2. Listen, Attend and Spell
Info
Sequence-to-Sequence model 기반 음성 인식 모델 Listen, Attend and Spell(LAS) 기법을 소개한다. LAS는 제안 당시 주류를 이루고 있었던 Hidden Markov Model 기반 기존 음성 인식 시스템과 달리 모든 컴포넌트를 End-to-End로 학습할 수 있어 주목을 받았다. 최근에도 다른 모델 대비 경쟁력 있는 성능으로 각광받고 있는 모델이다.
1. Introduction
Hidden Markov Model 기반 기존 음성 인식 시스템은 다음과 같이 크게 세 가지 요소로 구성돼 있다. 그런데 기존 시스템에서는 이 세 가지 구성요소를 각기 다른 목적함수(objective function)로 독립적으로 학습해야 하는 단점이 있었다.
1] 발음 모델(pronunciation model): 단어(word)를 음소 시퀀스(phoneme sequence)에 매핑해주는 역할을 한다. 기존 음성 인식 시스템에서는 사전(lexicon)이 이 역할을 수행했다.
2] 음향 모델(acoustic model): 음소와 음성 사이의 관계를 추론하는 모델. 기존 시스템에서는 Hidden Markov Model + Gaussian Mixture Model이 이 역할을 수행했다.
3] 언어 모델(language model): 단어 시퀀스의 출현 확률을 부여하는 모델. 기존 시스템에서는 통계 기반의 n-gram 모델이 이 역할을 수행했다.
LAS가 제안될 무렵 위 세 가지 컴포넌트를 하나로 합쳐, 음성과 transcript 간 관계를 End-to-End로 학습하려는 시도가 나타났다. 가장 대표적인 사례가 Connectionist Temporal Classification(CTC) loss이다. 그런데 LAS 저자들은 CTC가 네트워크 출력(word sequence)을 조건부 독립(conditional independence)으로 가정하고 있어 본질적인 문제가 있다고 지적한다.
이에 LAS 저자들은 음성 인식 시스템을 End-to-End로 구축하는 한편 현재 네트워크 출력의 조건부 독립 가정을 제거함으로써 인식 성능을 높이고 현실적인 모델링이 될 수 있도록 아키텍처를 고안하였다. 뿐만 아니라 모델 출력이 문자(character) 단위가 되도록 해 Out-Of-Vocabulary(OOV) 문제를 해결했다고 주장했다.
2. Architecture
