3. SincNet
Info
뉴럴 네트워크 기반 피처 추출 기법 가운데 하나인 SincNet 모델을 살펴본다. SincNet은 벤지오 연구팀이 2018년 발표한 SPEAKER RECOGNITION FROM RAW WAVEFORM WITH SINCNET 논문에서 제안됐는데, 음성 피처 추출에 유리한 컨볼루션 신경망(Convolutional Neural Network)의 첫 번째 레이어에 싱크 함수(sinc function)를 도입해 계산 효율성과 성능 두 마리 토끼를 잡아서 주목받았다.
1. 모델 개요
SincNet 모델 개요는 다음과 같다. 저자들은 음성 피처 추출에 첫 번째 레이어가 가장 중요하다고 보고 해당 레이어에 싱크 함수(sinc function)로 컨볼루션 필터를 만들었다. 이들 필터들은 원래 음성(raw waveform)에서 태스크 수행에 중요한 주파수 영역대 정보를 추출해 상위 레이어로 보낸다.
그림1 SINCNET
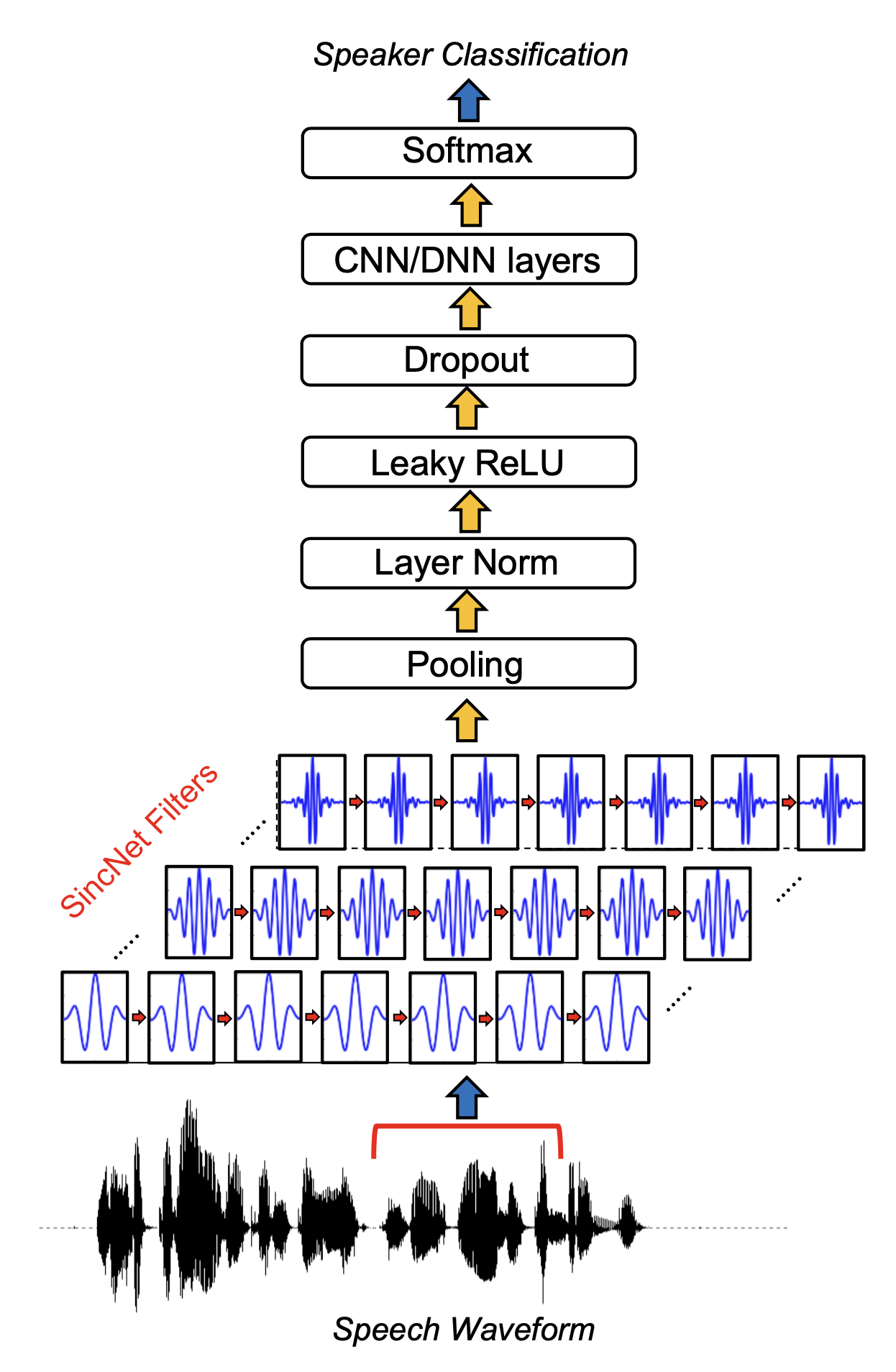
그 위 레이어들은 여느 뉴럴넷에 있는 구조와 별반 다르지 않고, 화자(speaker)가 누구(index)인지 맞추는 과정에서 SincNet이 학습된다. SincNet 모델을 이해하기 위해서는 시간(time) 도메인에서의 컨볼루션 연산 개념을 이해할 필요가 있다. 다음 장에서 차례대로 살펴본다.
2. 시간 도메인에서의 컨볼루션 연산
시간 도메인에서의 컨볼루션 연산의 정의는 다음 수식1과 같다. \(x[n]\)은 시간 도메인에서의 \(n\)번째 raw wave sample, \(h[n]\)은 컨볼루션 필터(filter, 1D 벡터)의 \(n\)번째 요소값, \(y[n]\)은 컨볼루션 수행 결과의 \(n\)번째 값을 각각 가리킨다. \(L\)은 필터의 길이(length)를 나타낸다.
수식1 시간 도메인에 대한 컨볼루션 연산
예컨대 필터 길이 \(L\)이 3이라면 수식1에 따라 계산되는 과정은 다음과 같을 것이다.
수식2 컨볼루션 연산 예시
이렇게 보면 정말 이해하기 어렵다. 그림으로 이해해 보자. 일단 입력 음성 시그널이 그림2, 컨볼루션 필터가 그림3과 같다고 하자.
