4. Gaussian Mixture Model
Info
기존 음성 인식 모델의 근간이었던 Gaussian Mixture Model에 대해 살펴본다.
1. Univariate Normal Distribution
정규분포는 가우스(Gauss, 1777-1855)에 의해 제시된 분포로서 일명 가우스분포(Gauss Distribution)라고 불린다. 물리학 실험 등에서 오차에 대한 확률분포를 연구하는 과정에서 발견되었다고 한다. 가우스 이후 이 분포는 여러 학문 분야에서 이용되었다. 초기의 통계학자들은 모든 자료의 히스토그램이 정규분포의 형태와 유사하지 않으면 비정상적인 자료라고까지 생각하였다고 한다. 이러한 이유로 이 분포에 정규(normal)라는 이름이 붙게 된 것이다.
정규분포는 특성값이 연속적인 무한모집단 분포의 일종으로서 평균이 \(\mu\)이고 표준편차가 \(\sigma\)인 경우 정규분포의 확률밀도함수(Probability Density Function)는 수식1과 같다. 수식1은 입력 변수 \(x\)가 1차원의 스칼라값인 단변량 정규분포(Univariate Normal Distribution)를 가리킨다. 단변량 정규분포의 파라미터는 \(\mu\)와 \(\sigma\) 둘뿐인데, 파라미터에 따라 분포가 달라지는 걸 그림1에서 확인할 수 있다.
수식1 UNIVARIATE NORMAL DISTRIBUTION
그림1 서로 다른 UNIVARIATE NORMAL DISTRIBUTION

2. Multivariate Normal Distribution
입력 변수가 \(D\)차원인 벡터인 경우를 다변량 정규분포(Multivariate Normal Distribution)라고 한다. 수식2와 같다. 여기에서 \(\mu\)는 \(D\)차원의 평균 벡터, \({\Sigma}\)는 \(D \times D\) 크기를 가지는 공분산(covariance) 행렬을 의미한다. \(|{\Sigma}|\)는 \({\Sigma}\)의 행렬식(determinant)이다.
수식2 MULTIVARIATE NORMAL DISTRIBUTION
그림2는 2차원 다변량 정규분포를 나타낸 것이다. 평균과 공분산에 따라 그 분포가 달라지는 걸 확인할 수 있다.
그림2 서로 다른 MULTIVARIATE NORMAL DISTRIBUTION
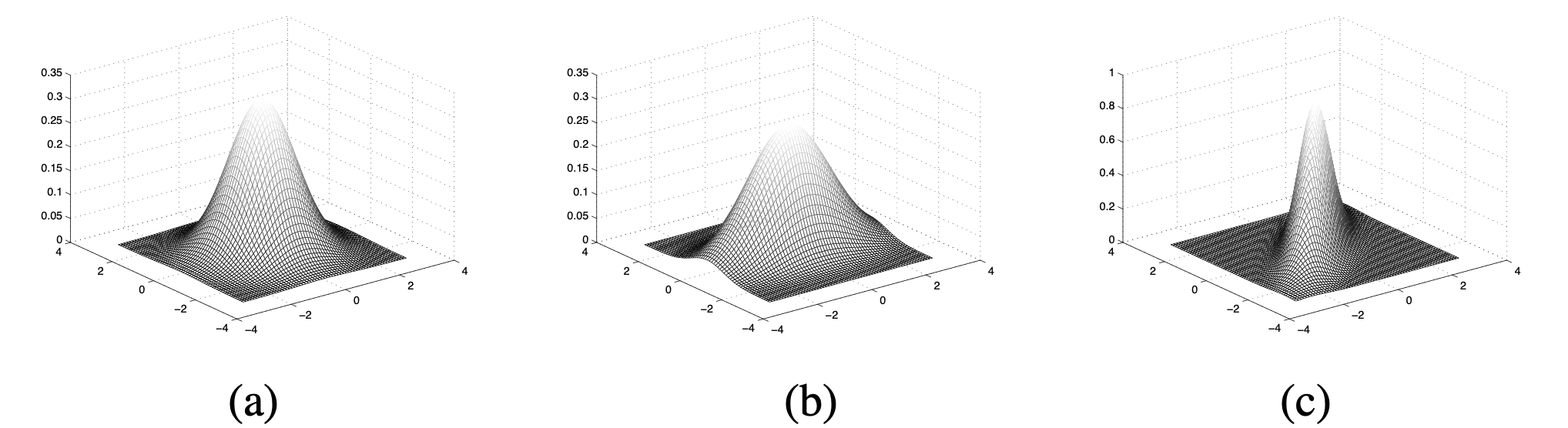
그림3은 서로 다른 공분산을 가진 세 개의 2차원(\(X\), \(Y\)) 다변량 정규분포를 나타낸 것이다. 세로축은 확률변수 \(X\), 가로축은 \(Y\)에 대응한다.
