3] 효율적인 학습 테크닉: Connectionist Temporal Classification(CTC) loss 직접 구현 등
Deep Speech2의 모델 구조는 그림1과 같다. 우선 음성 입력(Power Spectrogram)에서 중요한 특질(feature)을 뽑아내는 레이어로 Convolutional Neural Network를 사용하고 있다. 이후 양방향(bidirectional) Recurrent Neural Network를 두었다. 마지막에는 Fully Connected Layer가 자리잡고 있다. 레이어와 레이어 사이에는 Batch Normalization을 적용했다.
그림1 DEEP SPEECH2

2. Convolution Layer
Deep Speech2 입력은 파워 스펙트로그램(Power Spectrogram)이다. 25ms 안팎 찰나의 주파수별 파워(power) 수치가 기록되어 있는 음성 피처를 스펙트럼(spectrum) 혹은 프레임(frame)이라고 하는데, 분석 대상 주파수 영역(bin)을 \(d\)개로 나눴을 경우 스펙트럼의 차원수는 \(d\)가 된다. 이걸 시간 축으로 쭉 나열한 것, 즉 프레임 시퀀스가 파워 스펙트로그램이다.
학습 데이터 음성 길이는 각기 다를 수 있다. 음성이 길수록 프레임이 많아진다는 뜻이다. 이에 \(i\)번째 학습데이터의 프레임 갯수를 \(T^{(i)}\)라고 정의해 둔다. 그림2 상단 행렬을 Deep Speech2 입력 파워 스펙트럼이라고 보면 첫번째 행(\(d\)차원 벡터)은 입력 음성의 첫 번째 프레임의 주파수별 파워, 첫 번째 열(\(T^{(i)}\)차원 벡터)은 첫 번째 주파수 영역(bin)의 시간대별 파워가 된다.
그림2 TIME DOMAIN CONVOLUTION
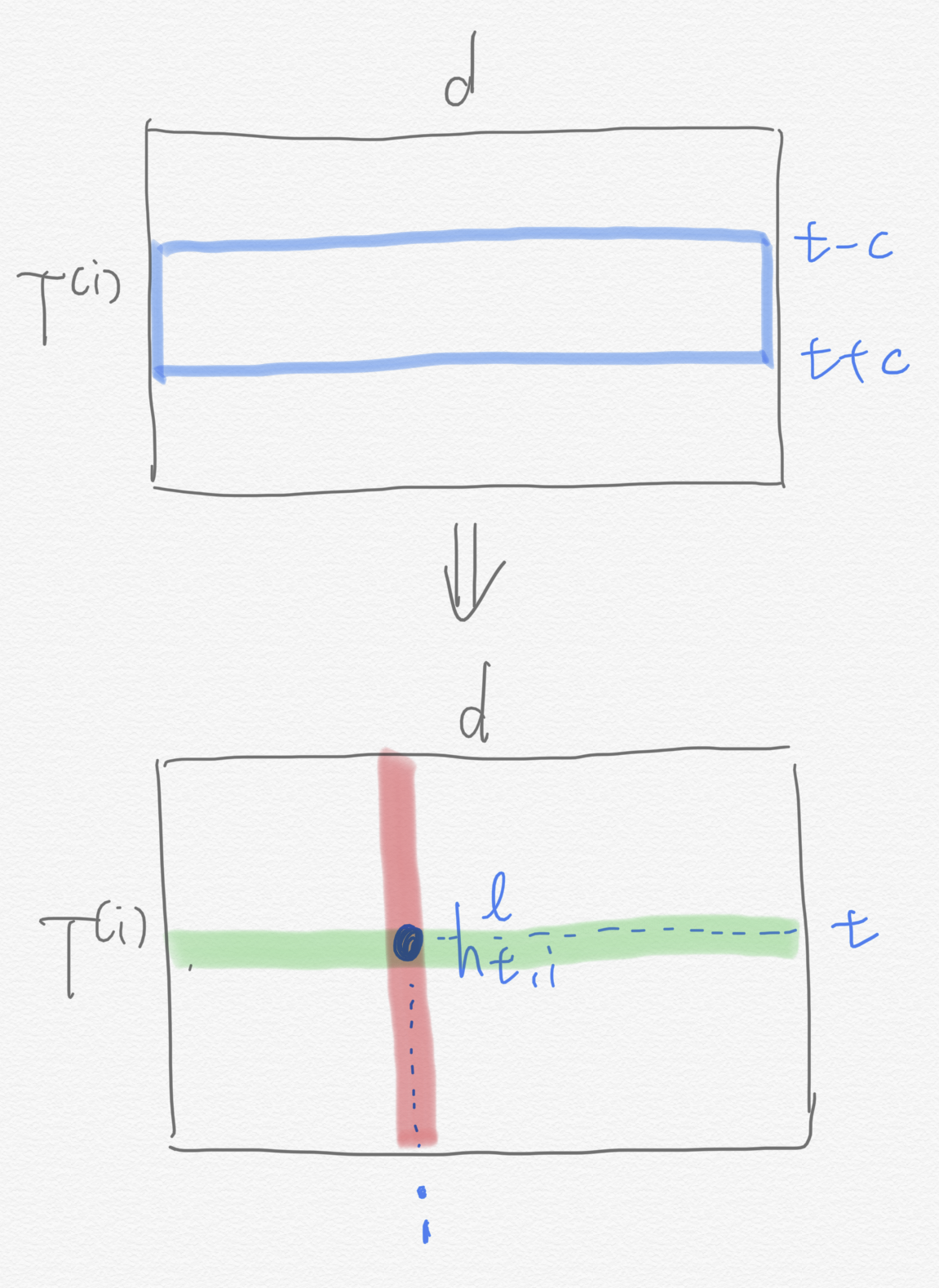
그럼 이제 Deep Speech2의 초기 레이어에서 벌어지는 컨볼루션 연산을 살펴보자. \(l\)번째 레이어의 \(t\)번째 행, \(i\)번째 열에 해당하는 시간 축에 대한 컨볼루션(1D conv) 연산 결과(\(h_{t, i}^{l}\))는 수식1처럼 정의된다. 여기에서 \(c\)는 컨볼루션 연산을 할 때 고려하는 컨텍스트(context) 크기를 가리킨다. 이 값이 클수록 한 번에 더 많은 이웃 프레임들을 본다.