그림2 INPUT WAVEFORM 예시
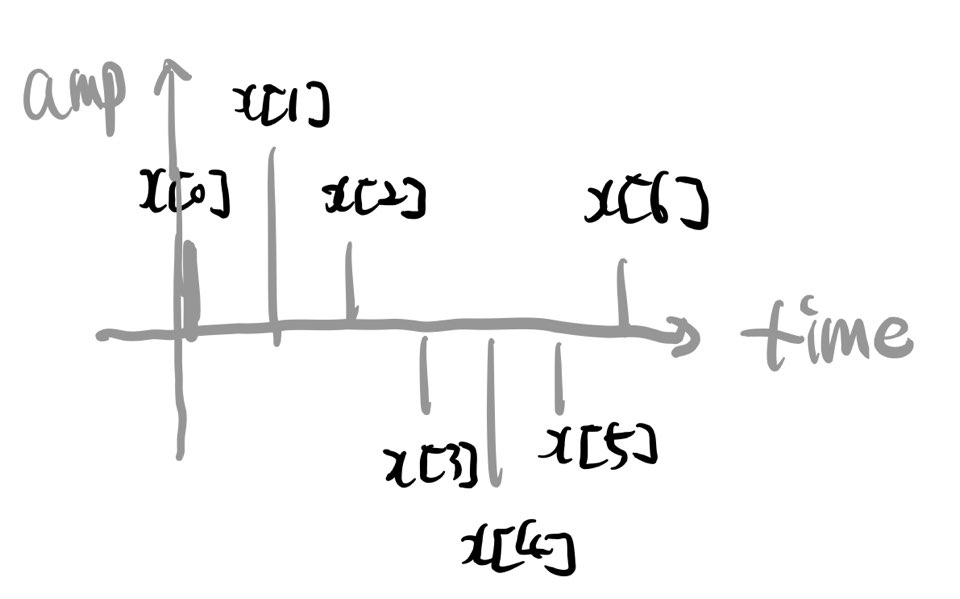
그림3 컨볼루션 필터 예시
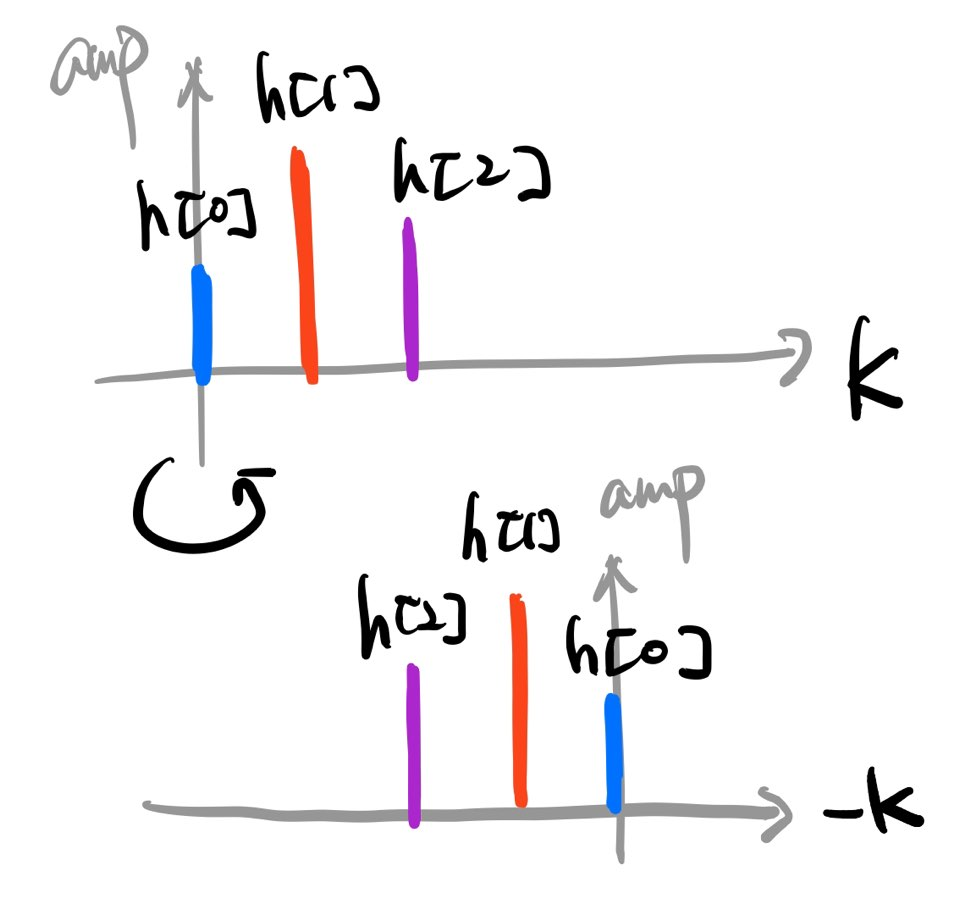
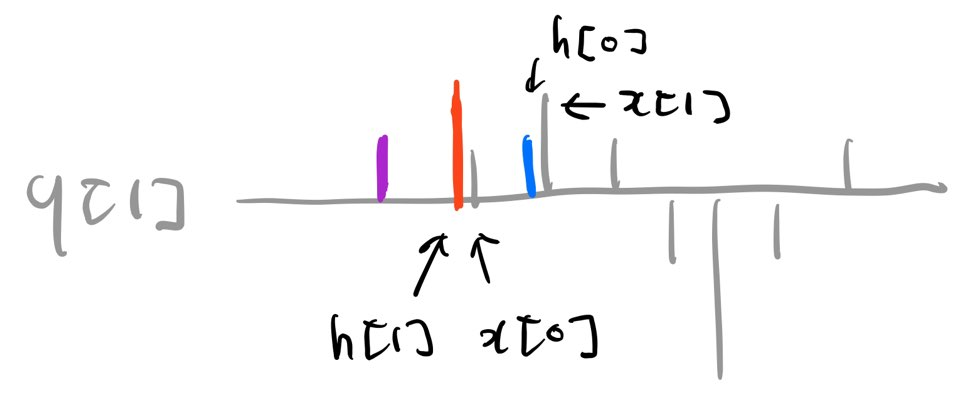
컨볼루션 연산은 컨볼루션 필터를 Y축을 기준으로 뒤집어 필터 \(h\)와 입력 \(x\)를 내적(inner product)하는 것과 같다. 그림4를 수식2와 비교해서 보면 정확히 들어맞음을 확인할 수 있다.
그림4 컨볼루션 연산 예시
컨볼루션 연산 결과물인 \(y\)는 입력 시그널 \(x\)와 그에 곱해진 컨볼루션 필터 \(h\)와의 관련성이 높을수록 커진다. 혹은 특정 입력 시그널을 완전히 무시할 수도 있다. 다시 말해 컨볼루션 필터는 특정 주파수 성분을 입력 신호에서 부각하거나 감쇄시킨다는 것이다.
컨볼루션 연산을 좀 더 직관적으로 이해해 보기 위해 그림5를 보자. 예컨대 시간 도메인에 적용되는 컨볼루션 필터가 그림5 하단 중앙처럼 되어 있다고 가정해 보자. 지금까지 설명했던 컨볼루션 연산 과정을 감안하면 이 컨볼루션 필터는 입력 시그널 \(x\)를 가감 없이 그대로 통과시키게 될 것이다. 이를 주파수 도메인에서 생각해보면 그림5의 상단처럼 연산이 이뤄진다. 다시 말해 시간(time) 도메인에서의 컨볼루션(convolution) 연산은 주파수(frequency) 도메인에서의 곱셈(multiplication) 연산과 동일하다는 것이다.
