15. 컬렉션 프레임워크(Collection Framework)
1. 키워드
- 컬렉션 프레임워크(Collection Framework)
- 컬렉션 인터페이스(Collection Interface)와 컬렉션 클래스(Collection Class)
List컬렉션 클래스,ArrayList<E>클래스,LinkedList<E>클래스,Vector<E>클래스Stack<E>클래스와Queue<E>인터페이스,ArrayDeque클래스Set컬렉션 클래스,HashSet<E>클래스, 해시 알고리즘(Hash Algorithm),TreeSet<E>클래스Map컬렉션 클래스,HashMap<K, V>클래스,Hashtable<K, V>클래스,TreeMap<K, V>클래스Iterator,Iterator<E>인터페이스,Enumeration<E>인터페이스,ListIterator<E>인터페이스Comparable,Comparable<T>인터페이스,Comparator<T>인터페이스
2. 컬렉션 프레임워크(Collection Framework)의 개념
- 자바에서 컬렉션 프레임워크란 다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 방법을 제공하는 클래스의 집합을 의미한다.
- 즉, 데이터를 저장하는 자료 구조와 데이터를 처리하는 알고리즘을 구조화하여 클래스로 구현해 놓은 것들이다.
- 이러한 컬렉션 프레임워크는 자바의 인터페이스(Interface)를 사용하여 구현된다.
1) 컬렉션 프레임워크 주요 인터페이스
- 컬렉션 프레임워크에서는 데이터를 저장하는 자료 구조에 따라 다음과 같은 핵심이 되는 주요 인터페이스를 정의하고 있다.
1] List 인터페이스
2] Set 인터페이스
3] Map 인터페이스
- 이 중에서
List와Set인터페이스 모두Collection인터페이스를 상속받지만, 구조상의 차이로 인해Map인터페이스는 별도로 정의된다. - 따라서
List와Set인터페이스의 공통된 부분을Collection인터페이스에서 정의하고 있다.