위 그림2는 입력 파워 스펙트로그램에 시간 축에 대한 컨볼루션 연산을 수행하는 과정을 도식적으로 나타낸 것이다. 그림2 상단 행렬의 파란색 칸이 \(h_{t-c: t+c}^{l-1}\)에 해당한다. 이것과 같은 크기의 가중치 행렬(\(w_{i}^{l}\))을 element-wise product를 수행하고 활성함수(activation function)를 적용한 것이 컨볼루션 연산이다.
수식1 TIME DOMAIN CONVOLUTION
저자들은 수식1의 활성함수 \(f\)로 clipped ReLU 함수를 썼다. 일반적인 ReLU와 거의 유사하나 아웃풋 최대값을 20으로 제한했다. 수식2와 같다.
수식2 CLIPPED RELU
그림2 하단 행렬 \(i\)번째 열(붉은 선)은 \(i\)번째 필터, 즉 \(w_{i}^{l}\)가 시간 축을 따라 컨볼루션 연산을 수행한 결과를 가리킨다. 다시 말해 \(i\)번째 열의 첫 번째 스칼라 값은 \(i\)번째 필터가 첫 번째 시점과 관계된 입력을 보고 계산한 아웃풋, 마지막 스칼라 값은 \(i\)번째 필터가 마지막 시점과 관계된 입력을 보고 계산한 아웃풋이 된다.
한편 \(t\)번째 행(녹색 선)은 컨볼루션 입력이 \(h_{t-c: t+c}^{l-1}\)로 같고 필터가 각기 다른 계산 결과를 나타낸다. 다시 말해 \(t\)번째 행의 첫 번째 스칼라 값은 첫 번째 필터의 아웃풋, 마지막 스칼라 값은 마지막 \(d\)번째 필터의 아웃풋이 된다.
그림2는 이해를 돕기 위해 패딩(padding)과 스트라이드(stride) 등을 적절히 조절해 \(T^{(i)}\)가 줄어들지 않도록 그린 것인데, 실제로 Deep Speech2 저자들은 컨볼루션 레이어를 여러 층을 쌓되 초기 레이어에는 스트라이드를 조금 크게 줘서 다음 레이어에서 계산할 프레임 갯수를 \(T^{(i)}\)보다 줄이는 서브샘플(sub-sample) 방식을 적용했다.