LAS 모델 아키텍처는 기계 번역(machine translation)에 자주 쓰였던 Sequence-to-Sequence(S2S) 모델을 기본으로 한다. LAS를 도식적으로 나타낸 그림은 그림1과 같다. S2S 모델의 Encoder에 대응하는 것이 Listener이며 입력된 음성에서 텍스트 정보를 추출하는 역할을 한다. Decoder에 대응하는 모듈은 Speller로 Listener가 압축한 정보를 바탕으로 문자 시퀀스를 생성(generation)하는 역할을 한다.
그림1 LISTEN, ATTEND AND SPELL
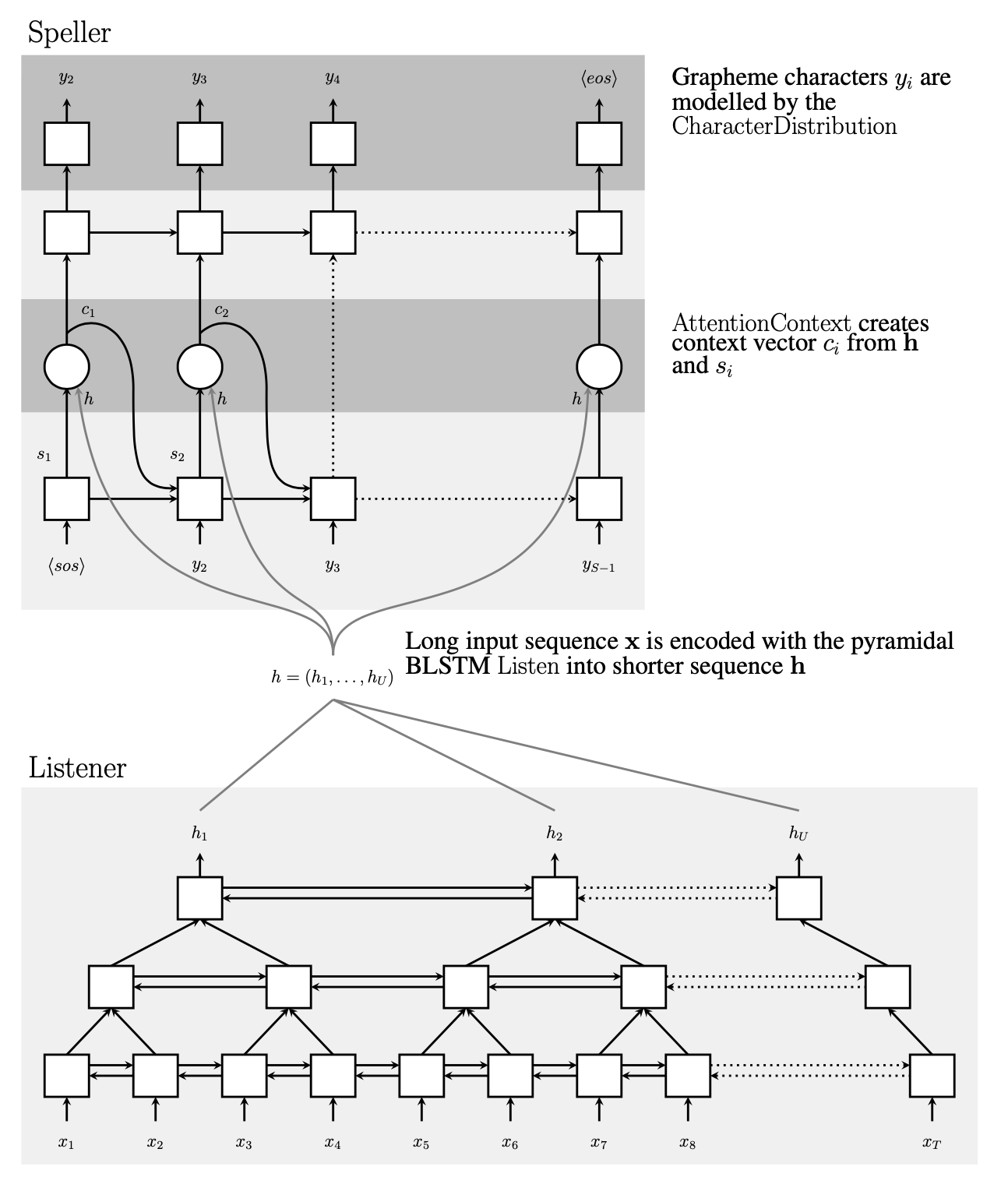
Listener는 피라미드(pyramid) RNN 구조로 돼 있다. 통상적으로 음성 프레임이 너무 많기 때문에, 레이어와 레이어 사이에 프레임 수를 절반씩 줄이는 역할을 수행하도록 했다. 프레임 수가 너무 많으면 Listener가 음성에서 유의미한 정보를 찾아내는 게 어려워진다. 저자들이 실험한 결과 피라미드 RNN 구조를 도입하지 않을 경우 모델의 수렴 속도가 현저하게 느려진다고 한다.
Listener와 Speller 사이를 잇는 것은 어텐션(attention) 모듈이다. 어텐션 모듈은 Speller가 문자 시퀀스를 생성할 때 입력 음성에서 어떤 부분에 집중할지 알려주는 역할을 한다. 저자들에 따르면 어텐션 모듈이 없을 경우 모델이 학습 데이터에 과적합(overfitting)된다고 한다. 그도 그럴 것이 어텐션 모듈이 던져주는 정보가 없다면 Speller 모듈은 Speller의 직전 히든 스테이트 벡터 등 제한된 정보만 바탕으로 다음 글자를 생성해야 한다.
3. Listen
Listener 모듈의 입력은 로그-멜 스펙트럼(log-mel filter banks) 시퀀스이다. Listener 모듈의 핵심은 양방향 피라미드 LSTM인데, 입력 음성 시퀀스 길이를 레이어를 거듭할 때마다 절반씩 줄이는 역할을 수행하는 모듈로 수식1과 같다.
수식1 PYRAMID BIDIRECTIONAL LSTM
수식1 이해를 돕기 위해 그림2를 그렸다. 전형적인 양방향 LSTM 셀은 그림2의 상단과 같다. 순방향 LSTM 셀이라면 \(j\)번째 레이어 \(i\)번째 시점의 히든 스테이트 \(h_{i}^{j}\)는 \(j\)번째 레이어 직전 시점(\(i-1\))의 히든 스테이트와 직전(\(j-1\)) 레이어 현재 시점(\(i\))의 히든 스테이트 두 개의 입력을 받아 계산한다. 이는 역방향 LSTM 셀도 마찬가지이다(저자들은 설명의 편의를 위해 순방향 LSTM 셀 위주로 기술한 듯하다).