2) 주요 인터페이스 간의 상속 관계
- 자바에서 컬렉션 프레임워크를 구성하고 있는 인터페이스 간의 상속 관계는 다음 그림과 같다.
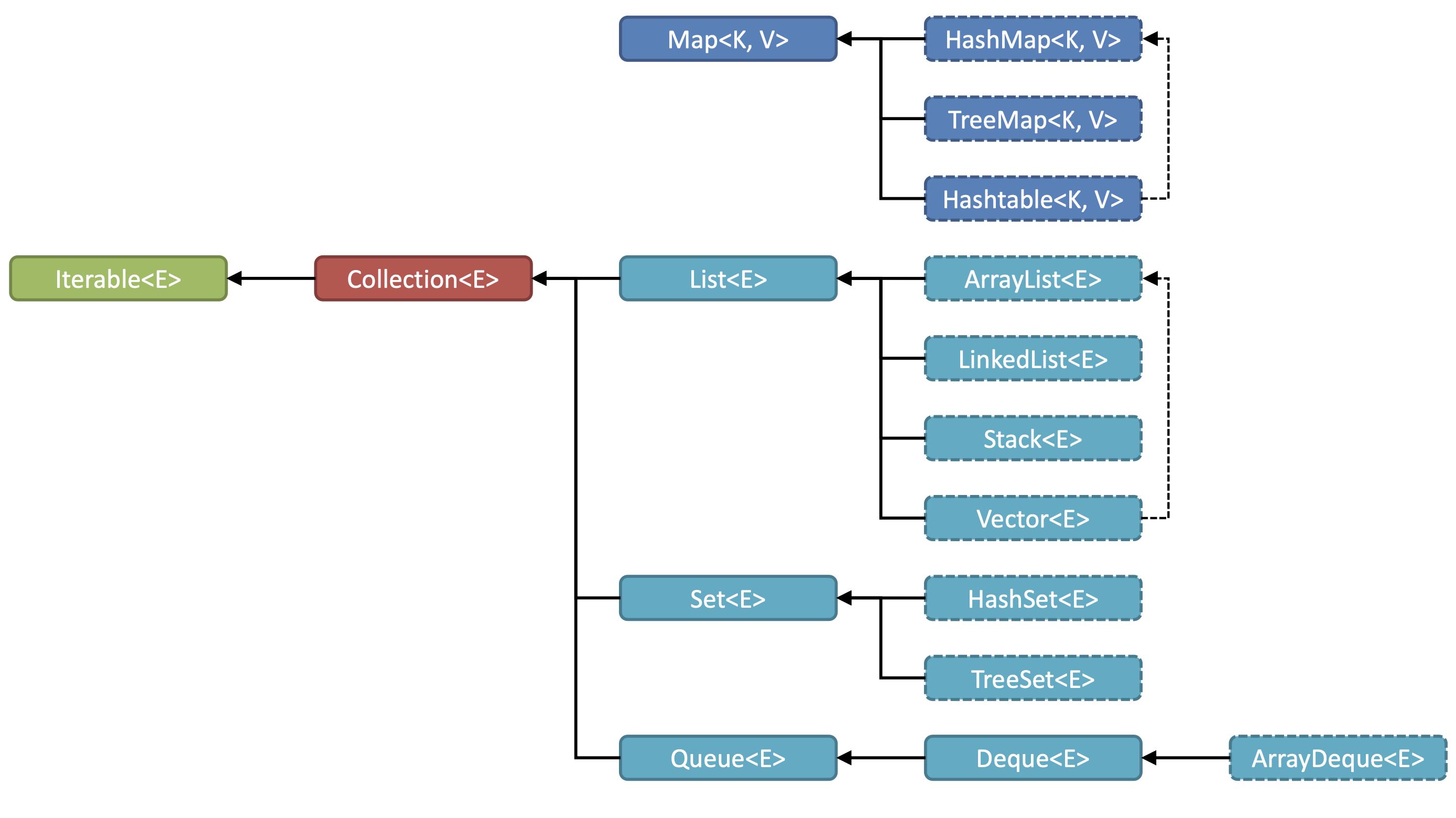
- 위의 그림에서
<E>나<K, V>라는 것은 컬렉션 프레임워크를 구성하는 모든 클래스가 제네릭으로 표현되어 있음을 알려준다.
3) 주요 인터페이스의 간략한 특징
- 자바에서 컬렉션 프레임워크를 구성하고 있는 주요 인터페이스의 간략한 특징은 다음과 같다.
| 인터페이스 | 설명 | 구현 클래스 |
|---|---|---|
List<E> |
순서가 있는 데이터의 집합으로, 데이터의 중복을 허용함 | Vector, ArrayList, LinkedList, Stack, Queue |
Set<E> |
순서가 없는 데이터의 집합으로, 데이터의 중복을 허용하지 않음 | HashSet, TreeSet |
Map<K, V> |
키와 값의 한 쌍으로 이루어지는 데이터의 집합으로, 순서가 없음 이때 키는 중복을 허용하지 않지만, 값은 중복될 수 있음 |
HashMap, TreeMap, Hashtable, Properties |
4) 컬렉션 클래스(Collection Class)
- 컬렉션 프레임워크에 속하는 인터페이스를 구현한 클래스를 컬렉션 클래스라고 한다.
- 컬렉션 프레임워크의 모든 컬렉션 클래스는
List와Set,Map인터페이스 중 하나의 인터페이스를 구현하고 있다. - 또한, 클래스 이름에도 구현한 인터페이스의 이름이 포함되므로 바로 구분할 수 있다.
Vector나Hashtable과 같은 컬렉션 클래스는 예전부터 사용해 왔으므로, 기존 코드와의 호환을 위해 아직도 남아있다.- 하지만 기존에 사용하던 컬렉션 클래스를 사용하는 것보다는 새로 추가된
ArrayList나HashMap클래스를 사용하는 것이 성능 면에서도 더 나은 결과를 얻을 수 있다.
- 다음 예제는
ArrayList클래스를 이용하여 리스트를 생성하고 조작하는 예제이다.