지금까지 예시로 설명한 것은 시간 축에 대한 컨볼루션 연산(1d conv)이었다. 그림3에서 녹색 칸과 같다. \(t^{\prime}\)번째에서 \(t^{\prime \prime}\)번째 프레임(시간대)의 정보(time-only domain)를 취한다. 이 때 계산 대상 주파수 영역대는 \(d\)개 bin 전체가 된다.
그림3 1D CONV VS. 2D CONV
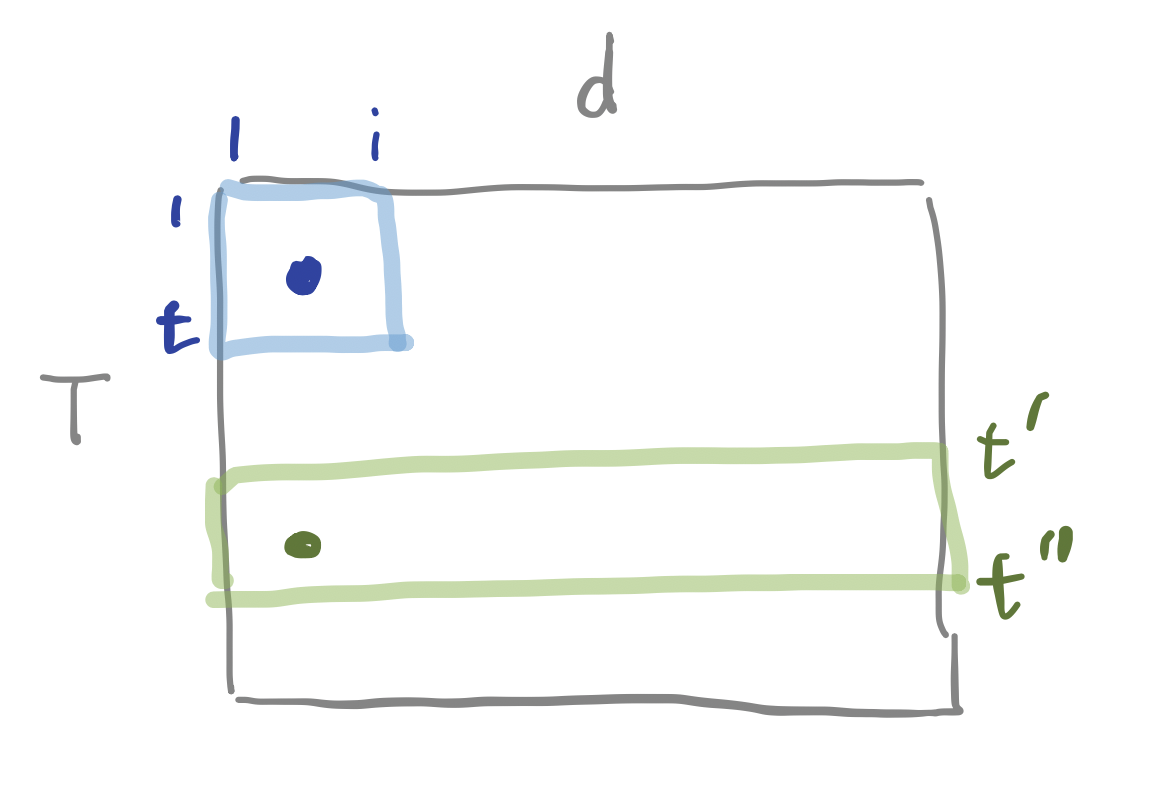
그런데 시간과 주파수 두 개 축에 대해 동시에 컨볼루션 연산(2d conv)을 수행할 수도 있다. 그림3에서 파란색 칸에 해당하는 영역을 컨볼루션(2d conv)할 경우 첫 번째에서 \(i\)번째 주파수 영역대(bin), 첫 번째에서 \(t\)번째 프레임(시간대)의 정보(time-and-frequency domain)를 취한다. 저자들에 따르면 1d conv보다는 2d conv를 적용한 모델의 인식 성능이 좋다고 한다.
