4. PASE
Info
음성 피처(feature)를 추출하는 뉴럴넷 가운데 하나인, PASE, PASE+ 모델을 살펴본다. 이 모델은 MFCCs(Mel-Frequency Cepstral Coefficients) 같은 음성 도메인의 지식과 공식에 기반한 피처 수준 혹은 그 이상의 성능을 보여 주목받았다. MFCCs는 고정된 형태의 피처인 반면 PASE/PASE+는 학습 가능하기 때문에 태스크에 맞춰 튜닝을 함으로써 해당 태스크의 성능을 더욱 끌어올릴 수 있다는 장점 역시 있다.
1. PASE/PASE+
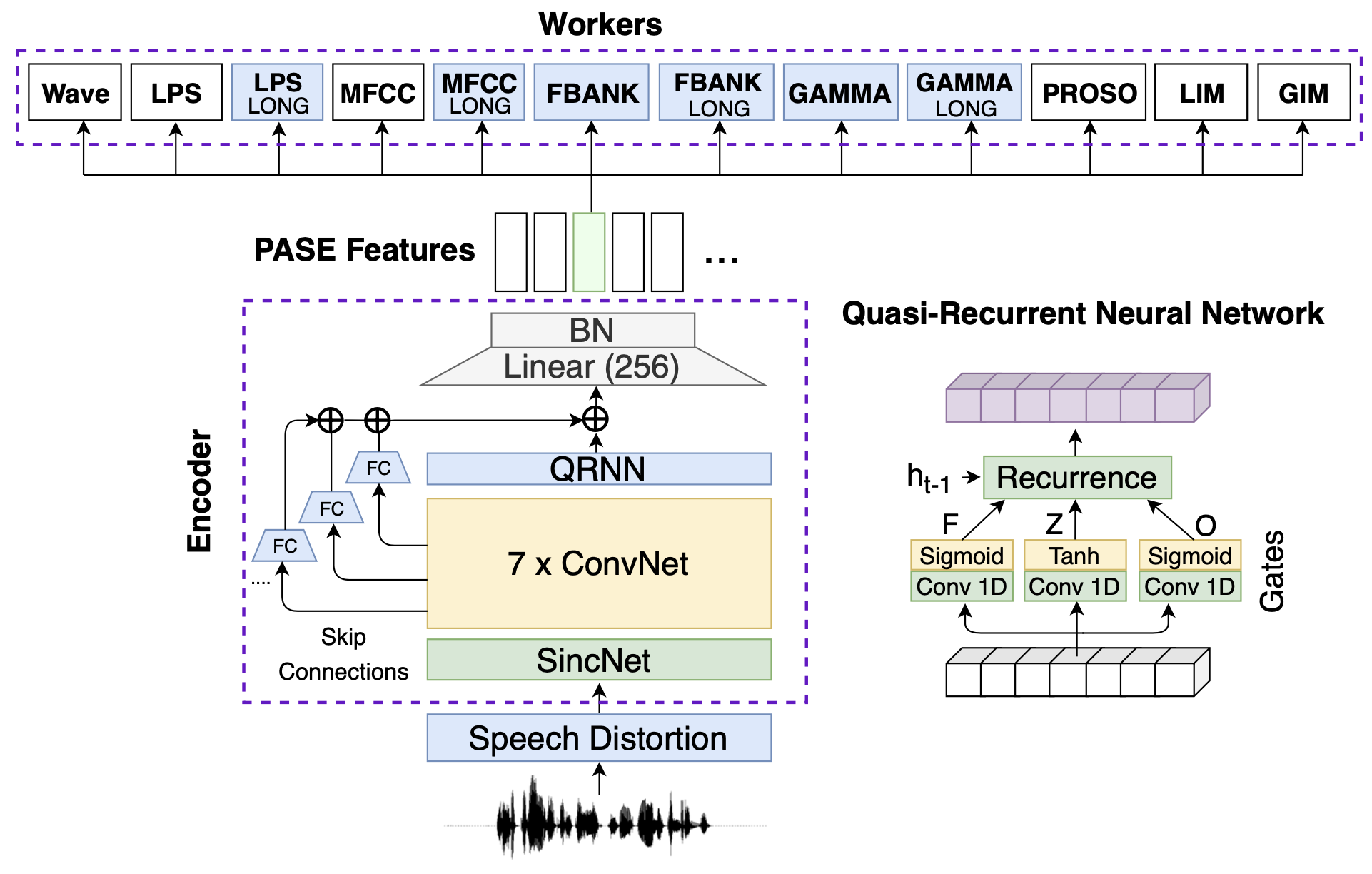
Problem-Agnostic Speech Encoder(PASE)는 싱크넷(SincNet)을 기본 뼈대로 하는 아키텍처이다. 그림1을 보면 싱크넷 위에 7개의 컨볼루션 레이어를 쌓고 1차례의 선형변환(linear transformation)을 수행한 뒤 배치 정규화(Batch Normalization)를 수행하고 있는 걸 볼 수 있다. 저자들은 '싱크넷~배치 정규화'에 이르는 레이어를 인코더(encoder)라고 부르고 있다.