ArrayList<String> arrList = new ArrayList<String>(); // 리스트 생성
// 리스트에 요소 저장
arrList.add("넷");
arrList.add("둘");
arrList.add("셋");
arrList.add("하나");
for (int i = 0; i < arrList.size(); i++) { // 리스트 요소 출력
System.out.print(arrList.get(i) + " ");
}
// 넷 둘 셋 하나
5) Collection 인터페이스
List와Set인터페이스의 많은 공통된 부분을Collection인터페이스에서 정의하고, 두 인터페이스는 그것을 상속받는다.- 따라서
Collection인터페이스는 컬렉션을 다루는 데 가장 기본적인 동작들을 정의하고, 그것을 메서드로 제공하고 있다.
3. List 컬렉션 클래스
List인터페이스를 구현한 모든List컬렉션 클래스는 다음과 같은 특징을 가진다.
1] 요소의 저장 순서가 유지된다.
2] 같은 요소의 중복 저장을 허용한다.
- 대표적인
List컬렉션 클래스에 속하는 클래스는 다음과 같다.

1] ArrayList<E> 클래스
2] LinkedList<E> 클래스
3] Stack<E> 클래스
4] Vector<E> 클래스
1) ArrayList<E> 클래스
ArrayList클래스는 가장 많이 사용되는 컬렉션 클래스 중 하나이다.- JDK 1.2부터 제공된
ArrayList클래스는 내부적으로 배열을 이용하여 요소를 저장한다. ArrayList클래스는 배열을 이용하기 때문에 인덱스를 이용해 배열 요소에 빠르게 접근할 수 있다.- 하지만 배열은 크기를 변경할 수 없는 인스턴스이므로, 크기를 늘리기 위해서는 새로운 배열을 생성하고 기존의 요소들을 옮겨야 하는 복잡한 과정을 거쳐야 한다.
- 물론 이 과정은 자동으로 수행되지만, 요소의 추가 및 삭제 작업에 걸리는 시간이 매우 길어지는 단점을 가지게 된다.
- 다음 예제는 여러
ArrayList메서드를 이용하여 리스트를 생성하고 조작하는 예제이다.
ArrayList<Integer> arrList = new ArrayList<Integer>();
// add() 메서드를 이용한 요소 저장
arrList.add(40);
arrList.add(20);
arrList.add(30);
arrList.add(10);
for (int i = 0; i < arrList.size(); i++) { // for 문과 get() 메서드를 이용한 요소 출력
System.out.print(arrList.get(i) + " ");
}
arrList.remove(1); // remove() 메서드를 이용한 요소 제거
System.out.println();
for (int e : arrList) { // Enhanced for 문과 get() 메서드를 이용한 요소의 출력
System.out.print(e + " ");
}
Collections.sort(arrList); // Collections.sort() 메서드를 이용한 요소 정렬
System.out.println();
// iterator() 메서드와 get() 메서드를 이용한 요소 출력
Iterator<Integer> iter = arrList.iterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " ");
}
arrList.set(0, 20); // set() 메서드를 이용한 요소 변경
System.out.println();
for (int e : arrList) {
System.out.print(e + " ");
}
System.out.println();
System.out.println("리스트의 크기: " + arrList.size()); // size() 메서드를 이용한 요소의 총 개수
// 40 20 30 10
// 40 30 10
// 10 30 40
// 20 30 40
// 리스트의 크기: 3
- 위의 예제처럼 컬렉션 클래스의 요소를 출력하는 방법에는
for문과 Enhancedfor문,iterator()메서드를 이용한 방법 등 다양한 방법을 사용할 수 있다.
Note
- 자바의
Collections클래스는 JDK 1.2부터 제공되는 컬렉션에서 동작하거나 컬렉션을 반환하는 클래스 메서드(Static Method)만으로 구성된 클래스이다. - 자바의
Collection은 인터페이스이며,Collections는 클래스이다.