3. Bidrectional RNN Layer
이번에는 양방향 RNN 레이어를 쌓을 차례이다. 양방향 RNN 레이어 계산 방식은 수식3과 같다. 그림4는 수식3 이해를 돕기 위해 그렸다. 직전(\(l−1\)) 레이어의 \(t\)번째 시점 계산 결과 \(h_{t}^{l-1}\)를 순방향(forward), 역방향(backward) 레이어에 각각 입력한다. 순방향 레이어의 또다른 입력으로는 현재 레이어(\(l\)) 직전 시점(\(t−1\))의 계산 결과, 역방향 레이어의 또다른 입력으로는 현재 레이어(\(l\)) 다음 시점(\(t+1\))의 계산 결과가 있다. \(g\)는 RNN 함수를 가리키는데, vanilla RNN을 쓸 수도 있고 LSTM을 적용할 수도 있다.
수식3 BIDIRECTIONAL RNN
그림4 BIDIRECTIONAL RNN
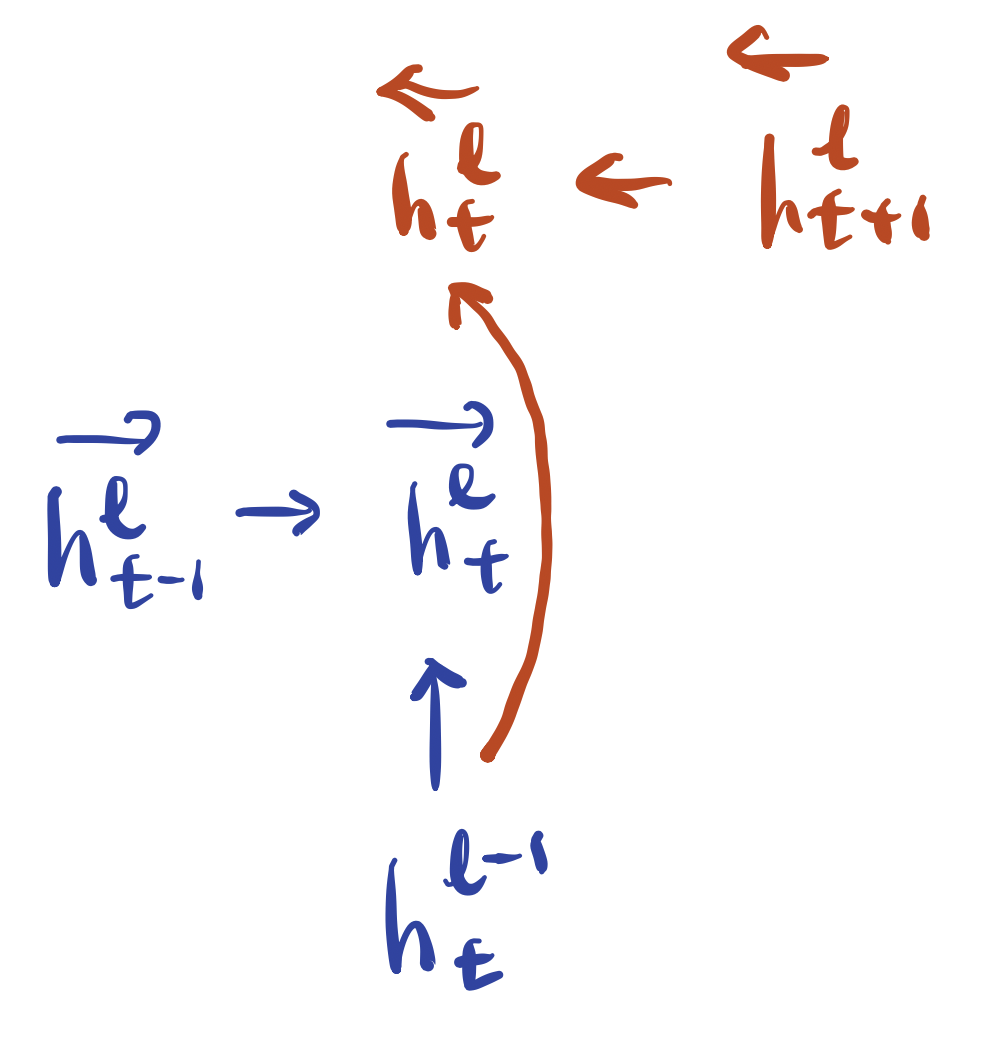
수식4는 일반적인 등식처럼 생각하면 헷갈릴 수 있을 것 같다. 파이썬(python) 코드를 작성하다보면 이미 계산된 결과에 추가로 계산을 수행해 같은 변수에 대입할 수 있는데, 저자들이 바로 이 방식으로 수식4를 작성한 듯하다. 수식4를 양방향 계산 결과에 풀커넥티드 레이어(Fully Connected Layer)를 적용한 일종의 후처리라고 이해했다.
