1. Neural Acoustic Models
Info
End-to-End 음성 인식 모델의 개괄적인 내용을 소개한다.
1. End-to-End Models
히든 마코프 모델(Hidden Markov Model) + 가우시안 믹스처 모델(Gaussian Mixture Model) 기반 기존 음성 인식 시스템은 음향 모델(Acoustic Model)과 언어 모델(Language Model) 등 주요 컴포넌트를 독립적으로 학습한다. 음운론, 음성학 등 도메인 지식이 요구될 뿐더러 학습에 오랜 시간이 걸린다.
엔드투엔드(End-to-End) 음성 인식 모델은 음성 입력을 받아 단어/음소 시퀀스를 직접적으로 예측하는 모델이다. 엔드투엔드 모델 가운데는 언어 모델 등 기타 컴포넌트의 도움을 받지 않고 모델 하나로 음성 인식 태스크를 수행하는 기법들도 있다. 이 글에서는 엔드투엔드 음성 인식 모델의 세 가지 부류를 차례대로 간단히 살펴본다.
2. Connectionist Temporal Classification
Connectionist Temporal Classification(CTC)은 타겟 단어/음소 시퀀스 간에 명시적인 얼라인먼트(alignment) 정보 없이도 음성 인식 모델을 학습할 수 있는 모델이다. CTC 기법은 모델 마지막인 손실(loss) 및 그래디언트 레이어에 구현되는데, CTC를 이해하기 위해 수식1과 그림1을 보자.
그림1 ALL POSSIBLE PATHS
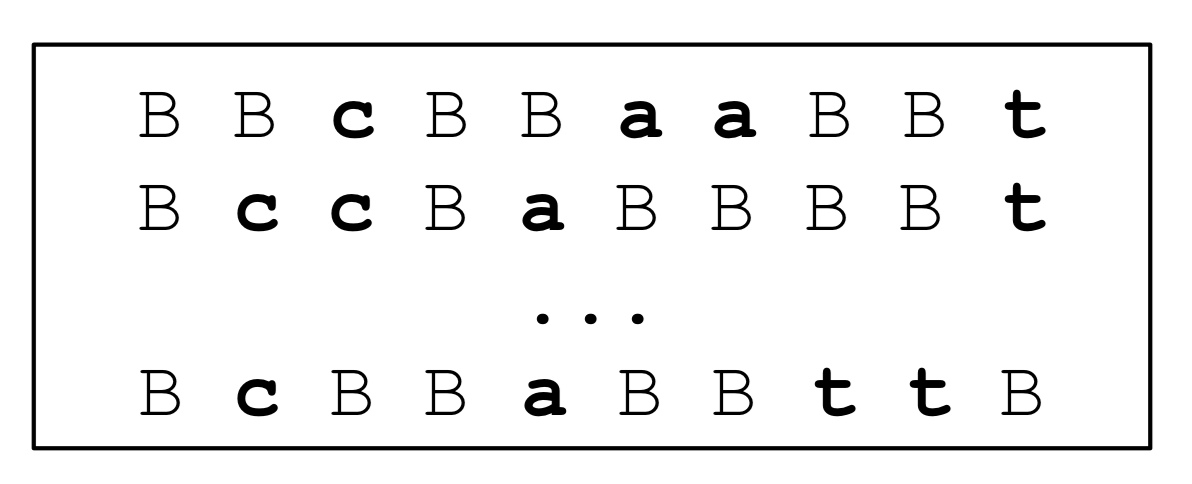
아래 수식1에서 \(\mathbf{x}\)는 음성 인식 모델의 입력 벡터 시퀀스이다. 입력 벡터의 개수는 총 \(T\)개이다. \(\mathbf{y}\)는 정답(음소 혹은 단어) 레이블 시퀀스이다. \(\hat{\mathbf{y}}\)는 음성 인식 모델의 예측(음소 혹은 단어) 레이블 시퀀스이다.