2) LinkedList<E> 클래스
LinkedList클래스는ArrayList클래스가 배열을 이용하여 요소를 저장함으로써 발생하는 단점을 극복하기 위해 고안되었다.- JDK 1.2부터 제공된
LinkedList클래스는 내부적으로 링크드 리스트(Linked List)를 이용하여 요소를 저장한다. - 배열은 저장된 요소가 순차적으로 저장된다.
- 하지만 링크드 리스트는 저장된 요소가 비순차적으로 분포되며, 이러한 요소들 사이를 링크(Link)로 연결하여 구성한다.
- 다음 요소를 가리키는 참조만을 가지는 링크드 리스트를 싱글리 링크드 리스트(Singly Linked List)라고 한다.
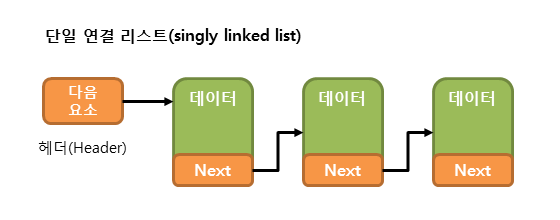
- 이러한 싱글리 링크드 리스트는 요소의 저장과 삭제 작업이 다음 요소를 가리키는 참조만 변경하면 되므로, 아주 빠르게 처리될 수 있다.
- 하지만 싱글리 링크드 리스트는 현재 요소에서 이전 요소로 접근하기가 매우 어렵다.
- 따라서 이전 요소를 가리키는 참조도 가지는 더블리 링크드 리스트(Doubly Linked List)가 좀 더 많이 사용된다.
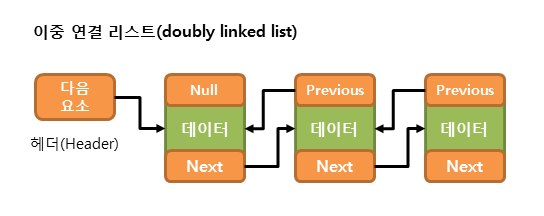
LinkedList클래스도 위와 같은 더블리 링크드 리스트를 내부적으로 구현한 것이다.- 또한,
LinkedList클래스 역시List인터페이스를 구현하므로,ArrayList클래스와 사용할 수 있는 메서드가 거의 같다.
- 다음 예제는 여러
LinkedList메서드를 이용하여 리스트를 생성하고 조작하는 예제이다.
LinkedList<String> lnkList = new LinkedList<String>();
// add() 메서드를 이용한 요소 저장
lnkList.add("넷");
lnkList.add("둘");
lnkList.add("셋");
lnkList.add("하나");
for (int i = 0; i < lnkList.size(); i++) { // for 문과 get() 메서드를 이용한 요소 출력
System.out.print(lnkList.get(i) + " ");
}
lnkList.remove(1); // remove() 메서드를 이용한 요소 제거
System.out.println();
// Enhanced for 문과 get() 메서드를 이용한 요소 출력
for (String e : lnkList) {
System.out.print(e + " ");
}
lnkList.set(2, "둘"); // set() 메서드를 이용한 요소 변경
System.out.println();
for (String e : lnkList) {
System.out.print(e + " ");
}
System.out.println();
System.out.println("리스트의 크기: " + lnkList.size()); // size() 메서드를 이용한 요소의 총 개수
// 넷 둘 셋 하나
// 넷 셋 하나
// 넷 셋 둘
// 리스트의 크기: 3
- 위의 예제를 살펴보면 앞선 예제와 링크드 리스트를 생성하는 한 줄의 코드만이 다른 것을 확인할 수 있다.
- 이처럼
ArrayList와LinkedList의 차이는 사용 방법이 아닌, 내부적으로 요소를 저장하는 방법에 있다.
3) Vector<E> 클래스
Vector클래스는 JDK 1.0부터 사용해 온ArrayList클래스와 같은 동작을 수행하는 클래스이다.- 현재의
Vector클래스는ArrayList클래스와 마찬가지로List인터페이스를 상속받는다. - 따라서
Vector클래스에서 사용할 수 있는 메서드는ArrayList클래스에서 사용할 수 있는 메서드와 거의 같다. - 하지만 현재에는 기존 코드와의 호환성을 위해서만 남아있으므로,
Vector클래스보다는ArrayList클래스를 사용하는 것이 좋다.