(a)는 공분산 행렬이 [[1, 0], [0, 1]]인 경우이다. 다시 말해 대각성분 이외의 요소값이 0인 대각행렬(diagonal matrix)이며 대각성분의 모든 값이 1로 동일하다. 이는 \(X\)와 \(Y\)의 분산이 1, 둘의 공분산은 0이라는 뜻이다. (a)에선 \(X\)와 \(Y\)의 분산이 서로 같고 둘의 공분산이 0이기 때문에 contour plot이 원형으로 나타난다.
(b)는 공분산 행렬이 [[0.6, 0], [0, 2]]인 경우이다. \(X\)의 분산은 0.6, \(Y\)의 분산은 2로 서로 다르고, 둘의 공분산은 역시 0이다. (b)에서는 \(X\)와 \(Y\)의 분산이 서로 다르고 둘의 공분산이 0이기 때문에 plot이 타원으로 나타난 걸 확인할 수 있다. \(Y\)의 분산이 더 크기 때문에 가로축으로 길쭉한 모양이다.
그림3 서로 다른 MULTIVARIATE NORMAL DISTRIBUTION의 공분산
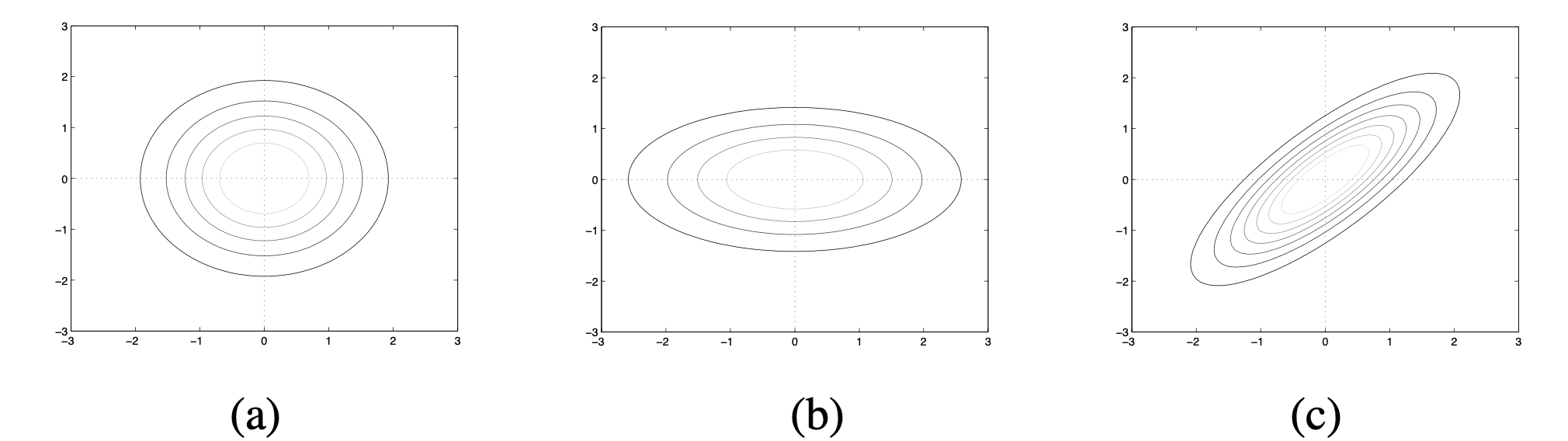
(c)는 공분산 행렬이 [[1, 0.8], [0.8, 1]]인 경우이다. \(X\)와 \(Y\)의 분산은 1로 서로 같지만 둘의 공분산은 0.8이다. 이 때문에 plot이 가로축(\(Y\)), 세로축(\(X\))에 정렬되지 않는 모습을 확인할 수 있다. 둘의 공분산이 0보다 크기 때문에 한 차원의 값을 알면 다른 차원의 값을 예측하는 데 도움이 된다.