\(\mathcal{B}(\mathbf{y}, \mathbf{x})\)는 정답 레이블 시퀀스 \(\mathbf{y}\)에서 \(B\)(blank)와 중복된 레이블을 허용했을 때 가능한 모든 경로(path)들의 집합을 가리킨다. 예컨대 정답 레이블 시퀀스 \(\mathbf{y}\)가 C, A, T이고 입력 벡터 개수 \(T\)가 10일 경우 \(\mathcal{B}(\mathbf{y}, \mathbf{x})\)는 그림1과 같은 형태가 된다.
그림1 가운데 각각의 라인이 모델 예측 레이블 시퀀스 \(\hat{\mathbf{y}}\)가 될 수 있다. 만일 첫 번째 라인이 \(\hat{\mathbf{y}}\)라면 수식1의 Product값(조건부 \(\mathbf{x}\)는 표기 생략)은 \(P(B) \times P(B) \times P(c) \times P(B) \times P(B) \times P(a) \times P(a) \times P(B) \times P(B) \times P(t)\)가 된다. 이렇게 모든 라인의 값을 구하고 다 더하면 \(P(\mathbf{y} \mid \mathbf{x})\)를 구할 수 있다.
수식1 CONNECTIONIST TEMPORAL CLASSIFICATION
CTC를 활용한 음성 인식 모델을 추상화해 도식화한 것은 그림2와 같다. 벡터 시퀀스 \(\mathbf{x}\)를 입력받아 이를 적당한 히든 벡터(hidden vector)로 인코딩(encoding)한다. 인코딩 역할을 수행하는 레이어는 컨볼루션 뉴럴 네트워크(convolutional neural network)가 될 수도 있고 LSTM/GRU 레이어가 될 수도 있으며 트랜스포머 블록(Transformer block)이 될 수도 있다.
그림2 CONNECTIONIST TEMPORAL CLASSIFICATION

CTC 기법은 모델 마지막 손실(loss) 및 그래디언트(gradient) 계산 레이어에서 실현된다(그림2의 소프트맥스 레이어 상단에 해당). 입력 벡터 시퀀스(\(\mathbf{x}\)) 개수 \(T \times\) 단어 혹은 음소 개수(# of classes) 크기의 소프트맥스 확률 벡터 시퀀스가 CTC 레이어의 입력이 된다. CTC 레이어의 손실 및 그래디언트 계산은 히든 마코프 모델의 Forward/Backward Algorithm을 일부 변형해 수행한다.
CTC 기법을 음성 인식 모델에 적용하면서 명시적인 얼라인먼트 정보가 필요없기 때문에 레이블을 만드는 데 비용을 투자하지 않아도 되는 장점이 있다. 하지만 그만큼 수렴이 어려워 원하는 성능을 내려면 얼라인먼트 정보와 크로스 엔트로피(cross entropy)를 쓰는 다른 모델 대비 많은 데이터가 필요하다고 한다. 수식1에서 확인할 수 있듯 네트워크 출력에 조건부 독립(conditional independence)를 가정하고 있고 언어 모델 도움 없이는 디코딩 품질이 좋지 않다는 단점 역시 있다.
CTC 기법을 적용해 뛰어난 성능을 기록한 아키텍처로는 바이두(Baidu)에서 2015년 발표한 Deep Speech2가 있다.
3. Attention-based Encoder-Decoder Models
Attention-based Encoder-Decoder Model은 모델 내 크게 3가지 구성요소가 있다. 첫 번째는 음성 입력을 히든 벡터로 변환하는 인코더(encoder)이다. 두 번째는 어텐션(attention) 모듈이다. 디코더 출력 시 인코더 입력의 어떤 정보에 집중해야 할지 알려주는 역할을 한다. 마지막으로 타겟 시퀀스를 생성(generation)하는 디코더(decoder)이다. 세 모듈은 각각 기존 음성 인식 시스템에서 음향 모델(Acoustic Model), 음성-음소 간 얼라인먼트 모델(Alignment Model), 언어 모델(Language Model)이 하는 역할과 유사하다고 볼 수 있다.