그림5 주파수 도메인의 곱셈 VS 시간 도메인의 컨볼루션 (1)
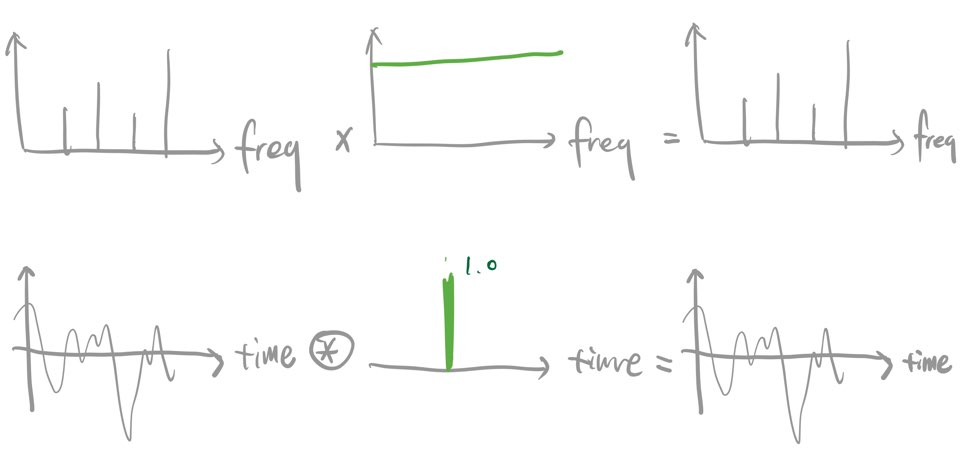
또다른 예시를 보자. 그림6과 같은 구형 함수(rectangular function)를 주파수 도메인에서 입력 신호와 곱하면(multiplication) \(f_{1}\)과 \(f_{2}\) 사이의 주파수만 남고 나머지는 없어질 것이다(그림6의 상단). 이는 시간 도메인에서 싱크 함수(sinc function)으로 입력 신호에 컨볼루션(convolution) 연산을 수행한 결과에 대응한다(그림6의 하단).
그림6 주파수 도메인의 곱셈 VS 시간 도메인의 컨볼루션 (2)

3. Bandpass Filter: Sinc Function
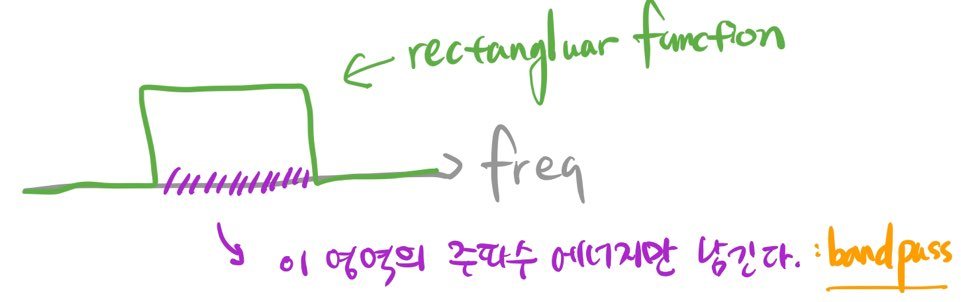
우리는 음성 신호 \(x\) 가운데 화자 인식 등 문제 해결에 도움이 되는 주파수 영역대(band)는 살리고, 나머지 주파수 영역대는 무시하길 원한다. 이렇게 특정 주파수 영역대만 남기는 역할을 하는 함수를 bandpass filter라고 부른다. 주파수 도메인에서 이런 역할을 이상적으로 할 수 있는 필터의 모양은 그림7처럼 사각형(Rectangular) 모양일 것이다.
그림7 BANDPASS FILTER
이때 싱크 함수라는게 제법 요긴하게 쓰인다. 주파수(frequency) 도메인에서 구형 함수(Rectangular function)으로 곱셈 연산을 수행한 결과는 시간(time) 도메인에서 싱크 함수로 컨볼루션 연산을 적용한 것과 동치(equivalent)이기 때문이다. SincNet 저자들이 첫 번째 컨볼루션 레이어의 필터로 싱크 함수를 사용하고 모델 이름도 SincNet이라고 지은 이유이다. 싱크 함수와 구형 함수의 식은 각각 수식3, 수식4와 같다.
수식3 싱크 함수
수식4 구형 함수
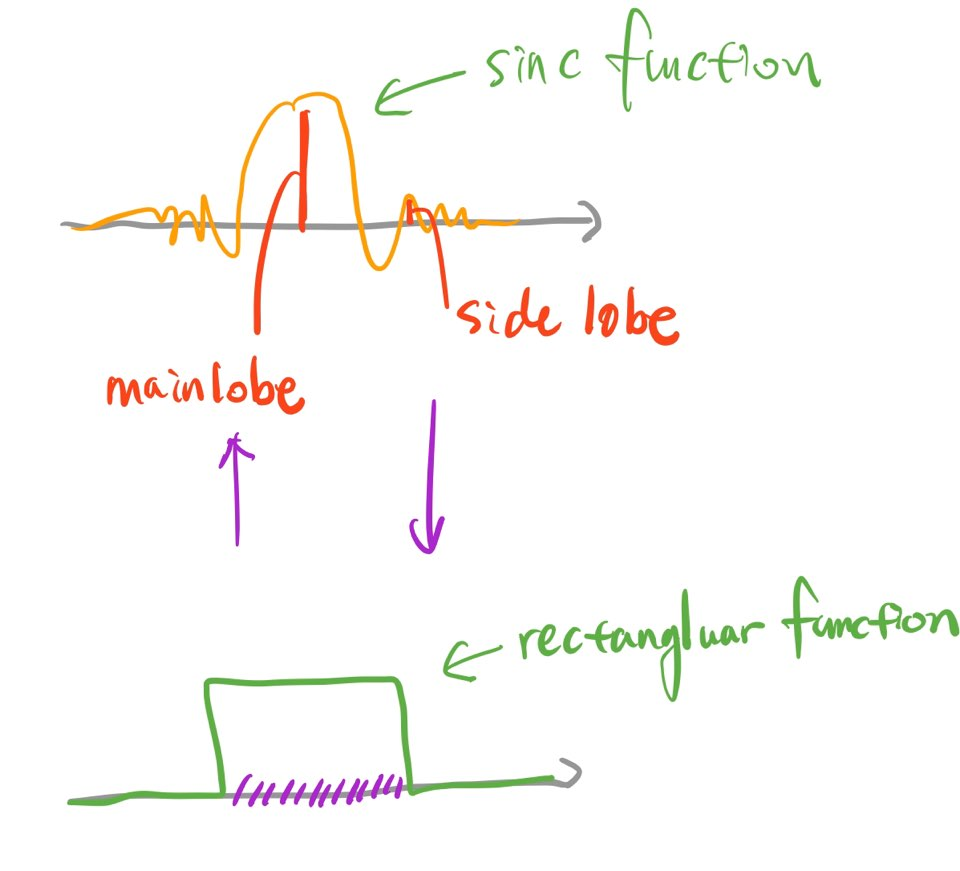
그림8을 보면서 조금 더 자세히 살펴보자. 싱크 함수를 푸리에 변환(Fourier Transform)한 결과는 구형 함수가 된다(수식5, 단 여기에서 싱크 함수는 정규화된 싱크 함수[normalized sinc function]). 이 구형 함수를 역푸리에 변환(Inverse Fourier Transform)하면 다시 싱크 함수가 된다.