그림2 PYRAMID BIDIRECTIONAL LSTM

4. Attend and Spell
수식2는 어텐션 모듈의 도움을 받아 Speller 모듈이 다음 글자를 예측하는 과정을 식으로 나타낸 것이다. 문자 시퀀스 가운데 \(i\)번째 문자(\(y_{i}\))를 예측해야 하는 상황이다. Speller 모듈은 2개의 순방향 LSTM 레이어로 구성돼 있다. \(s_{i}\)는 Speller 모듈의 \(i\)번째 히든 스테이트이다.
수식2 ATTEND AND SPELL
\(**s_{i}\)에는 직전 시점의 음성 어텐션 정보와 처음부터 직전 글자까지의 문자 시퀀스 정보가 포함돼 있다.** 그 이유를 살펴보면 다음과 같다.
1] 직전 시점의 음성 어텐션 정보: 직전 어텐션 컨텍스트(\(c_{i-1}\)) 사용. \(c_{i-1}\)를 만들 때 \(s_{i-1}\)와 Listener 출력인 \(\mathbf{h}\)를 씀. 다시 말해 \(c_{i-1}\)는 Speller의 직전 히든 스테이트(\(s_{i-1}\))와 유의미한 관계를 지니는 음성 정보가 됨.
2] 처음부터 예측 직전 글자까지의 문자 시퀀스 정보: Speller 모듈의 직전 히든 스테이트(\(s_{i-1}\)) 직전 정답(\(y_{i-1}\))이 계산에 포함됨.
Attention Context함수는 \(s_{i}\)와 음성 전체 정보(Listener 출력인 \(\mathbf{h}\))를 입력으로 한다. 그렇다면 \(c_{i}\)는 어떤 정보를 포함하고 있을까? 위에서 만든 Speller의 현재 히든 스테이트(\(s_{i}\))와 유의미한 관계를 지니는 음성 정보일 것이라 추측해볼 수 있다.
마지막으로 Character Distribution 함수를 보자. 이 함수는 선형변환(linear transformation) + 소프트맥스(softmax)로 구성돼 있다. 위에서 계산한 \(s_{i}\)와 \(i\)번째 어텐션 컨텍스트(attention context) 벡터 \(c_{i}\)를 입력받아 \(i\)번째 문자가 나타날 확률 분포를 출력한다.
요컨대 Speller 모듈은 (1) 처음부터 직전 시점의 문자 시퀀스 정보, (2) 이 문자 시퀀스와 유의미한 관계를 지니는 음성 정보 전체를 종합적으로 판단해 다음 글자를 예측한다.
수식3은 어텐션 모듈을 구체적으로 나타낸 것이다. \(e_{i, u}\)는 \(i\)번째 문자와 \(u\)번째 음성 프레임 사이의 스코어(score)를 가리킨다. 이 값이 높을수록 해당 문자와 음성 사이의 관계가 깊다. \(e_{i, u}\)는 Speller 모듈의 직전 히든 스테이트(\(s_{i-1}\))와 Listener 모듈의 히든 스테이트들(\(\mathbf{h}\))을 각각 선형변환한 뒤 내적(inner product)하는 방식으로 계산한다(\(\phi\), \(\psi\))는 모두 Multi-Layer Perceptron).
수식3 ATTENTION MODULE
\(i\)번째 어텐션 컨텍스트(attention context) 벡터 \(c_{i}\)는 Listener 모듈의 히든 스테이트들(\(\mathbf{h}\))에 \(e_{i, u}\)에 소프트맥스(softmax) 함수를 적용한 가중치 \(\alpha\)를 가중합해서 도출한다.
5. Learning
LAS 모델의 학습은 모델의 출력(수식2의 Character Distribution)이 정답 분포와 최대한 가까워지도록 하는 것이다. 이 때 손실 함수로는 크로스 엔트로피(cross entropy)를 쓴다.
그런데 수식2를 보면 현재 글자(\(y_{i}\))의 분포를 예측할 때 직전 글자의 예측이 중요하게 작용함을 알 수 있다. 학습 때는 직전 글자가 무엇인지 정답을 알고 있기 때문에 별 문제가 되지 않지만 인퍼런스(inference) 때는 정답을 모르기 때문에 다소 문제가 될 수 있다.