PASE가 싱크넷과 가장 다른 점은 워커(worker)이다. 그림1에서 Waveform, MFCC 등이 바로 그것이다. 이 워커들은 인코더를 학습하기 위해 존재한다. 예컨대 인코더에서 뽑은 100차원짜리 벡터(그림1에서 BN 상단의 녹색으로 칠한 네모)가 있다. 이를 프레임 벡터라고 부르겠다.
그림1 PASE

워커가 Waveform이라고 가정해 보자. 이 경우 PASE의 학습은 마치 오토인코더(autoencoder)처럼 진행된다. 인코더가 원시 음성을 100차원의 히든 벡터(프레임 벡터)로 인코딩하고, 워커가 이를 원래 음성으로 다시 복원하는 셈이기 때문이다.
이번엔 워커가 MFCC라고 가정해 보자. 이 경우 워커는 100차원짜리 프레임 벡터를 해당 프레임의 MFCC가 되도록 변형한다. 만일 Waveform과 MFCC 워커가 제대로 학습이 되었다면 100차원짜리 프레임 벡터에는 원래의 음성 정보와 MFCC 정보가 적절하게 녹아들어 있을 것이다.
PASE 학습이 끝나면 워커를 제거하고 인코더만 사용한다. 이 인코더는 원시 음성의 다양하고 풍부한 정보를 추출할 수 있는 능력이 있다. 워커 덕분이다. 아울러 이 인코더는 딥러닝 기반의 모델로 다른 태스크를 수행할 때 같이 학습도 할 수 있다는 장점도 있다.
그림2는 PASE의 개선된 버전인 PASE+이다. PASE 대비 워커의 종류가 늘었고 인코더 구조를 개선하였다. 이 글 나머지에서는 그림2의 PASE+를 기준으로 설명한다.
그림2 PASE+
2. Encoder
그림3은 PASE+ 인코더 구조를 도식화한 것이다. 우선 원시 음성을 입력으로 받는다. 단 강건한(robust) 피처 추출기를 만들기 위해 각종 노이즈를 추가한다(speech distortion). 음성 피처가 아키텍처와 처음 만나는 곳은 싱크넷(SincNet)이다. 정확히는 싱크넷에서 SincConv에 해당한다. 컨볼루션 필터가 싱크 함수(sinc function)인 1D conv 레이어를 가리킨다.