그 역도 성립한다. 구형 함수를 푸리에 변환한 결과는 싱크 함수가 된다(수식6). 이 싱크 함수를 역푸리에 변환을 하면 다시 구형 함수가 된다. 요컨대 두 함수는 푸리에 변환을 매개로 한 쌍을 이루고 있다는 이야기이다. 그 관계는 다음 그림8과 같으며 구형 함수의 정의는 수식4와 같다.
그림8 싱크/구형 함수의 관계
Note
그림8 상단의 각각의 봉우리를 lobe라고 한다. 가장 높은 봉우리(main lobe)는 해당 컨볼루션 필터가 주로 잡아내는 주파수 영역대가 된다. 하지만 이것 말고도 작은 봉우리(side lobe)들이 많다. 작은 봉우리들이 많은 필터로 입력 신호를 컨볼루션을 하면 우리가 주로 포착하고 싶은 주파수 영역대 이외에 불필요한 주파수 영역대 정보도 살아남아 노이즈로 작용할 수 있다. 이를 side lobe effect라고 한다. 컨볼루션 필터 혹은 싱크 함수의 길이 \(L\)이 길어질수록 그 효과는 커진다고 한다.
수식5 싱크 함수의 푸리에 변환
수식6 구형 함수의 푸리에 변환
한편 설명의 편의를 위해 시간 도메인/싱크 함수, 주파수 도메인/구형 함수을 한 묶음으로 표현했으나 주파수 도메인에서 싱크 함수를, 시간 도메인에서 구형 함수를 정의할 수 있다. 이렇게 도메인이 바뀐 상태에서도 역시 싱크/구형 함수는 푸리에 변환을 매개로 한 쌍을 이룬다.
4. Windowing: Hamming Window
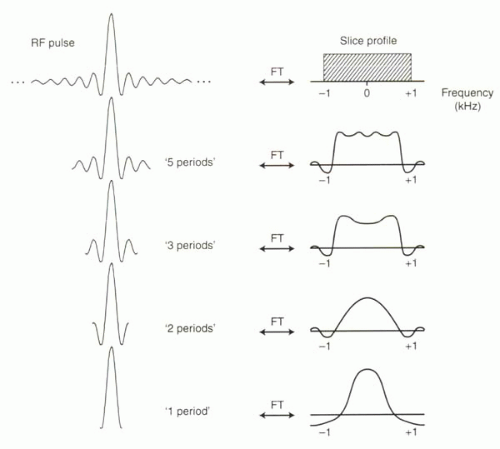
수식5에서 알 수 있듯 싱크 함수에 푸리에 변환을 적용해 완전한 형태의 구형 함수를 얻어내려면 해당 싱크 함수의 길이 \(L\)이 무한해야 한다(수식5 적분 구간 참조). SincNet 저자들은 시간 도메인의 입력 음성 신호 \(x\)에 싱크 함수로 컨볼루션 연산을 적용하려고 하는데, 여기에 문제가 하나 있다. 컴퓨터 성능이 아무리 좋더라도 무한한 길이의 싱크 함수(=컨볼루션 필터)를 사용할 수는 없다. 따라서 그림9의 상단과 같이 싱크 함수를 적당히 잘라서 사용해야 할 것이다.
그림9 FILTER TRUNCATION
싱크 함수를 유한한 길이로 자르고 이를 푸리에 변환을 하면 그림10의 하단과 같은 모양이 된다. 이상적인 bandpass filter의 모양(사각형)에서 점점 멀어지게 되는 것이다. 이렇게 되면 우리가 원하는 주파수 영역대 정보는 덜 캐치하게 되고, 버려야 하는 주파수 영역대 정보도 일부 캐치하게 된다.
그림10 싱크 함수의 길이별 비교
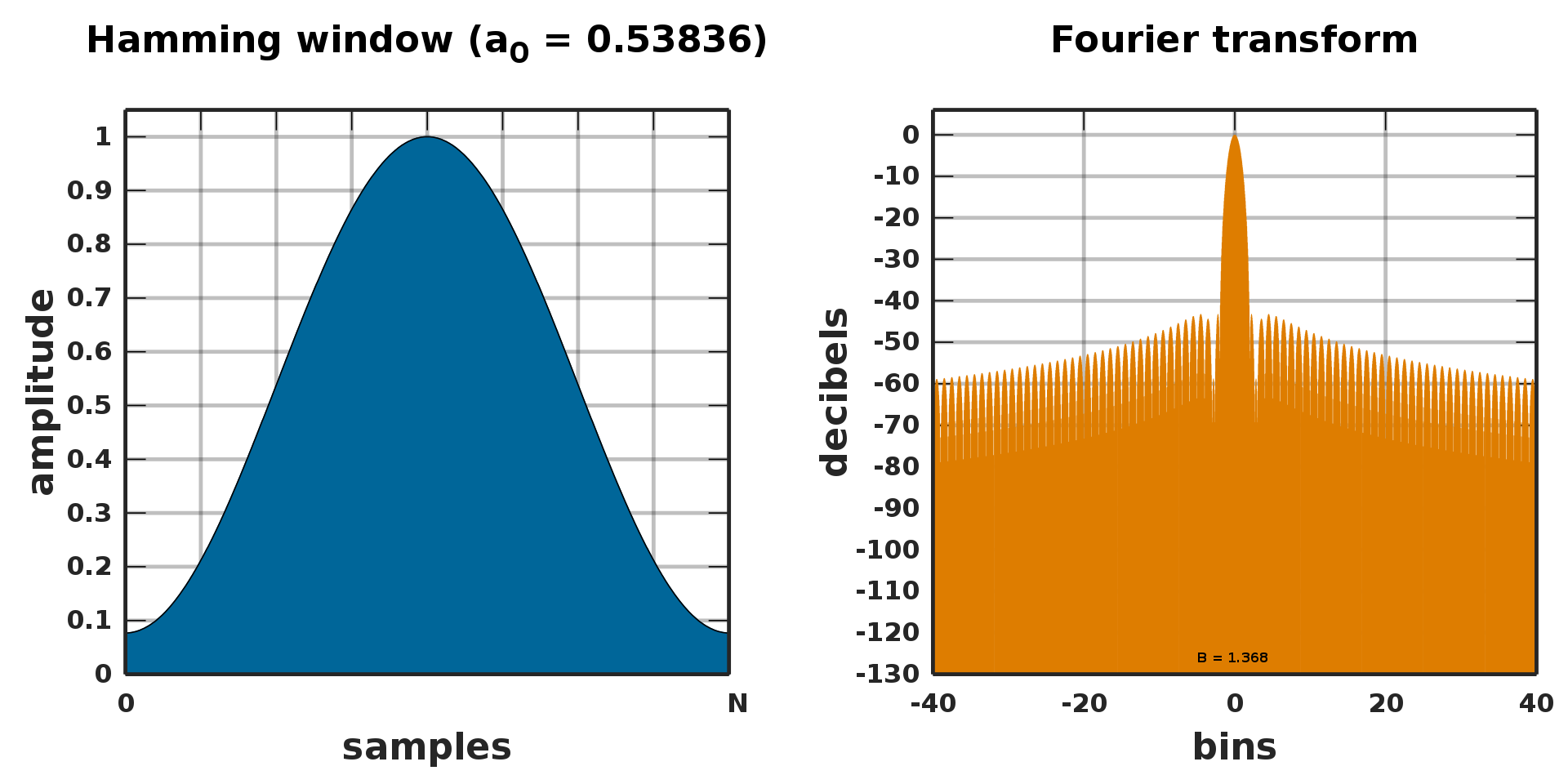
이러한 문제를 해결하기 위해 SincNet 저자들은 윈도우(window) 기법을 적용했다. 싱크 함수를 특정 길이로 자르는 대신 해당 필터에 윈도우 함수를 써서 양끝으로 스무딩한다는 개념이다. SincNet 저자들은 윈도우 기법으로 해밍 윈도우(Hamming window)를 사용했다. 수식7과 같다.