수식4에서 \(h_{t}^{l-1}\)는 \(\overrightarrow{h_{t}^{l-1}}+\overleftarrow{h_{t}^{l-1}}\)이다. 활성함수 \(f\)(clipped ReLU) 내 첫 번째 항은 직전 레이어(\(l−1\))의 양방향 계산 결과(\(t\) 시점 포함), 두 번째 항은 현재 레이어(\(l\))의 순방향 계산 결과(\(t\) 시점은 제외)와 관련이 있다.
수식4 BIDIRECTIONAL RNN
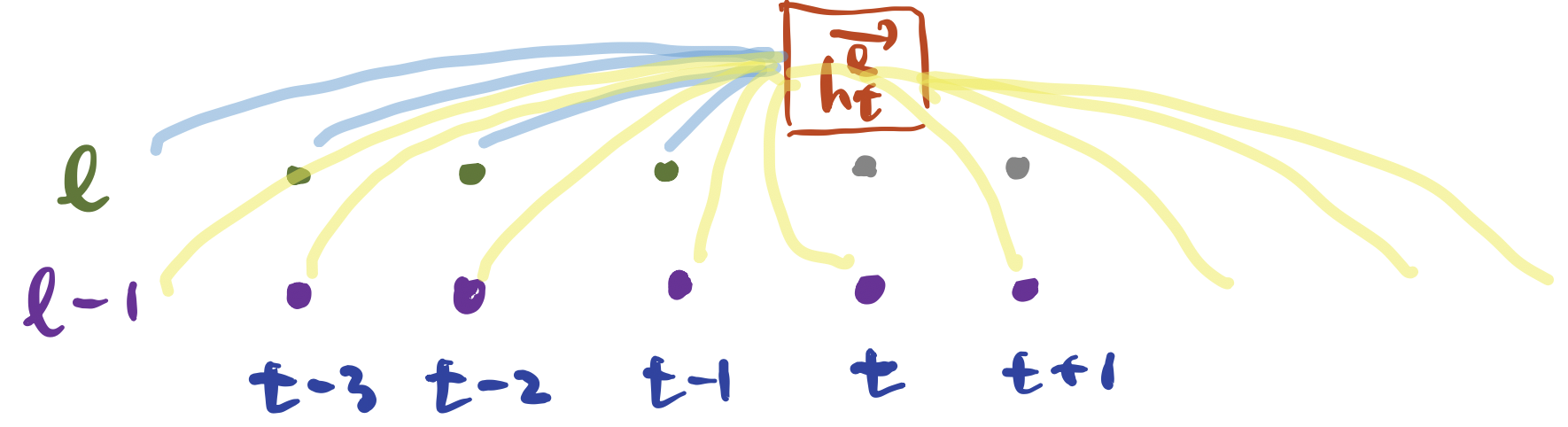
수식4 이해를 돕기 위해 그림5를 그렸다. 노란색 선이 수식4 \(f\) 안에 있는 첫 번째 항, 파란색 선이 두 번째 항에 대응한다. 역방향을 계산할 때는 두 번째 항을 역방향에 해당하는 것으로 대체하면 된다.
그림5 BIDIRECTIONAL RNN
4. Fully Connected / Softmax Layer
양방향 RNN 레이어 이후에 풀 커넥티드 레이어를 몇 층 쌓는다. 수식5와 같다. 직전 레이어가 양방향 RNN 마지막 레이어인 첫 번째 풀 커넥티드 레이어의 \(h_{t}^{l-1}\)는 마지막 순방향 RNN 레이어의 계산 결과인 \(\overrightarrow{h_{t}^{l-1}}\)과 역방향 레이어의 결과물인 \(\overleftarrow{h_{t}^{l-1}}\)을 더해준 값이다. 그 이후 풀 커넥티드 레이어에서는 \(h_{t}^{l-1}\)이 직전 풀 커넥티드 레이어의 계산 결과가 된다.