그림3 ENCODER
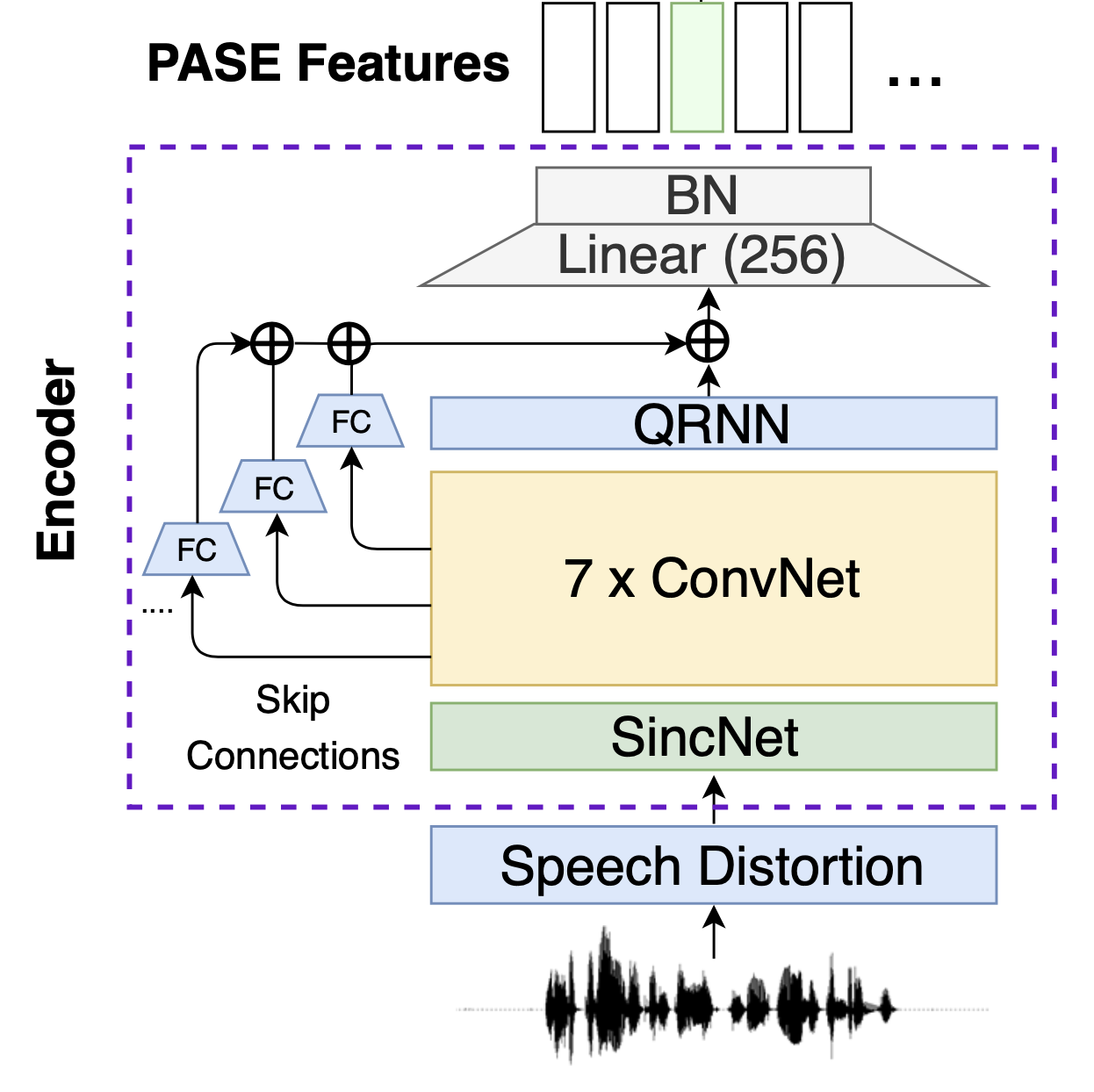
싱크넷 이후로는 7개의 1D conv 레이어를 쌓는다. 원시 음성은 그 길이가 대단히 길기 때문에(Sample rate가 16KHz고 2초짜리 음성일 경우 그 길이만 32000) 적절하게 줄여줄 필요가 있다. 컨볼루션 필터 길이와 stride 등을 잘 주면 꽤 효과적으로 그 길이를 줄일 수 있다. 7개의 컨볼루션 레이어는 바로 이런 역할을 수행한다.