수식7 해밍 윈도우

그림11은 해밍 윈도우를 푸리에 변환한 결과이다. 중심 주파수 영역대는 잘 캐치하고 그 외 주파수 영역대는 무시하게 된다. 다시 말해 유한한 길이의 싱크 함수를 사용하더라도 해밍 윈도우 기법을 사용하면 원하는 주파수 영역대 정보를 잘 살리고, 버려야 할 주파수 영역대 정보는 잘 버리는 보완책이 될 수 있다는 이야기이다.
그림11 해밍 윈도우의 푸리에 변환
입력 신호에 대한 windowing
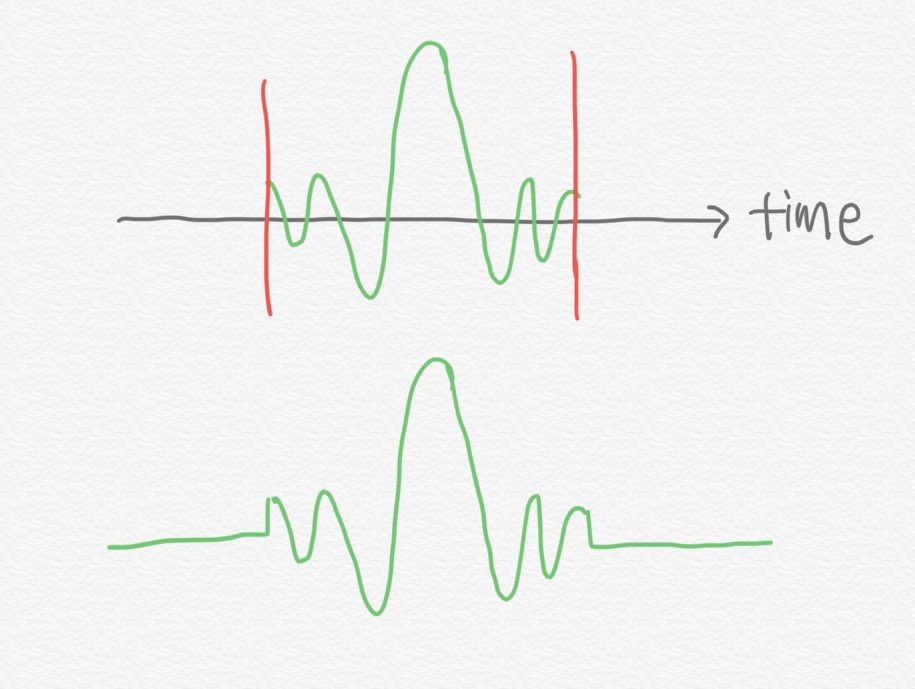
본래 윈도우라는 개념은 시간 도메인에서의 입력 신호 \(x\)에 시행하는 것이 정석이다. 음성 신호는 그 길이가 매우 길기 때문에 프레임별로 잘라서 처리를 한다. 그런데 입력 신호를 인위적으로 자를 경우 문제가 발생한다. 아래 그림에서 관찰할 수 있는 것처럼 자른 부분에서 직각 신호(square wave)가 생기는 것이다.

이렇게 뾰족한(sharp) 구간에서는 깁스 현상(Gibbs phenomenon)이 발생한다고 한다. 깁스 현상을 이해해보기 위해 아래 그림을 보자.
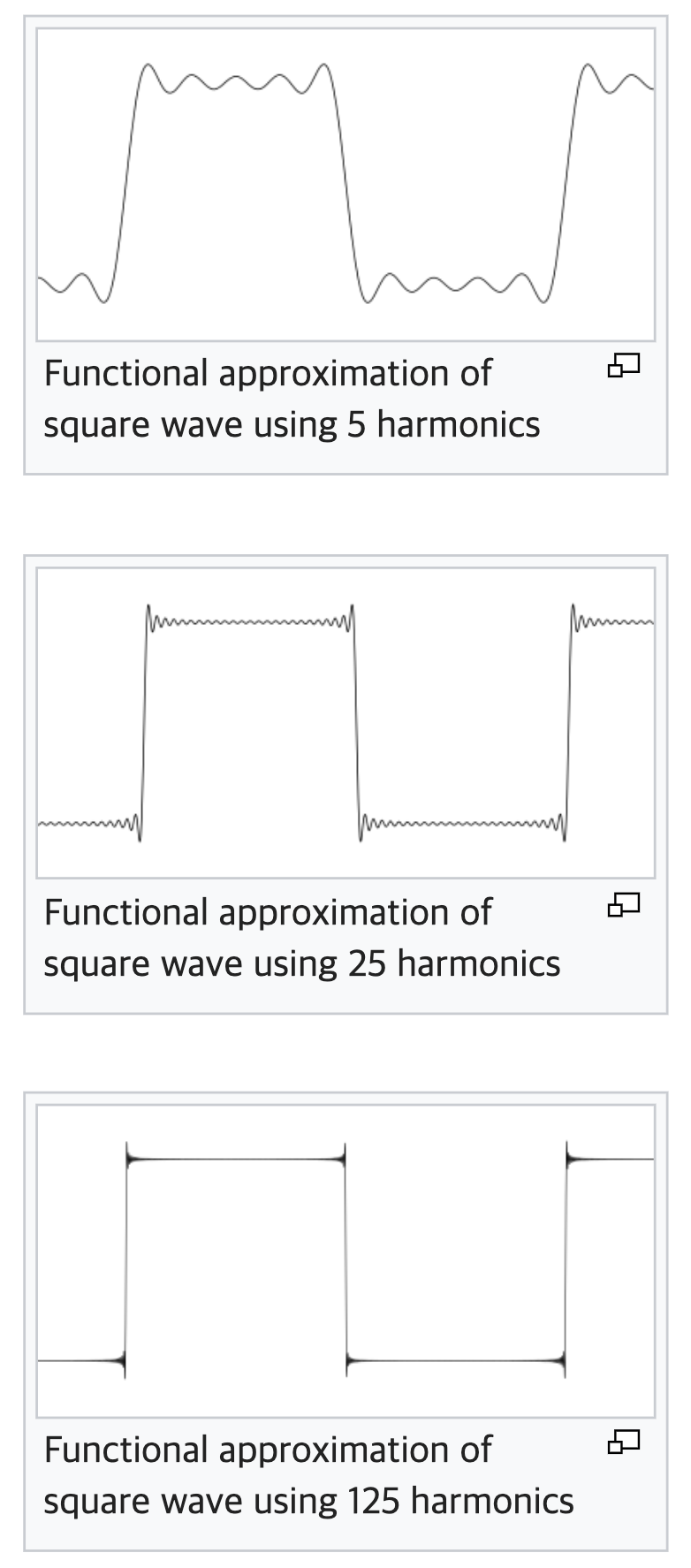
위의 첫 번째 그림은 서로 다른 주기(cycle)를 가진 사인(sin) 함수 다섯 개를 합해서 만든 그래프이다. 세 번째 그림은 125개를 썼다. 자세히 보면 사인 함수를 많이 쓸수록 직각에 가까운 신호를 만들어낼 수는 있지만, 굴절되는 구간에서 여전히 뾰족하게 튀어나온 부분을 확인할 수 있다. 주파수 성분(=사인 함수)를 무한히 더해야 직각 신호를 완벽하게 표현할 수 있다가 깁스 현상의 핵심 개념이다.