수식5 FULLY CONNECTED LAYER
마지막 풀 커넥티드 레이어의 최종 계산 결과가 \(h_{t}^{L-1}\)이라고 할 때 소프트맥스 레이어는 수식6처럼 계산한다. \(t\)번째 프레임, \(k\)번째 범주에 관한 소프트맥스 확률값을 가리킨다. 저자들은 영어 음성 인식 모델의 경우 알파벳 26개, 공백, 아포스트로피(apostrophe), blank 등 29개 범주를 채택하고 있다. 수식6으로 계산한 모델 출력과 정답을 가지고 CTC loss를 계산한 뒤 역전파(backpropagation)을 수행해 모델을 학습한다.
수식6 SOFTMAX LAYER
5. Batch Normalization
Deep Speech2 저자들은 선형변환(linear transformation)과 활성함수 \(f\)(clipped ReLU)가 연이어 나타나는 모든 곳(Conv, FC layer 등)에 Batch Normalization을 추가했다: \(f(W h+b) \rightarrow f(\mathcal{B}(\mathcal{W} h))\). 저자들은 바이어스 항(\(b\))을 생략한 이유로 Batch Normalization을 수행하면 이동평균(moving average)을 빼주는 정규화 과정 때문에 바이어스 효과가 상쇄되기 때문이라고 설명한다.
이와 같은 원칙에 따라 양방향 RNN 레이어(수식4)에도 Batch Normalization을 추가할 수 있는데, 학습 효율 증대를 위해 직전 레이어의 양방향 계산 결과(수식4의 첫 번째 항)에 대해서만 Batch Normalization을 적용했다고 한다. Batch Normalization이 효과를 발휘하려면 미니배치 내 모든 time step에 대해 mean과 variance를 계산할 수 있어야 하기 때문이라는 설명이다(수식4의 두번째 항은 time step별로 잘게 쪼개서 통계량을 구해야 함). 저자들이 RNN에 적용한 Batch Normalization은 수식7과 같다.
수식7 BATCH NORMALIZATION FOR RNNS
저자들에 따르면 각 Batch Normalization 블록의 평균과 분산의 이동평균을 학습할 때 구해놓고 이를 고정시킨 뒤 인퍼런스 환경에서 1개의 배치에 대해 Batch Normalization을 적용한 방식이, 인퍼런스 때 큰 배치를 쓰고 Batch Normalization을 수행하지 않는 방식보다 정확도가 더 높다고 한다.
6. SortaGrad
저자들은 미니배치를 구성하는 방식을 CTC loss에 맞도록 변형하였다. CTC loss는 그 특성상 음성 프레임 시퀀스 길이가 길어질수록 손실과 그래디언트가 커진다. 미니배치별로 음성 프레임 시퀀스 길이가 들쭉날쭉하게 되면 learning rate를 고정한다고 해도 역전파되는 그래디언트의 크기가 불균등해진다.
게다가 RNN 아키텍처 특성상 입력 음성 프레임 시퀀스가 길어질수록 그래디언트 문제가 발생할 수 있다. 이에 저자들은 음성 프레임 길이 순서로 학습 데이터를 정렬한 뒤 미니배치 내 음성 최대 길이가 점차 늘어나게끔 미니배치 인입 순서를 정했다. 저자들은 이 같은 학습 방식을 SortaGrad라고 명명했다.
7. Dataset Construction
학습 데이터의 음성 길이는 짧게는 수분에서 길게는 1시간 이상인 것도 있다. 이를 모델에 통째로 넣고 학습하면 학습이 제대로 될 리가 없다. 적절한 길이로 잘라서 모델에 넣어주어야 한다. 또 어떤 데이터는 음성 전사가 틀린 경우도 있다. 음성과 transcript가 불일치한 케이스는 학습에서 제외해야 한다. 이에 저자들은 데이터 구축을 위한 별도 모델을 만들어 이 문제를 해결했다.
저자들은 alignment 용도로 CTC loss를 적용한 양방향 RNN 레이어 모델을 구축했다. 입력은 파워 스펙트럼, 출력은 문자(grapheme)가 된다. CTC loss는 음성-trascript 쌍만 있으면 학습이 가능하다. 이렇게 학습한 alignment 모델에 학습 데이터의 음성을 집어 넣는다. 모델 출력에 blank 등의 레이블이 지속적으로 출현한다면 해당 구간을 앞뒤로 잘라서 음성을 분리(segmentation)하는 방식이다.