3. Maximum Likelihood Estimation
이번 챕터에서는 최대가능도추정(Maximum Likelihood Estimation)을 정규분포의 파라미터 추정에 적용해 본다. 이해의 편의를 위해 단변량 정규분포에 적용하는 예시를 든다.
단변량 정규분포의 파라미터, 즉 \(\theta=(\mu, \sigma)\)를 알고 있다면 표본(\(x\))을 해당 정규분포 확률함수에 넣어서 해당 표본이 발생할 확률값 \(P(x \mid \theta)\)을 추정할 수 있다. 그런데 데이터만 있고 정규분포 파라미터를 모르는 상황이라면, 파라미터 \(\theta\)값을 조금씩 바꿔가면서 해당 \(\theta\)를 고정한 상태에서 \(P(x \mid \theta)\)가 높게 나오는 \(\theta\)를 찾아보아야 할 것이다. 다시 말해 데이터 혹은 표본을 가장 잘 설명하는 \(\theta\)를 찾는 것이 목적이다.
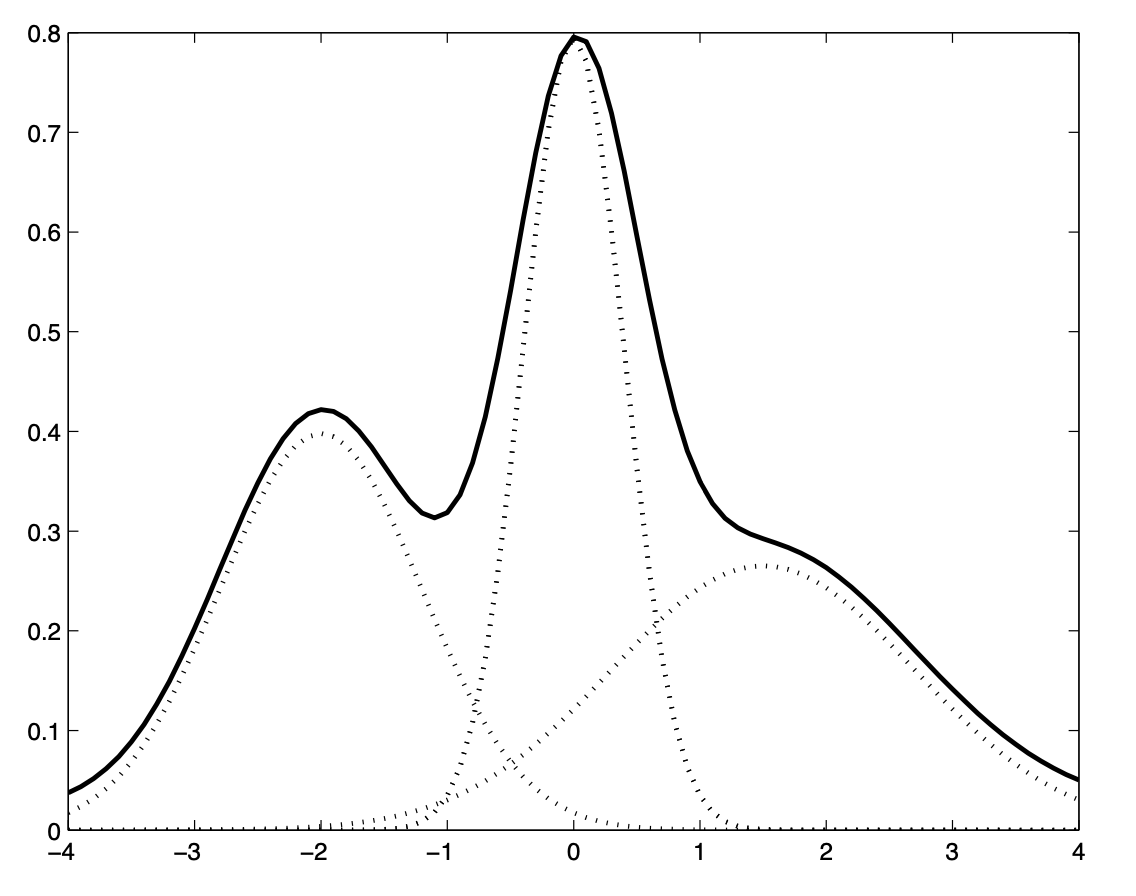
우리가 찾으려고 하는 파라미터 \(\theta\)가 \(\mu\) 하나뿐이라고 가정해 보자. 그림4에서 파란 점선은 \(\mu=-1\)일 때 정규분포(\(\sigma\)는 특정 값으로 고정)인데, 이 분포에서 \(x=1\)이 나타날 확률, 즉 \(P(x \mid \theta)\)는 0.05이다. 이 값을 가능도(likelihood)라고 한다. 오렌지 실선은 \(\mu=0\)일 때 정규분포이고 이 때 \(x=1\)이 나타날 확률은 0.24이다. 녹색 점선은 \(\mu=1\)일 때 정규분포, \(x=1\)이 나타날 확률은 0.40이다.
그림4 MLE의 직관적 이해

표본(sample)이 \(x=1\) 하나뿐일 때 이 세 가지 분포 가운데 표본을 가장 잘 설명하는 분포는 당연히 가능도가 가장 큰 분포일 것이다. 그림4에서는 \(\mu=1\)일 경우에 가능도가 가장 크다. 따라서 최대가능도추정에 의한 파라미터 추정값(\(\hat{\mu}_{\mathrm{MLE}}\))은 1이 된다.