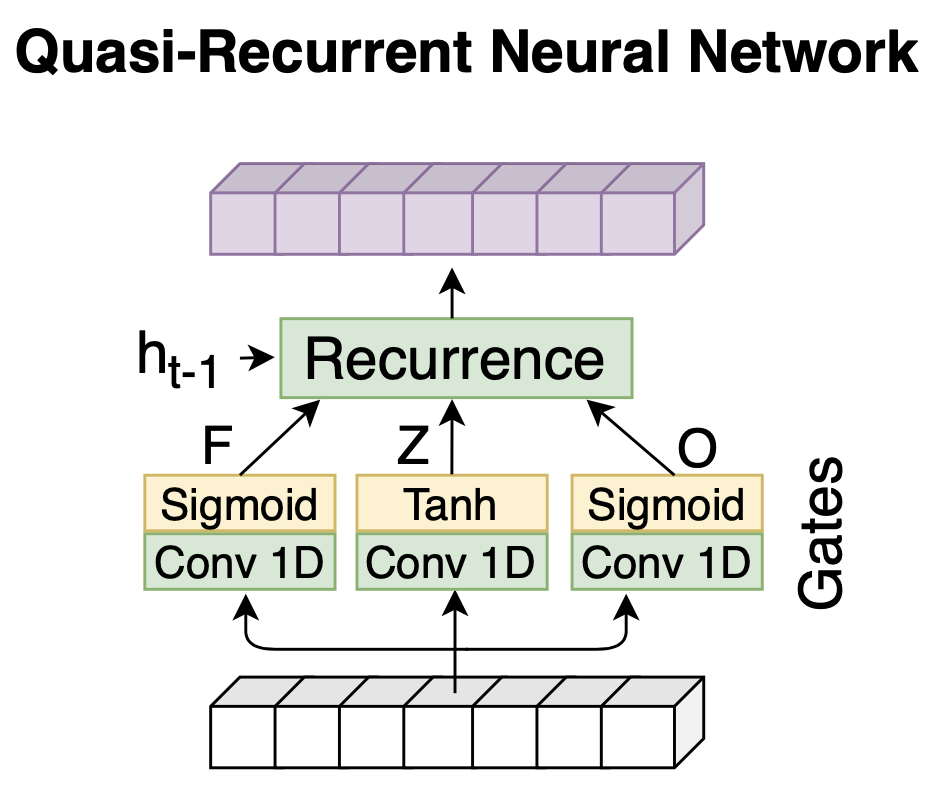
PASE+ 인코더에는 Quasi-Recurrent Neural Network(QRNN)이라는 특이한 구조가 존재한다. 수식1을 보면 그 계산 과정이 LSTM과 유사하다는 걸 알 수 있다. 그런데 \(f\), \(o\) 따위를 만들 때 1D Conv를 사용하고 있다. 다시 말해 \(h_{t}\), \(c_{t}\)를 계산할 때 해당 시점의 \(f_{t}\), \(o_{t}\)를 그때그때 계산하는 게 아니라, 이미 모두 계산이 마쳐진 행렬 형태의 \(F\), \(O\)로부터 \(t\) 시점의 벡터 부분을 참조한다는 것이다.
수식1 QUASI-RECURRENT NEURAL NETWORK
다시 말해 QRNN은 현재 시점의 \(h_{t}\), \(c_{t}\)를 계산할 때 직전 계산 결과에 의존하지 않는다. 따라서 LSTM처럼 시퀀셜한 정보를 캐치하면서도 병렬 처리가 가능해진다.
그림4 QUASI-RECURRENT NEURAL NETWORK
PASE+ 인코더의 특징 가운데 하나는 1D conv 레이어에 관한 skip connection이다. 1D conv 레이어 출력에 이같이 skip connection을 도입한 이유는 PASE+ 인코더의 최종 산출물에 다양한 추상화 수준의 음성 피처를 반영하기 위함이다. 비유하자면 마을 사진을 찍을 때 1m, 10m, 100m 상공 각각에서 관찰한 모든 결과를 반영하는 셈이다. skip connection에 Fully Connected Layer가 끼어있는 건 QRNN의 출력과 차원수를 맞춰주기 위해서이다.
PASE+ 인코더 말단엔 256차원의 선형변환과 배치 정규화(batch normalization) 레이어가 있다.
3. Speech Distortion
PASE+ 인코더 학습을 위해 여섯 가지 노이즈 추가 기법이 적용됐다. 인코더 피처 추출에 일반화(generalization) 성능을 높이기 위해서이다. 다음과 같다.
- Reverberation: 잔향(殘響)은 소리를 내고 있다가 소리를 끊었을 때 해당 소리가 차츰 감쇄해 가는 현상이다. 입력 음성에 잔향이 발생한 것처럼 노이즈를 준다.
- Additive Noise: 알람, 노크 등 노이즈를 더해(add) 입력 음성에 추가한다.
- Frequency Mask: 입력 음성의 특정 주파수 밴드를 제거한다.
- Temporal Mask: 입력 음성의 연속 샘플을 0으로 치환한다(=특정 시간대 제거).
- Clipping: 입력 음성 샘플을 랜덤하게 제거한다.
- Overlap Speech: 입력 음성과 다른 음성을 더해 노이즈를 준다.