입력 신호를 프레임 단위로 자르는 과정에서 직각 신호가 생겼다. 결과적으로 입력 신호에 고주파 성분(신호가 갑자기 튀거나 작아지는 등)이 생긴다. 이런 문제를 해결하기 위해 윈도우(window)가 제안됐다. 입력 신호에 윈도우를 곱해 신호 양 끝부분을 스무딩하는 것이다.
SincNet 저자들은 "싱크 함수를 유한한 길이로 잘라서 주파수 도메인에서 완벽한 구형 함수를 만들어내지 못하는 문제점을 해결하기 위해" 컨볼루션 필터(=싱크 함수)에 해밍 윈도우를 적용했다고 설명하고 있는데, 컨볼루션 연산 식(수식1, 수식8, 수식12)을 보면 (1) 컨볼루션 필터에 해밍 윈도우 적용 (2) 입력 신호에 해밍 윈도우 적용 두 가지 방식이 수치 연산 면에서는 정확하게 동치임을 확인할 수 있다.
5. SincNet
SincNet은 푸리에 변환(Fourier Transform) 없이 시간 도메인의 입력 신호를 바로 처리하는데, 수식8은 입력 음성 신호에 대해 모델의 첫 번째 레이어에서 컨볼루션을 수행하는 걸 나타낸다. \(x[n]\)은 입력 음성 시그널(시간 도메인)의 \(n\)번째 샘플, \(g\)는 그에 대응하는 컨볼루션 필터 값(스칼라)이다. \(y[n]\)은 컨볼루션 수행 결과 값이다.
수식8 시간 도메인에서의 컨볼루션 연산
우리가 원하는 컨볼루션 필터 \(g\)(시간 도메인)의 이상적인 형태는 주파수 도메인에서 구형 함수(rectangular) 형태로 나타나야 한다. 수식9처럼 특정 주파수 영역대(\(f / 2 f_{1}\)에서 \(f / 2 f_{2}\) 사이)만 남기고 나머지 주파수 영역대는 무시한다.
수식9 이상적인 BANDPASS FILTER - 주파수 도메인
Note
논문에는 \(f\)에 대한 명시적인 코멘트가 없는데, 목표로 하는 sample rate가 아닌가 한다. 예컨대 sample rate가 주로 16KHz인 데이터로 SincNet을 학습한다면 \(f\)는 16000이 된다. 코드를 보면 SincNet 클래스가 sr이라는 하이퍼 파라미터를 인자(argument)로 받는 것으로 확인할 수 있다.
저자들에 따르면 수식9를 시간 도메인으로 옮기면(역푸리에 변환) 수식10이 된다고 한다. 우리는 수식10처럼 정의된 싱크 함수들을 SincNet의 첫 번째 컨볼루션 레이어에 적용하게 된다. 수식10을 만들 때 learnable parameter는 bandpass 범위에 해당하는 스칼라 값 두 개, 즉 \(f_{1}\), \(f_{2}\)뿐인 것을 확인할 수 있다. 저자들은 전자를 low cut-off frequency, 후자를 high cut-off frequency라고 부르고 있다.
수식10 이상적인 BANDPASS FILTER - 시간 도메인
저자들은 \(f_{1}>0, f_{2} \geq f_{1}\)임을 보장하기 위해서 다음과 같은 제약을 두었다.
수식11 컷오프 주파수에 대한 제약
마지막으로 저자들은 유한한 길이의 싱크 함수를 써서 이상적인 bandpass filter 역할을 수행하지 못하는 문제점과 관련해 이를 극복하고자 해밍 윈도우(수식7)를 싱크 함수에 적용했다. 컨볼루션 필터의 양끝을 스무딩한다.
수식12 해밍 윈도우 적용
6. Code Reading
이제 코드를 살펴보자. 여느 아키텍처와 비교할 때 SincNet은 첫 번째 레이어(싱크 함수로 1D conv를 실시)만 특이하므로 첫 번째 레이어 부분만 설명할 예정이다. 먼저 필요한 패키지를 임포트하고 하이퍼파라미터를 정한다.
코드1 패키지 임포트, 하이퍼파라미터 세팅
import torch, math
import torch.nn.functional as F
import numpy as np
out_channels = 80
kernel_size = 251
sample_rate = 16000
in_channels = 1
stride = 1
padding = 0
dilation = 1
bias = False
groups = 1
min_low_hz = 50
min_band_hz = 50
low_hz = 30
high_hz = sample_rate / 2 - (min_low_hz + min_band_hz)
sample_rate: SincNet이 주로 보는 주파수 영역대, 수식9의 \(f\)에 대응.in_channels: 첫 번째 레이어의 입력 채널 수, raw wave form이 입력되기 때문에 채널 수는 1이 된다.out_channels: 첫 번째 레이어의 컨볼루션 필터(즉, 싱크 함수) 개수kernel_size: 싱크 함수의 길이 \(L\), 계산 효율성을 위해 싱크 함수를 좌우 대칭(symmetric) 형태로 만드는데, 다시 말해 center 값 앞뒤로 같은 값 n개씩 둔다는 이야기이다. 이 때문에 \(L\)을 홀수로 강제한다.low_hz: 싱크 함수가 보는 주파수 구간의 lower bound. low cut-off frequency \(f_{1}\)의 초기값을 만들 때만 쓴다.high_hz: 싱크 함수가 보는 주파수 구간의 upper bound. 예컨대sample_rate가 16000일 경우 7900이 된다. high cut-off frequency \(f_{2}\)의 초기값을 만들 때만 쓴다.padding,stride,bias,groups등: 일반적인 1d conv 하이퍼파라메터.
이제 kernel_size 개수만큼의 컨볼루션 필터(=싱크 함수)를 만들어 보자. 우선 헤르츠(Hz) 단위의 주파수를 mel scale로 변환하는 함수(to_mel)와 mel scale 주파수를 다시 헤르츠로 변환하는 함수(to_hz)를 각각 정의한다.
코드2 MEL 변환, HERZ 변환 함수 정의
그러면 low cut-off frequency \(f_{1}\)의 초기값을 만들어 보자. 여기에서 만드는 컨볼루션 필터(싱크 함수) 개수는 output_channels=80이 될텐데, 코드3을 실행하면 low_hz=30부터 high_hz=7900에 이르는 구간을 멜(mel) 스케일 기준으로 out_channels + 1개 구간으로 나눈다.