그림3 ATTENTION-BASED ENCODER-DECODER MODELS

Attention-based Encoder-Decoder Model의 대표 사례가 2015년 구글에서 발표한 Listen, Attend and Spell(LAS)이다. 그림3의 일반적인 구조를 수식2, 그림4에 나와 있는 LAS를 기준으로 설명한다. 그림3, 수식2, 그림4를 동시에 같이 보면서 설명을 보면 편할 것 같다.
LAS의 어텐션 모듈은 수식2이다. 그림4에서는 Listener가 인코더, Speller가 디코더 역할을 수행한다. 여기에서 우리의 관심은 현 시점(\(u\))의 음소/단어를 생성할 때 어텐션 모듈이 참고하는 디코더 정보인 \(\mathbf{h}_{u-1}^{\text {att }}\)이다. 여기에 어떤 정보가 들어가기에 음성-단어/음소 간 얼라인먼트가 되는 것인지 알아보자는 것이다.
수식2 LISTEN, ATTEND AND SPELL (ATTENTION)
\(\mathbf{h}_{u-1}^{\text {att }}\)을 만드는 데 사용되는 정보는 크게 다음 세 가지이다. 예측 시에는 세 정보 모두 디코딩 직전 시점(\(u-1\))에만 관련이 있음을 확인할 수 있다.
- 직전 디코딩 시점(\(u-1\))의 어텐션 결과 \(\mathbf{C}_{u-1}\): 그림4에서
context vector에 해당 - 처음(1)~직전 디코딩 시점(\(u-1\))까지의 디코더 RNN 히든 벡터: 그림4 Speller 모듈의 첫 번째 RNN 레이어의 직전 히든 벡터에 해당
- 현 시점(\(u\))의 디코더 입력: 학습 때는 Ground Truth(\(y_{u}\)), 예측 시에는 직전 시점의 디코더 출력(\(\hat{y}_{u-1}\))