4. Worker
PASE+의 워커는 회귀(regression) 혹은 이진 분류(binary classification)를 수행한다. 워커는 대부분 작은 크기의 피드포워드 뉴럴 네트워크(feed-forward network)이다. 워커는 인코더를 학습하기 위한 용도로, 학습이 끝난 후 제거하고 인코더만 음성 피처 추출기로 쓴다.
PASE+엔 7가지의 워커가 있는데, 우선 회귀 태스크를 수행하는 5가지 워커 각각이 수행하는 태스크와 학습 방법은 다음과 같다.
- Wave: 입력 음성으로 복원한다. 워커의 출력과 입력 음성 사이의 Mean Squared Error(MSE)를 최소화하는 방향으로 모델을 업데이트한다.
- Log Power Spectrum: 입력 음성의 Log Power Spectrum으로 변환한다. 워커의 출력과 입력 음성의 Log Power Spectrum 사이의 MSE를 최소화하는 방향으로 모델을 업데이트한다.
- MFCC: 입력 음성의 MFCC로 변환한다. 워커의 출력과 입력 음성의 MFCC 사이의 MSE를 최소화하는 방향으로 모델을 업데이트한다.
- FBANK: 입력 읍성의 Filter Bank로 변환한다. 워커의 출력과 입력 음성의 Filter Bank 사이의 MSE를 최소화하는 방향으로 모델을 업데이트한다.
- GAMMA: 입력 음성의 Gammatone feature로 변환한다. 워커의 출력과 입력 음성의 Gammatone feature 사이의 MSE를 최소화하는 방향으로 모델을 업데이트한다.
- Prosody features: 입력 음성의 prosody feature로 변환한다. prosody feature는 음성의 강세, 억양 등에 영향을 주는 값들을 가리키는데, 음성 프레임 단위로 prosody feature를 추출할 수 있다. prosody feature에는 해당 프레임 기본 주파수(fundamental frequency)의 로그값, voiced/unvoiced 확률, zero-crossing rate, 에너지(energy) 등이 있다. 기본 워커의 출력과 입력 음성 각각의 prosody feature 사이의 MSE를 최소화하는 방향으로 모델을 업데이트한다.
이진 분류 태스크를 수행하는 워커는 2가지이다. 두 개의 입력 쌍(pair)이 포지티브 샘플(positive sample)의 관계인지 네거티브 샘플(negative sample)의 관계인지 맞추는 과정에서 학습한다. 우선 입력 쌍 가운데 하나(anchor sample)는 PASE+ 인코더 출력 프레임 벡터들 가운데 랜덤으로 추출하고, 나머지 샘플(포지티브, 네거티브 입력)을 뽑는 방법은 다음과 같다.
- Local Info Max: 포지티브 샘플은 앵커 샘플과 같은 문장에서 랜덤으로 뽑는다. 네거티브 샘플은 앵커 샘플과 다른 배치에서 랜덤으로 뽑는다. 포지티브 샘플은 앵커 샘플과 동일한 화자(speaker), 네거티브 샘플은 다른 화자일 가능성이 높다. LIM 워커는 PASE+ 인코더로 하여금 화자를 구분하는 능력을 부여해 준다.
- Global Info Max: 앵커 샘플은 랜덤으로 뽑되 2초 간의 PASE+ 프레임 벡터의 평균을 취한다. 포지티브 샘플은 앵커와 같은 문장에서 뽑되 역시 2초 간 평균을 취한다. 네거티브 샘플은 앵커와 동일한 배치 내 다른 문장에서 뽑되 2초 간 평균이다. GIM 워커는 문장의 경계를 인식하게 한다.