이제 본격적으로 단변량 정규분포의 파라미터를 추정해 보자. 우리는 \(N\)개의 표본을 가지고 있다. 이들 표본 데이터는 동일한 정규분포로부터 뽑혔고, 표본이 뽑히는 과정에 서로 독립(independent)이라고 가정한다. 그러면 정규분포의 가능도 함수(likelihood function)를 수식3과 같이 곱으로 쓸 수 있다.
수식3 단변량 정규분포의 LIKELIHOOD FUNCTION
우리는 수식3을 최대화하는 \(\theta\)를 찾아야 한다. 보통은 수식3에 로그(log)를 취해 수식4처럼 계산한다. 확률은 1보다 작아 계속 곱하면 그 값이 지나치게 작아져 언더플로(underflow) 문제가 있고, 로그 변환을 취해도 최댓값이 바뀌지 않으며 곱셈이 덧셈으로 바뀌어 계산이 단순해지기 때문이다.
수식4 단변량 정규분포의 LOG-LIKELIHOOD FUNCTION
수식4의 로그 가능도 함수가 최대가 되는 \(\theta\)를 찾기 위해서는 각각의 \(\theta\)로 미분한 값이 0이 되어야 한다. 이 식을 풀면 수식4를 최대화하는 \(\mu\)와 \(\sigma\)를 구할 수 있다. 수식5와 같다(계산 편의를 위해 \(1 / \sigma^{2}\)를 \(\gamma\)로 치환).
수식5 단변량 정규분포의 MAXIMUM LIKELIHOOD ESTIMATION
최대가능도추정법으로 찾은 단변량 정규분포의 모수(parameter)의 특징은 다음과 같다.
- \(\hat{\mu}_{\mathrm{MLE}}\)는 표본평균(sample mean)과 같다.
- \(\hat{\sigma}_{\mathrm{MLE}}\)는 편향 표본 표준편차(biased sample standard deviation)와 동일하다.