4) List 인터페이스 메서드
List인터페이스는Collection인터페이스를 상속받으므로,Collection인터페이스에서 정의한 메서드도 모두 사용할 수 있다.
4. Stack과 Queue
1) Stack<E> 클래스
Stack클래스는List컬렉션 클래스의Vector클래스를 상속받아, 전형적인 스택 메모리 구조의 클래스를 제공한다.- 스택 메모리 구조는 선형 메모리 공간에 데이터를 저장하면서 후입선출(LIFO, Last-In-First-Out)의 시멘틱을 따르는 자료 구조이다.
- 즉, 가장 나중에 저장된(Push) 데이터가 가장 먼저 인출(Pop)되는 구조이다.

- 더욱 복잡하고 빠른 스택을 구현하고 싶다면
Deque인터페이스를 구현한ArrayDeque클래스를 사용하면 된다.
- 다음 예제는 여러
Stack메서드를 이용하여 스택 메모리 구조를 구현한 예제이다.
Stack<Integer> st = new Stack<Integer>();
// Deque<Integer> st = new ArrayDeque<Integer>();
// push() 메서드를 이용한 요소 저장
st.push(4);
st.push(2);
st.push(3);
st.push(1);
System.out.println(st.peek()); // peek() 메서드를 이용한 요소 반환
System.out.println(st);
System.out.println(st.pop()); // pop() 메서드를 이용한 요소 반환 및 제거
System.out.println(st);
// search() 메서드를 이용한 요소 위치 검색
System.out.println(st.search(4));
System.out.println(st.search(3));
// 1
// [4, 2, 3, 1]
// 1
// [4, 2, 3]
// 3
// 1
Note
- 단,
ArrayDeque클래스는Stack클래스와는 달리search()메서드는 지원하지 않는다.
2) Queue<E> 인터페이스
- 클래스로 구현된 스택과는 달리 자바에서 큐 메모리 구조는 별도의 인터페이스 형태로 제공된다.
- 이러한
Queue인터페이스를 상속받는 하위 인터페이스는 다음과 같다.

1] Deque<E> 인터페이스
2] BlockingDeque<E> 인터페이스
3] BlockingQueue<E> 인터페이스
4] TransferQueue<E> 인터페이스
- 따라서
Queue인터페이스를 직간접적으로 구현한 클래스는 상당히 많다. - 그중에서도
Deque인터페이스를 구현한LinkedList클래스가 큐 메모리 구조를 구현하는 데 가장 많이 사용된다. - 큐 메모리 구조는 선형 메모리 공간에 데이터를 저장하면서 선입선출(FIFO, First-In-First-Out)의 시멘틱을 따르는 자료 구조이다.
- 즉, 가장 먼저 저장된(Push) 데이터가 가장 먼저 인출(Pop)되는 구조이다.
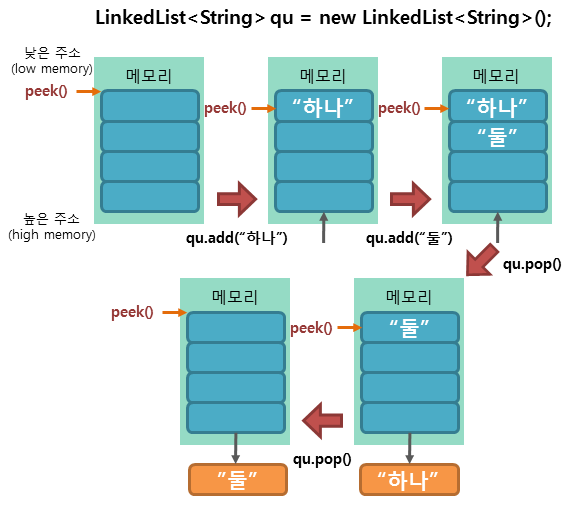
- 더욱 복잡하고 빠른 큐를 구현하고 싶다면
Deque인터페이스를 구현한ArrayDeque클래스를 사용하면 된다.