음성과 transcript 사이의 불일치 케이스를 가려내는 분류기 또한 만들었다. 분류기를 구축하는 과정은 이렇다. 우선 크라우드 소싱으로 음성 수천 건에 정답 transcript를 달아놓는다. 그 다음 앞서 만든 alignment 모델에 해당 음성을 넣어서 alignment 예측값을 추출한다. 이 둘의 편집거리(edit distance)를 계산해 alignment가 잘 되었는지(good) 그렇지 않은지(bad) 레이블을 부여한다. 마지막으로 음성 스펙트로그램을 입력으로 하고 good/bad를 출력으로 하는 이진(binary) 분류기를 별도로 학습한다. 이후 전체 학습데이터 음성 스펙트로그램을 이 분류기에 넣어 good으로 예측되는 데이터만 실제 모델 학습에 활용한다.
이밖에 저자들은 학습데이터에 노이즈를 더해(adding noise) 모델의 robustness를 키우려고 했다. 실험 결과 전체 가운데 40%를 랜덤으로 노이즈를 추가해 학습한 경우 인식 성능이 가장 좋았다고 한다. 뿐만 아니라 학습데이터가 클수록 역시 인식 성능이 개선되는 양상을 보였다. 참고로 저자들은 영어 인식기에 1만1940시간의 학습데이터를 사용했다.
8. Experiments
이 챕터에서는 논문에 제시된 여러 실험 결과 가운데 눈에 띄는 일부를 발췌 소개해 본다. 표1은 모델 크기(파라미터 수 3800만)를 고정시킨 상태에서 RNN 레이어 수와 RNN 히든 차원 수에 따른 영어 인식 성능 차이를 나타낸 것이다. 네 개 모델 모두 컨볼루션 레이어(1d)는 1개로 동일하다. 7 RNN, 9 total이라는 말은 9개 레이어 가운데 1개 레이어가 컨볼루션, 7개 레이어가 양방향 RNN, 나머지 1개 레이어가 Fully Connected Layer라는 뜻이다. 표1을 보면 두꺼운(히든이 큰) RNN 모델보다 깊은(레이어가 많은) 모델이 인식 성능이 좋은 걸 확인할 수 있다.****
표1 RNN 깊이, 히든 차원수에 따른 성능 차이
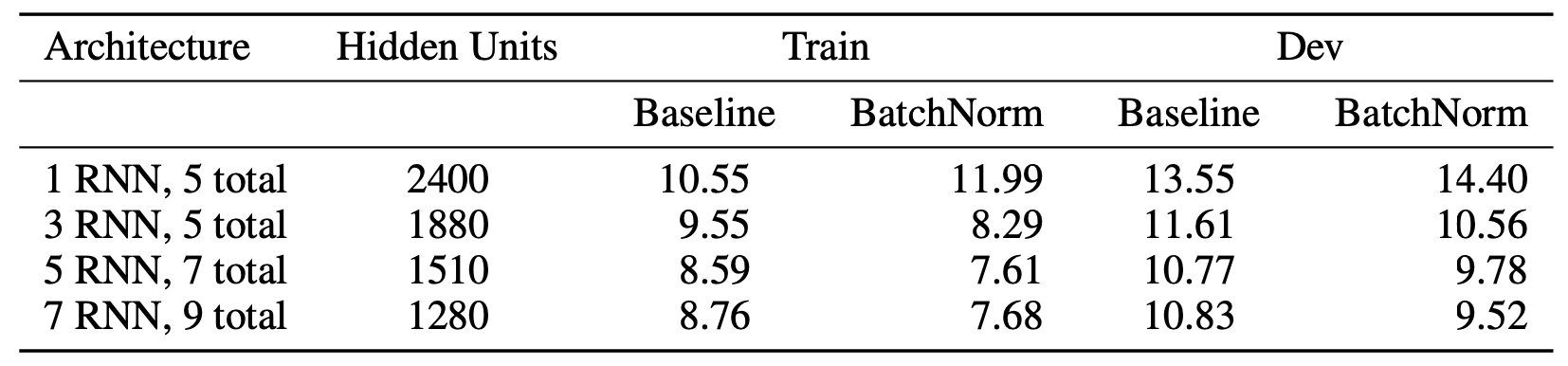
저자들은 RNN 함수 \(g\)를 valilla RNN 혹은 GRU를 적용한 모델을 각각 실험했는데 실험 환경별로 어느 한쪽이 우위를 보인다고 해석하기 어려웠다고 한다.