이 때문에 LAS 저자들은 학습할 때 직전 정답(\(y_{i-1}^{*}\))을 넣어주기도 하고, 직전 모델 예측(Character Distribution \(\hat{y}_{i-1}\))을 넣어주기도 해서 인퍼런스 환경에도 강건한 성능이 유지되도록 하였다.
6. Decoding
학습뿐 아니라 디코딩(decoding) 전략도 인식 성능에 상당한 영향을 끼친다. 대부분의 디코딩은 수식3처럼 음성 입력 \(\mathbf{x}\)가 주어졌을 때 등장 확률을 최대화하는 문자 시퀀스 \(y\)를 예측 결과로 리턴한다.
LAS 저자들은 디코딩 전략으로 beam search를 채택했는데, 매 스텝마다 \(\beta\)개만큼의 시퀀스 후보를 남기면서 디코딩하는 방식이다. 저자들은 시퀀스 후보들 가운데 <EOS>가 나타난 시퀀스를 beam에서 지우고 최종 디코딩 결과 목록(complete hypothesis)에 올린다. 이 목록이 미리 정해둔 개수가 될 때까지 beam search를 계속한다.
수식3 DECODING
디코딩할 때 기존 음성 인식 시스템처럼 언어 모델을 사용할 수 있다. 예측 문자 시퀀스 \(\mathbf{y}\)가 길어질수록 LAS 모델이 예측하는 확률값 \(P(\mathbf{y} \mid \mathbf{x})\)가 작아지므로 그 길이만큼 나눠줘 스케일하고, \(\mathbf{y}\)의 언어 모델 출력값을 스코어에 반영하는 방식이다.
수식4 RESCORING
7. Experiments
LAS 저자들은 2000시간 가량의 영어 데이터셋을 학습 데이터로 사용했다. 노이즈 등을 더해 데이터를 20배 뻥튀기(augmentation)했다. 음성 입력은 10ms 단위로 잘라 40차원의 로그-멜 스펙트럼을 썼다. transcript에 대한 vocabulary는 24개 영어 소문자, 숫자(0~9)에 <sos>, <eos>, <unk>를 포함했다.
Listener는 양방향 피라미드 LSTM 레이어 3개(순방향 히든 256, 역방향 히든 256차원으로 총 512차원), Speller는 순방향 LSTM 레이어 2개(히든 512차원)를 적용했다. 모든 모델 파라미터는 -0.1에서 0.1 범위의 uniform distribution으로부터 샘플링해서 초기화했다고 한다. 배치 크기는 32개이다.
표1은 실험 결과를 나타낸다(Word Error Rate가 낮을수록 좋은 모델). LAS는 End-to-End 모델임에도 불구하고 베이스라인(CLDNN-HMM, 기존 음성 인식 시스템의 일부 컴포넌트를 딥러닝 모델로 대체) 대비 경쟁력 있는 성적을 보이고 있다.
표1 LISTEN, ATTEND AND SPELL
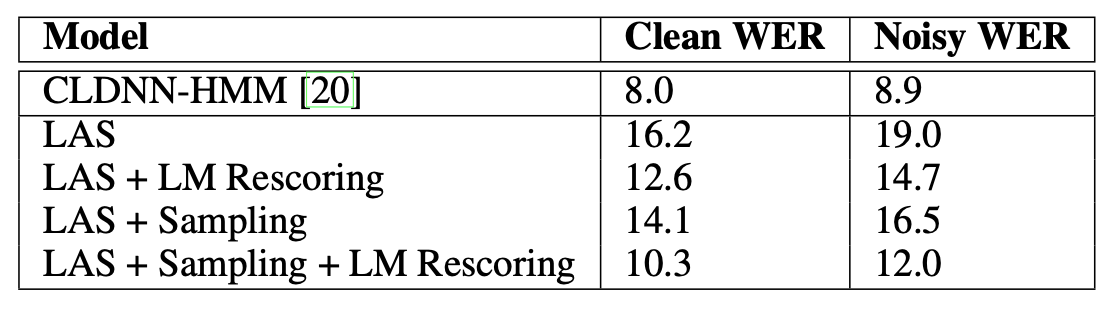
LAS에 Ground Truth 문자들을 계속 넣어 학습하는 것보다는 직전 모델 예측 분포를 넣어 학습(Learning 챕터 참조)하는 Sampling 방식이 점수가 더 좋음을 확인할 수 있다. 디코딩할 때 언어 모델을 반영하는 LM Rescoring 방식이 더 우수한 것 역시 볼 수 있다.