이같은 과정을 다변량 정규분포에 적용해 찾은 \(\mu\), \({\Sigma}\)는 수식6과 같다. 수식6에서 \(\mathbf{x}_{i}\)는 우리가 가진 \(D\)차원 크기의 \(i\)번째 데이터(표본)를 가리킨다.
수식6 다변량 정규분포의 MLE 추정 결과
4. Gaussian Mixture Model
가우시안 믹스처 모델(Gaussian Mixture Model)은 수식7처럼 \(M\)개의 정규분포의 가중합(weighted sum)으로 데이터를 표현하는 확률 모델이다. 그 컨셉은 그림5와 같다. 데이터가 정규분포를 따르지 않거나 그 분포가 복잡한 모양(multimodal, not convex)일 경우 가우시안 믹스처 모델을 사용한다. 가우시안 믹스처 모델의 파라미터는 각 정규분포의 평균과 공분산, 가중치이다.
수식7 GAUSSIAN MIXTURE MODEL
그림5 GAUSSIAN MIXTURE MODEL
5. Expectation-Maximization
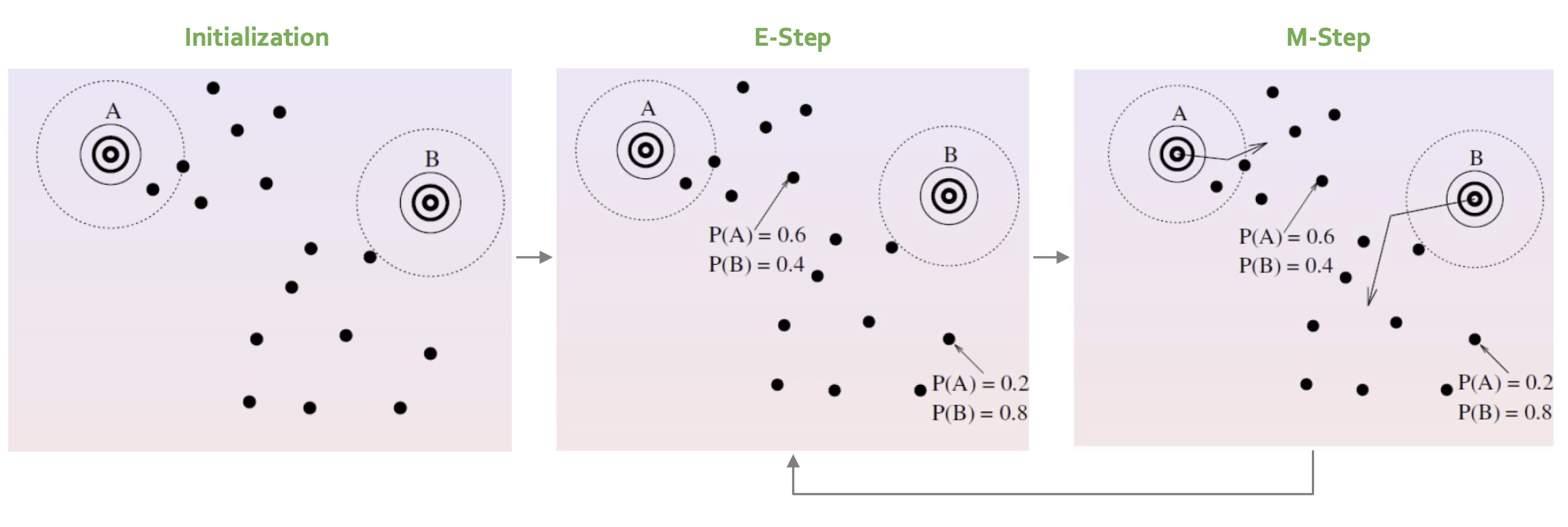
가우시안 믹스처 모델을 학습하려면 \(M\)개의 정규분포 확률함수(추정 대상 모수: \(\mu\), \({\Sigma}\))와 각각의 가중치(\(c\))를 구해야 한다. 그런데 \(\mu\), \({\Sigma}\), \(c\)를 구하려면 해당 데이터들이 \(M\)개 정규분포 가운데 어디에 속하는지 정보가 있어야 한다. 둘 모두 추정해야 하는 상황에서 널리 쓰이는 기법이 바로 Expectation-Maximization 알고리즘이다. 그 컨셉은 그림6과 같다.