표2는 컨볼루션 레이어를 어떻게 설정하느냐에 따른 성능 차이를 요약 정리한 표이다. 전반적으로 1d conv보다 2d conv가 인식 성능이 좋다. 다시 말해 음성 입력을 최초로 계산하는 feature extractor 레이어에서는 시간(time)과 주파수(frequency) 도메인 모두 컨볼루션하는 것이 유의미하다는 이야기로 해석할 수 있을 듯하다.
표2 컨볼루션 설정별 성능 차이
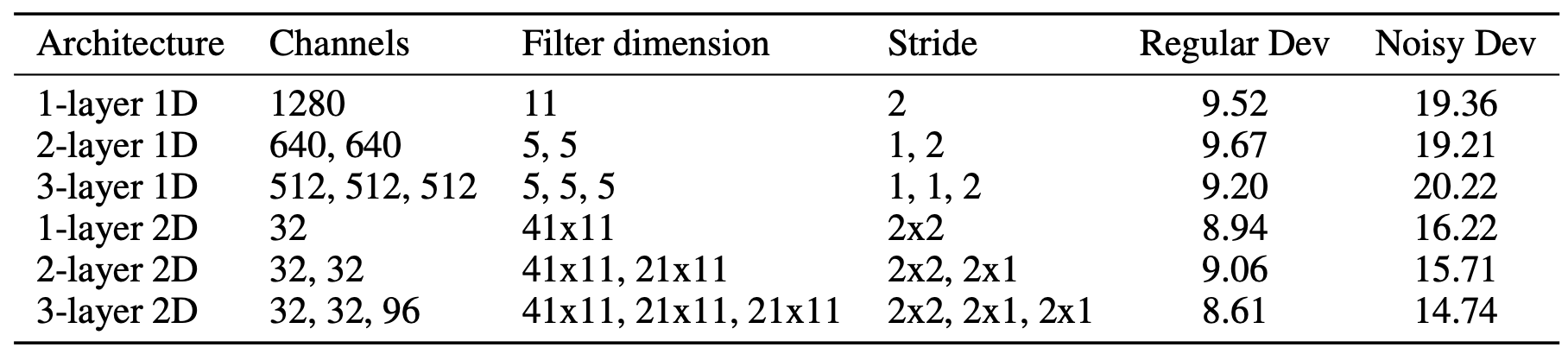
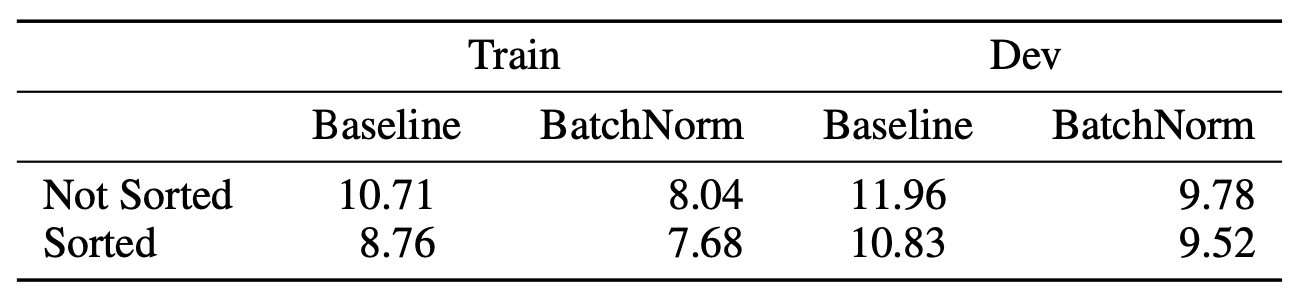
표3은 미니배치를 음성 길이에 따라 정렬해 짧은 것부터 순차적으로 학습한 모델(Sorted)과 그렇지 않은 모델(Not Sorted)의 성능 비교이다. 정렬한 모델의 성능이 훨씬 좋은 걸 확인할 수 있다. RNN + CTC loss로 학습하는 모델에는 미니배치를 음성 길이에 따라 정렬하는 것이 유의미한 효과를 내는 것으로 해석할 수 있다.
표3 SORTAGRAD 효과
저자들이 실험한 결과 테스트 성능 최고점을 기록한 영어 인식기의 구조는 다음과 같다. 아래 모든 레이어에는 Batch Normalization이 적용돼 있다.
- Convoltion Layer: 2D conv, 3개 레이어
- Bidirectional Recuurent Layer: Vanllia RNN, 7개 레이어
- Fully Connected Layer: 1개 레이어