그림4 LISTEN, ATTEND AND SPELL (STRUCTURE)
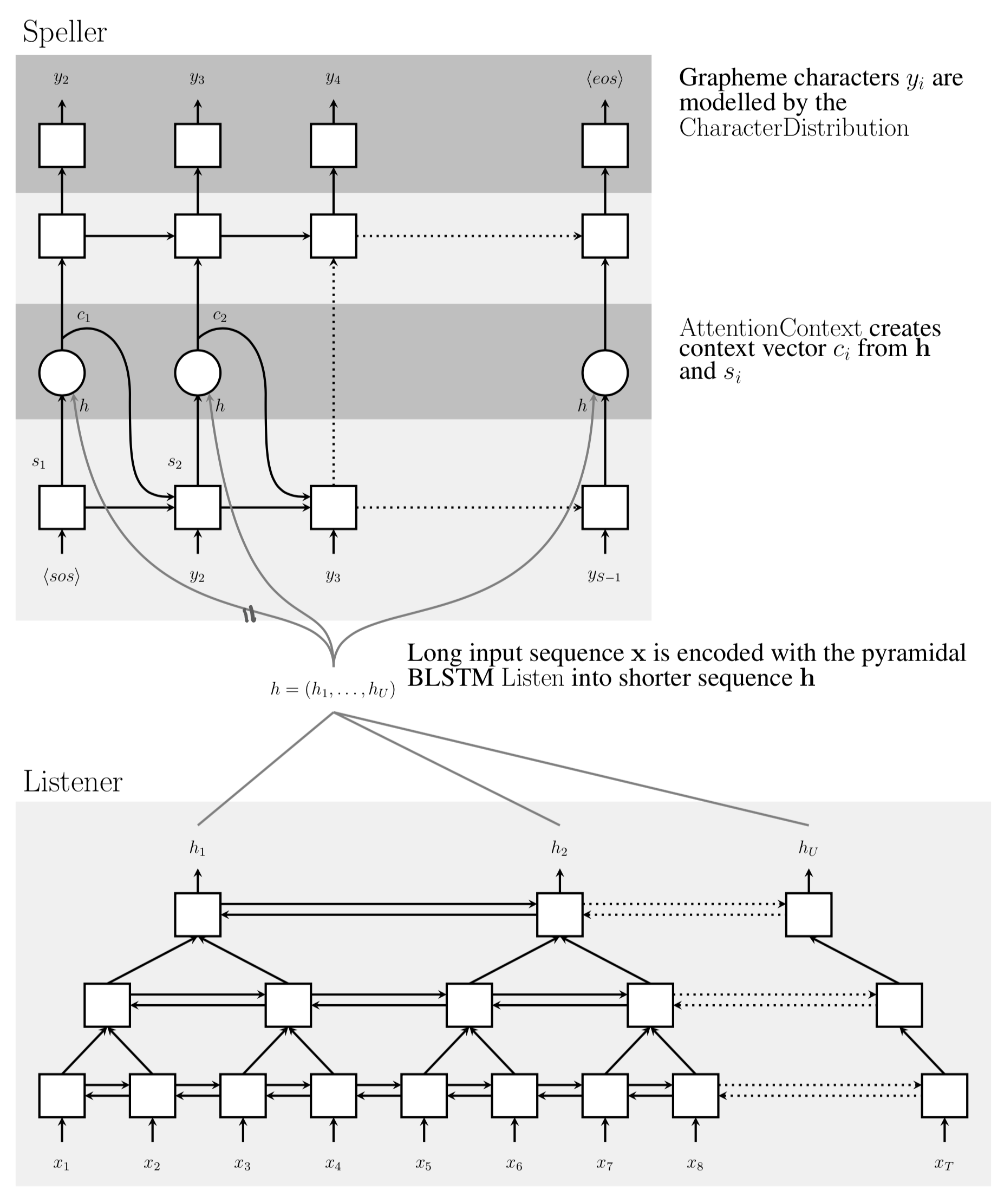
요컨대 LAS의 어텐션 모듈은 인코더의 출력인 음성 입력 정보 전체(\(\mathbf{h}^{\mathrm{enc}}\))와, 처음(1)부터 직전 시점(\(u-1\))에 이르는 디코더 정보(\(\mathbf{h}_{u-1}^{\text {att }}\)) 사이의 유사도를 계산하고 여기에 소프트맥스 함수를 적용한 뒤 이 값을 가중치 삼아 \(\mathbf{h}^{\mathrm{enc}}\)를 가중합하는 역할을 수행한다. 다시 말해 디코더 현재 시점(\(u\))의 예측에 음성 입력들 가운데 어떤 부분에 집중할지(alignment)를 본다는 것이다. 예측 시 LAS의 디코더 모듈은 <EOS> 토큰이 나타날 때까지 단어/음소 예측을 계속하게 된다.
Attention-based Encoder-Decoder Model은 음성 입력 피처 시퀀스 길이 \(T\)와 타겟(단어 혹은 음소) 레이블 시퀀스 길이 \(U\)가 서로 달라도 학습에 문제가 없다. Attention-based Encoder-Decoder Model 역시 CTC 기법과 마찬가지로 음성-단어 간 명시적인 얼라인먼트 데이터가 없이도 학습이 가능하다는 이야기이다.
4. Recurrent Neural Network Transducer
Recurrent Neural Network Trnasducer(RNN-T)는 RNN 기반의 언어 모델(Language Model)에 CTC loss를 적용한 모델이다. RNN-T는 음성 입력이 들어오고 중간에라도 예측이 가능한, 실시간 음성 인식 모델(online model)인데, 그 구조는 그림5와 같다.