코드3 \(f_{1}\)의 초기값 만들기
코드3을 실행하면 hz 값은 그림12처럼 나온다. 30~7900에 이르는 주파수 구간을 81개 토막으로 자른 셈이 된다. 그런데 자세히 보면 토막 구간들의 길이가 일정하지 않고, 점점 길어지는 걸 확인할 수 있다. 예컨대 첫 번째 주파수(30Hz)와 두 번째 주파수(52.86Hz) 차이는 22.86이다. 그런데 맨 마지막 직전 주파수(7638.9Hz)와 맨 마지막 주파수(7900Hz) 차이는 261.1이나 된다.
이렇게 불균등하게 나누는 이유는 사람의 소리 인식 특성과 관계가 있다. 사람은 저주파수 영역대는 세밀히 잘 인식하고, 고주파수는 상대적으로 덜 세밀히 인식하는 경향이 있다고 한다. 우리는 모델로 하여금 말소리를 사람이 인식하는 것처럼 모사하게 만드는 데 목적이 있기 때문에 사람의 소리 인식과 비슷한 환경을 만들 필요가 있다. 이 때문에 low cut-off frequency \(f_{1}\)의 초기값을 멜 스케일 기준으로 out_channels + 1개 구간으로 나누는 것이다.
그림12 \(f_{1}\)의 초기값
array([ 30. , 52.85710786, 76.42989706, 100.74077638,
125.81285623, 151.66997065, 178.33669994, 205.83839403,
234.2011966 , 263.45206991, 293.61882043, 324.73012529,
356.81555954, 389.90562424, 424.03177549, 459.22645429,
495.52311744, 532.95626929, 571.56149454, 611.37549211,
652.43611001, 694.7823813 , 738.4545612 , 783.49416539,
829.94400943, 877.84824949, 927.25242431, 978.20349853,
1030.74990726, 1084.94160221, 1140.83009909, 1198.46852666,
1257.91167718, 1319.21605853, 1382.4399479 , 1447.64344722,
1514.88854026, 1584.23915157, 1655.76120728, 1729.5226977 ,
1805.59374201, 1884.0466549 , 1964.95601532, 2048.39873735,
2134.45414336, 2223.20403935, 2314.73279281, 2409.12741283,
2506.47763286, 2606.87599601, 2710.41794303, 2817.20190298,
2927.3293869 , 3040.90508422, 3158.0369623 , 3278.83636911,
3403.41813904, 3531.90070205, 3664.40619629, 3801.06058419,
3941.99377222, 4087.33973432, 4237.23663934, 4391.82698235,
4551.25772007, 4715.68041062, 4885.25135758, 5060.13175854,
5240.48785839, 5426.49110732, 5618.31832381, 5816.15186274,
6020.17978871, 6230.59605483, 6447.6006871 , 6671.39997455,
6902.20666536, 7140.24016909, 7385.72676524, 7638.89981839,
7900. ])
위에서 만든 \(f_{1}\)의 초기값들에 torch.nn.Parameter 함수를 적용해 learnable parameter로 만든다. 코드3에서 \(f_{1}\) 초기값으로 out_channels + 1개를 만들어두었는데, 코드4에선 여기에서 마지막 값을 버리고 out_channels개만큼만 취하는 걸 확인할 수 있다. low_hz_의 그 차원수는 (out_channels, 1)이 된다.
그림12의 각 요소값 간 차이(그림13 참조)만큼을 band_hz라는 변수로 만들고 이 또한 learnable parameter로 취급하는 걸 알 수 있다. band_hz_의 그 차원수 역시 (outchannels, 1)이다. 이는 나중에 high cut-off frequency \(f*{2}\)를 만들 때 쓴다. 결과적으로 컨볼루션 필터(싱크 함수)의 learnable parameter는 \(f*{1}\)과 \(f*{2}\) 두 스칼라 값뿐이다. 한편 low_hz_와 band_hz의 초기값은 코드1*에서 정의한 하이퍼파라미터를 바꾸지 않는 한 항상 같은 값으로 정해진다.
코드5 LEARNABLE PARAMETER 선언
그림13 BANDHZ의 초기값
그림13을 좀 더 자세하게 이해해보자. 수식11을 보면 \(f_{2}\)는 \(f_{1}+\left|f_{2}-f_{1}\right|\)이다. band_hz_는 나중에 \(f_{2}-f_{1}\) 역할을 수행하는데, band_hz_ 초기값을 그림13처럼 설정해 둘 경우 첫 번째 컨볼루션 필터의 \(f_{2}\)는 다음 두 번째 컨볼루션 필터의 \(f_{1}\)이 된다. 결과적으로 목표로 하는 주파수 \(f(16000)\)의 절반에 해당하는 범위(7900)에서 out_channels=80개의 컨볼루션 필터들이 비는 주파수 영역대가 없이 촘촘하게 입력 신호를 커버한다는 이야기가 된다.
Note
목표 주파수 \(f\)의 절반의 범위에서 입력 신호를 커버하는 것과 관련해서는 나이퀴스트 정리(Nyquist Theorem)와 관련이 있는 것 아닌가 한다. 원 신호를 목표 주파수로 복원하기 위해서는 해당 주파수 2배 이상의 sample rate로 샘플해야 한다는 정리이다.
자 이제는 수식12의 해밍 윈도우를 만들 차례이다. 컨볼루션 필터(싱크 함수) 길이 \(L\)에 절반에 해당하는 구간에 대해서만 해밍 윈도우를 만들어 놓는다. 해밍 윈도우는 함수 모양이 좌우 대칭(symmetric)이므로 절반만 만들어 놓고 이미 만든 절반(window_)과 이를 뒤집은 값들을 계산해 이어붙이면(concatenate) 같은 연산을 빠르게 수행할 수 있다.
코드5 HAMMING WINDOW
코드5까지는 SincConv_fast 모듈의 __init__ 부분에 해당하는 내용이었다. 다시 말해 \(f_{1}\) 등 파라미터의 초기값이나 해밍 윈도우 같이 변하지 않는 상수 값들을 미리 만들어 두었다고 생각하면 된다. 코드6부터는 forward 부분에 해당한다. 여기서부터는 입력 음성 신호를 받아서 태스크(화자 인식) 수행에 적절한 방향으로 \(f_{1}\)과 \(f_{2}\)를 갱신하는 파트라고 이해하면 된다.
코드6 설명의 편의를 위해 수식11을 다시 가져왔다. 비교해가면서 코드를 읽어보자. low, 즉 \(f_{1}\)은 앞서 만든 low_hz_(그 초기값은 hz=그림12)의 절대값을 취해서 만든다(수식11과 코드6이 다른 점은 min_low_hz=50을 더해준다는 점이다). high, 즉 \(f_{2}\)는 \(f_{1}+\left|f_{2}-f_{1}\right|\)를 계산해서 만드는데, 첫 번째 항은 low에 대응하고, 두 번째 항은 코드4, 그림13에서 만든 band_hz_에 절대값을 취한 것에 대응한다(수식11과 코드6이 다른 점은 min_band_hz=50을 더해준다는 점이다). torch.clamp 함수는 입력이 min보다 작으면 min, max보다 크면 max, 그 사이이면 입력 그대로 리턴한다.