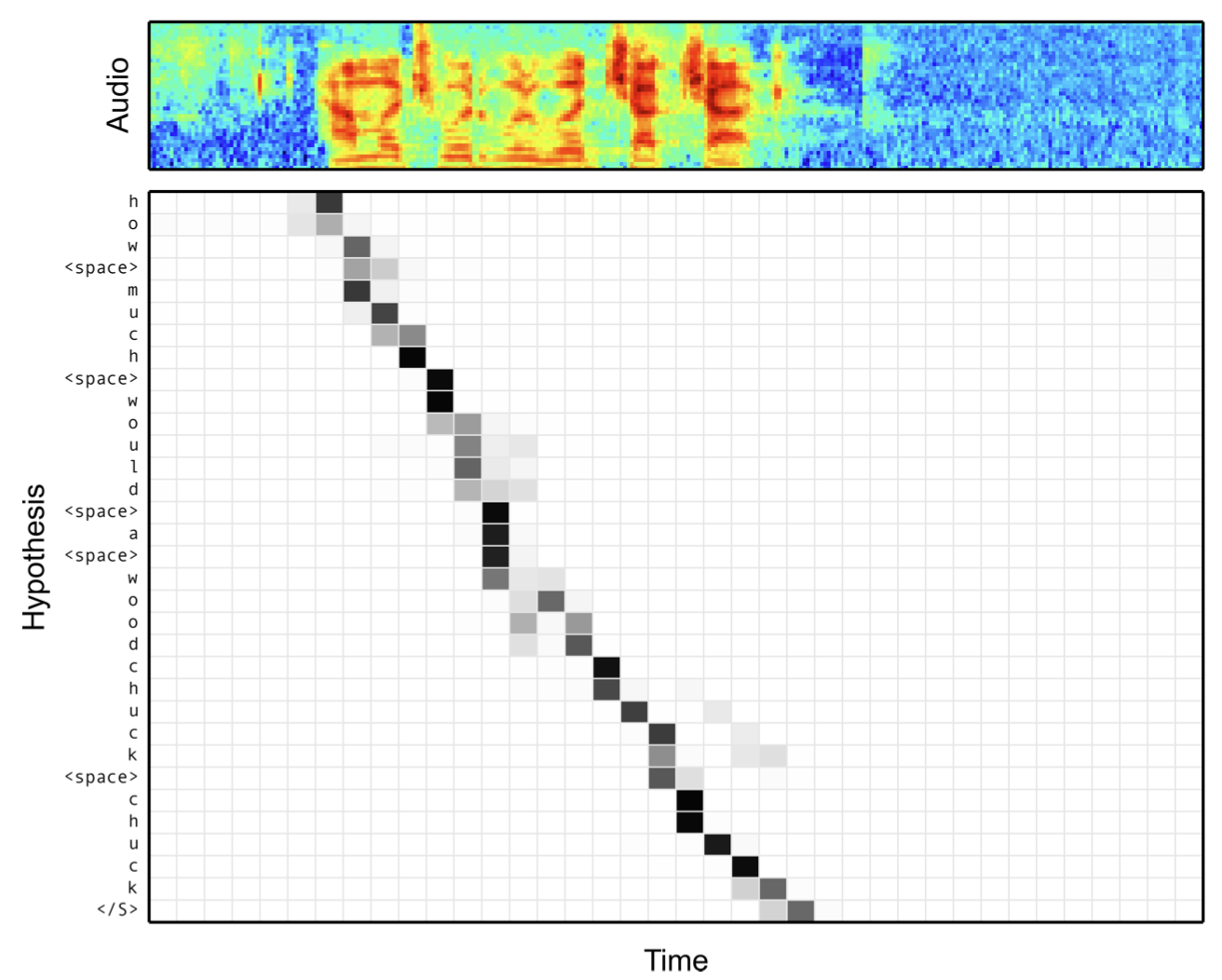
한편 그림2는 음성 입력과 예측 문자 사이의 어텐션 결과를 시각화한 것이다. LAS의 어텐션 모듈이 둘의 관계를 비교적 잘 추출하는 것을 확인할 수 있다.
그림2 LISTEN, ATTEND AND SPELL