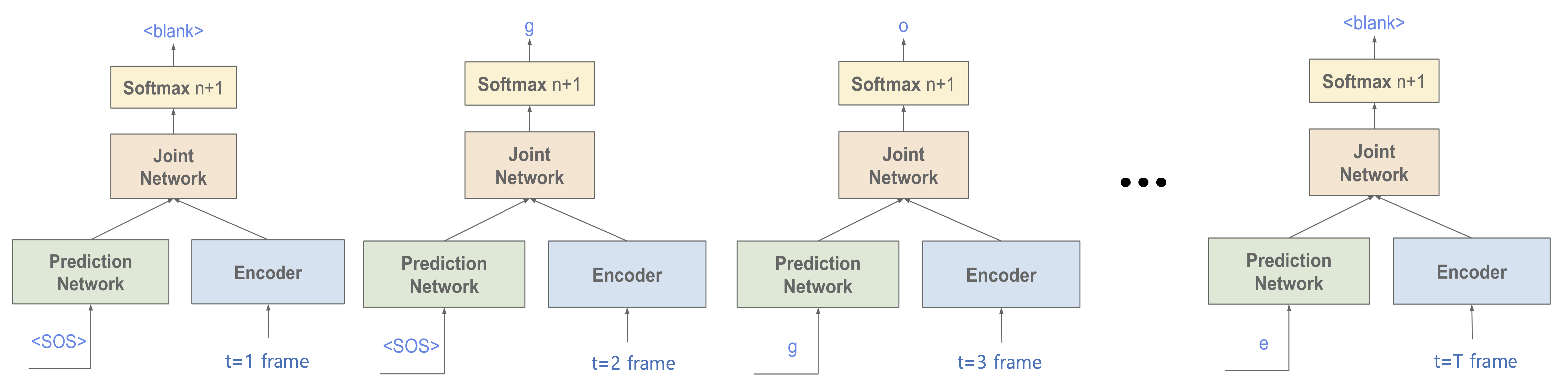
RNN-T는 크게 세 가지 요소로 구성돼 있다. 첫 번째는 인코더 네트워크이다. 처음부터 입력 시퀀스 기준 현재 시점까지의 \(t\)개의 음성 피처 시퀀스를 히든 벡터 \(\mathbf{h}_{t}^{\text {enc }}\)로 인코딩한다. 두 번째는 예측(prediction) 네트워크이다. 처음부터 출력 시퀀스 기준 직전 시점까지의 \(u-1\)개의 출력 단어/음소 시퀀스 정보를 히든 벡터 \(\mathbf{p}_{u}\)로 변환한다. 마지막으로 조인트(Joint) 네트워크는 인코더, 예측 네트워크의 계산 결과를 받아서 \(u\)번째 단어/음성에 관한 로짓(logit) 벡터를 산출한다.
그림5 RECURRENT NEURAL NETWORK TRANSDUCER (1)

그림6은 RNN-T의 인퍼런스 과정을 도식적으로 나타낸 것이다. 음성 입력이 들어오는대로 실시간으로 다음 단어/음소를 예측한다(Blank 포함). 이전에 예측된 단어/음소는 현재 예측 네트워크의 입력으로 들어간다. 음성 입력이 더 이상 없으면 예측을 중단한다.
그림6 RECURRENT NEURAL NETWORK TRANSDUCER (2)
5. Model Comparison
그림7은 Baidu에서 2017년 발표한 논문에서 인용한 것이다. 세 기법 간 차이를 비교적 깔끔하게 정리한 듯 하여 가져와 봤다. 그림7의 가로축은 입력 음성 / 시간(time), 세로축은 출력 단어 / 상태(state)에 대응한다.
수직 방향으로 올라가는 화살표는 한 번에 여러 개의 음소를 예측할 수 있다는 뜻이다. CTC는 이것이 불가능한데, RNN-T와 Attention-based Encoder-Decoder Model에서는 이것이 가능하다.
그림7 COMPARISON

수평 방향으로 움직이는 화살표는 레이블 중복/겹침(CTC)나 아무것(Blank)도 예측하지 않는 걸(RNN-T) 허용했다는 걸 의미한다.
실선 화살표는 hard alignment(CTC, RNN-T), 점선 화살표는 soft alignment(Attention-based Encoder-Decoder Model)을 가리킨다. 마지막으로 Attention-based Encoder-Decoder Model은 다른 모델과 달리 디코딩 시 모든 시점의 입력을 참조할 수 있다.