한편 band라는 변수는 코드10을 위해 미리 준비해두는 것인데, 싱크 함수를 대칭(symmetric)으로 만들기 위해 정의하는 것이다. 싱크 함수는 주로 통과시키는 주파수 영역대에서 최고치를 가진다. 이를 main lobe라고 한다.
수식11 컷오프 주파수에 대한 제약
코드6 컷오프 주파수 \(f_{1}\)과 \(f_{2}\) 만들기
코드7~8 설명의 편의를 위해 수식10을 다시 가져왔다. 비교해가면서 코드를 읽어보자. 주파수(\(f\))와 시간(\(t\)), 샘플 인덱스(\(n\)) 사이에는 다음이 성립한다: \(n=ft\). 수식10을 계산하기 위해서는 수식10의 \(n\)에 대응하는 값들을 만들어 두어야 하는데, 이를 위해 코드7을 수행한다. 다시 말해 주파수(\(f\))와 시간 인덱스(\(t\))를 곱하는 것이다. 이를 torch.matmul로 수행하는 걸 코드7에서 확인할 수 있다.
수식10 이상적인 BANDPASS FILTER - 시간 도메인
코드7에서 low와 high는 지금까지 주파수로 정의해 왔기 때문에 이해가 그리 어렵지 않을 것 같은데, n_은 대체 어디에서 튀어나왔는지 감을 잡기 어렵다. 이는 코드5에 힌트가 있다. 코드8은 코드5에서 n_과 관련한 부분을 발췌해 가져온 것이다.
torch.arange(-n, 0).view(1, -1)를 수행한 결과는 그림14와 같다. 이는 시간 인덱스(\(t\))에 대응한다. 이 벡터에 low, high를 내적한 결과가 수식10 싱크 함수 내부에 있는 각각의 \(n\)이 된다. 그런데 코드8을 보면 \(2 \pi\)를 곱하고 \(f\), 즉 sample_rate로 나눠준걸 볼 수 있다. 전자인 \(2 \pi\)는 수식10의 싱크 함수 내에 있는 \(2 \pi\)에 대응한다.
그림14 시간 인덱스 만들기
tensor([[-125., -124., -123., -122., -121., -120., -119., -118., -117., -116.,
-115., -114., -113., -112., -111., -110., -109., -108., -107., -106.,
-105., -104., -103., -102., -101., -100., -99., -98., -97., -96.,
-95., -94., -93., -92., -91., -90., -89., -88., -87., -86.,
-85., -84., -83., -82., -81., -80., -79., -78., -77., -76.,
-75., -74., -73., -72., -71., -70., -69., -68., -67., -66.,
-65., -64., -63., -62., -61., -60., -59., -58., -57., -56.,
-55., -54., -53., -52., -51., -50., -49., -48., -47., -46.,
-45., -44., -43., -42., -41., -40., -39., -38., -37., -36.,
-35., -34., -33., -32., -31., -30., -29., -28., -27., -26.,
-25., -24., -23., -22., -21., -20., -19., -18., -17., -16.,
-15., -14., -13., -12., -11., -10., -9., -8., -7., -6.,
-5., -4., -3., -2., -1.]])
싱크 함수가 \(\sin c(x)=\sin (x) / x\) 꼴인 사실을 상기해보면 코드8을 이해할 수 있다. 다시 말해 \(2 f_{2} \operatorname{sinc}\left(2 \pi f_{2} n\right)=2 f_{2} \times \sin \left(2 \pi f_{2} n\right) / 2 \pi f_{2} n=\sin \left(2 \pi f_{2} n\right) / \pi n\)이므로, 시간 인덱스에 \(2 \pi\)가 이미 곱해진 n_에 2로 나눈 값을 다시 나눠주면 수식10이 된다는 것이다. 여기에 코드5의 해밍 윈도우를 곱한다.
여지껏 계산한 내용이 컨볼루션 필터(싱크 함수)의 좌측 부분, 즉 band_pass_left이다. 우리는 좌우 대칭(symmetric)인 싱크 함수를 만들고 있으므로 이를 뒤집어(torch.flip) 오른쪽 부분 band_pass_right을 만들고 중간값(band_pass_center) 역시 만든다. 최종적으로는 이를 이어붙여(concatenate) 필터 계산을 마친다.
코드8 싱크 함수 만들기 (2)
band_pass_left = (
(torch.sin(f_times_t_high) - torch.sin(f_times_t_low)) / (n_ / 2)
) * window_
band_pass_center = 2 * band.view(-1, 1)
band_pass_right = torch.flip(band_pass_left, dims=[1])
band_pass = torch.cat([band_pass_left, band_pass_center, band_pass_right], dim=1)
band_pass = band_pass / (2 * band[:, None])
filters = (band_pass).view(out_channels, 1, kernel_size)
이렇게 만든 필터들은 그림15처럼 생겼다(초기값 기준).
그림15 컨볼루션 필터들의 초기 모습
tensor([[[ 0.0368, 0.0362, 0.0356, ..., 0.0356, 0.0362, 0.0368]],
[[ 0.0362, 0.0380, 0.0397, ..., 0.0397, 0.0380, 0.0362]],
[[-0.0074, -0.0048, -0.0021, ..., -0.0021, -0.0048, -0.0074]],
...,
[[-0.0043, 0.0060, -0.0072, ..., -0.0072, 0.0060, -0.0043]],
[[-0.0016, 0.0031, -0.0044, ..., -0.0044, 0.0031, -0.0016]],
[[-0.0022, 0.0028, -0.0034, ..., -0.0034, 0.0028, -0.0022]]],
grad_fn=<ViewBackward>)
이 필터들을 입력 음성 신호에 대한 1D 컨볼루션 연산에 사용한다. 태스크 학습 과정에서 역전파(backpropagation)되어 전달된 그래디언트(gradient)를 받아 \(f_{1}\)과 \(f_{2}\)를 학습한다. 컨볼루션 필터 수(out_channels)가 80일 경우 총 160개의 스칼라값이 SincNet 첫 번째 레이어의 학습 대상 파라미터가 된다.
코드9 1D 컨볼루션 연산
7. Experiment
SincNet 저자들은 화자 인식 태스크에 이 모델을 적용했다. 그림16의 우측(TIMIT 데이터셋)을 보면 기존 CNN 대비 수렴이 빠른 점을 확인할 수 있다. 그림16의 좌측을 보면 SincNet 필터들이 기존 CNN 필터들 대비 중요 음성 특질 중 하나인 포만트(Formant) 주파수를 잘 잡아내고, 나머지 불필요한 주파수 영역대는 확실히 무시하는 점을 볼 수 있다.
그림16 SINCNET 실험 결과 (1)

그림17은 Librispeech 데이터셋을 학습한 결과이다. 첫 번째 행은 시간 도메인, 두 번째 행은 주파수 도메인에 대응한다. SincNet 필터들이 이상적인 형태의 bandpass filter 모양에 가까운 걸 확인할 수 있다. 즉 low/high cut-off frequency를 학습해 해당 주파수 영역대 정보를 잘 캐치하고 나머지 영역대를 무시한다는 이야기이다. 저자들은 SincNet 성능과 해석력(interpretability)이 기존 CNN 대비 좋다고 강조하고 있다.
그림17 SINCNET 실험 결과 (2)