우선 Initialization 스텝에서 \(\lambda\)를 랜덤 초기화한다. Expectation 스텝에서는 \(\lambda\)를 고정한 상태에서 모든 데이터에 대해 \(P(j \mid \mathbf{x})\)를 추정한다. 여기에서 \(j\)는 \(M\)개 정규분포 가운데 \(j\)번째 분포라는 뜻이다. 다시 말해 각 데이터를 \(M\)개 가우시안 확률 함수에 모두 넣어 각각의 확률값을 계산해 놓는다는 것이다. Maximization에서는 E-step에서 계산한 확률값을 고정해 놓은 상태에서 \(\lambda\)를 업데이트한다. E-step과 M-step을 충분히 반복한 후 학습을 마친다.
그림6 EXPECTATION-MAXIMIZATION ALGORITHM
Expectation 스텝에서는 \(\lambda\)를 고정한 상태에서 모든 데이터에 대해 가우시안 확률을 추정한다. 수식7과 같다.
수식7 EXPECTATION
Maximization 스텝에서는 수식7에서 계산해 놓은 가우시안 확률을 고정한 상태에서 파라미터 \(\lambda\)를 업데이트한다. 수식8은 최대가능도추정 방식으로 \(c\)를 유도한 것이다. \(j\)번째 정규분포의 가중치는 \(j\)번째 가우시안에 해당하는 수식7의 확률값을 모두 더해 반영된다. 데이터가 촘촘히 몰려 있는 가우시안 분포에 해당하는 \(c\)가 커질 것이다.
수식8 MAXIMIZATION: MIXTURE WEIGHT
각 가우시안의 평균과 분산은 최대가능도추정 방식으로 유도하면 수식9, 수식10과 같다. 평균은 일반적으로 \(\sum P(x) x\), 분산은 \(\sum P(x) x^{2}-\left(\sum P(x) x\right)^{2}\)로 정의된다는 사실을 염두에 두고 보시면 직관적 이해에 도움이 될 것이다.
수식9 MAXIMIZATION: MEANS
수식10 MAXIMIZATION: VARIANCES
6. Modeling Speech Recognition
음성 인식에서는 MFCC 피처가 정규분포를 따르지 않기 때문에 \(M\)개 다변량 정규분포 확률 함수를 합친 가우시안 믹스처 모델로 모델링한다. 이 때 다변량 정규분포의 공분산 행렬 \({\Sigma}\)을 Full Covariance Matrix(그림3의 (c)에 해당)로 모델링할 경우 성능이 좋다고 한다. 그도 그럴 것이 피처의 각 차원을 개별 확률변수로 봤을 때 각 확률변수 간 상관관계(correlation)가 존재할 수 있고 Full Covariance Matrix는 이를 포착해낼 수 있을 것이기 때문이다.
그러나 Full Covariance Matrix로 모델링할 경우 가우시안 믹스처 모델의 수렴이 늦어지거나 잘 안될 수 있다. 데이터도 그만큼 많이 필요하다. 다변량 정규분포의 입력이 \(D\)차원 벡터라고 할 때 우리가 추정해야 할 파라미터의 개수가 \(D^{2}\)개나 되기 때문이다. 이에 계산량을 줄이고 수렴을 가속화하기 위해 공분산이 diagonal, 즉 입력 벡터의 변수들끼리 서로 독립(independent)하다고 가정한다. 이 경우 공분산 행렬의 \(D\)개 대각 성분만 추정하면 되기 때문에 계산효율성을 도모할 수 있다.
이 경우 가정에 맞지 않는 데이터(변수 간 상관관계 존재)가 들어오면 모델의 성능은 낮아진다. 따라서 음성 인식을 위한 가우시안 믹스처 모델의 입력 데이터에는 decorrelation 작업을 확실히 실시해두어야 한다.