5. Performances
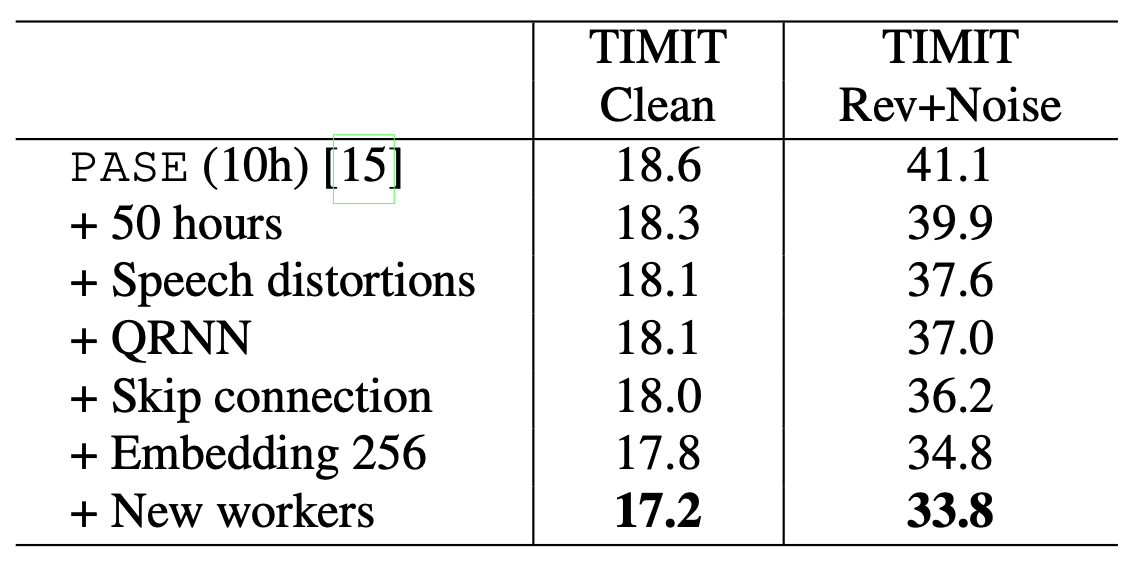
PASE+의 음성 피처 성능은 표1, 표2와 같다. 표1, 표2 모두 Phone Error Rate로 낮을수록 좋은 모델이라는 뜻이다. 표1을 보면 전통의 강자인 MFCC나 Filter Bank 성능보다 좋다.
표1 PASE+
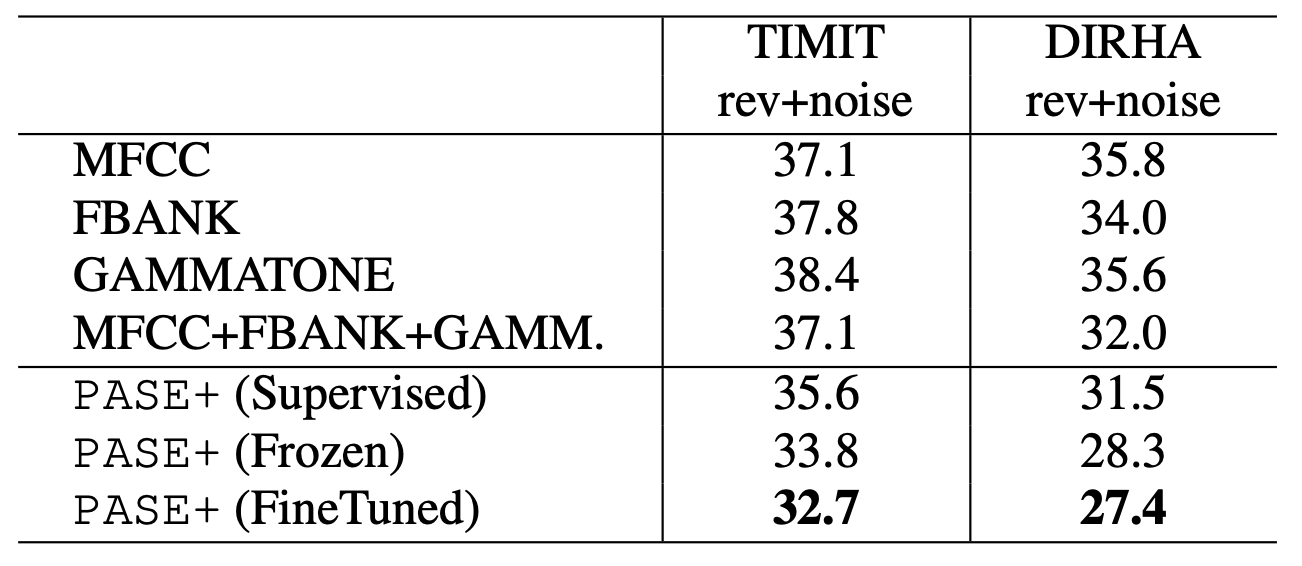
표2는 ablation study 결과이다. 지금까지 언급한 Speech Distortion, QRNN, Skip Connection, 워커 등이 피처 품질 개선에 기여하고 있음을 확인하고 있다.
표2 PASE+