- 다음 예제는 여러
LinkedList메서드를 이용하여 큐 메모리 구조를 구현한 예제이다.
LinkedList<String> qu = new LinkedList<String>();
// Deque<String> qu = new ArrayDeque<String>();
// add() 메서드를 이용한 요소 저장
qu.add("넷");
qu.add("둘");
qu.add("셋");
qu.add("하나");
System.out.println(qu.peek()); // peek() 메서드를 이용한 요소 반환
System.out.println(qu);
System.out.println(qu.poll()); // poll() 메서드를 이용한 요소 반환 및 제거
System.out.println(qu);
qu.remove("하나"); // remove() 메서드를 이용한 요소 위치 검색
System.out.println(qu);
// 넷
// [넷, 둘, 셋, 하나]
// 넷
// [둘, 셋, 하나]
// [둘, 셋]
Note
- Java SE 6부터 지원되는
ArrayDeque클래스는 스택과 큐 메모리 구조를 모두 구현하는데 가장 적합한 클래스이다.
5. Set 컬렉션 클래스
Set인터페이스를 구현한 모든Set컬렉션 클래스는 다음과 같은 특징을 가진다.
1] 요소의 저장 순서를 유지하지 않는다.
2] 같은 요소의 중복 저장을 허용하지 않는다.
- 대표적인
Set컬렉션 클래스에 속하는 클래스는 다음과 같다.

1] HashSet<E> 클래스
2] TreeSet<E> 클래스
1) HashSet<E> 클래스
HashSet클래스는Set컬렉션 클래스에서 가장 많이 사용되는 클래스 중 하나이다.- JDK 1.2부터 제공된
HashSet클래스는 해시 알고리즘(Hash Algorithm)을 사용하요 검색 속도가 매우 빠르다. - 이러한
HashSet클래스는 내부적으로HashMap인스턴스를 이용하여 요소를 저장한다. HashSet클래스는Set인터페이스를 구현하므로, 요소를 순서에 상관없이 저장하고 중복된 값은 저장하지 않는다.- 만약 요소의 저장 순서를 유지해야 한다면, JDK 1.4부터 제공하는
LinkedHashSet클래스를 사용하면 된다.
- 다음 예제는 여러
HashSet메서드를 이용하여 집합을 생성하고 조작하는 예제이다.
HashSet<String> hs01 = new HashSet<String>();
HashSet<String> hs02 = new HashSet<String>();
// add() 메서드를 이용한 요소 저장
hs01.add("홍길동");
hs01.add("이순신");
System.out.println(hs01.add("임꺽정"));
System.out.println(hs01.add("임꺽정")); // 중복된 요소 저장
for (String e : hs01) { // Enhanced for 문과 get() 메서드를 이용한 요소 출력
System.out.print(e + " ");
}
System.out.println();
// add() 메서드를 이용한 요소 저장
hs02.add("임꺽정");
hs02.add("홍길동");
hs02.add("이순신");
// iterator() 메서드를 이용한 요소 출력
Iterator<String> iter02 = hs02.iterator();
while (iter02.hasNext()) {
System.out.print(iter02.next() + " ");
}
System.out.println();
System.out.println("집합의 크기: " + hs02.size()); // size() 메서드를 이용한 요소의 총 개수
// true
// false
// 홍길동 이순신 임꺽정
// 홍길동 이순신 임꺽정
// 집합의 크기: 3
Note
Collection인터페이스에서는Iterator인터페이스를 구현한 클래스의 인스턴스를 반환하는iterator()메서드를 정의하여 각 요소에 접근하도록 하고 있다.
- 위의 예제에서 요소의 저장 순서를 바꿔도 저장되는 순서에는 영향을 미치지 않는 것을 확인할 수 있다.
- 또한,
add()메서드를 사용하여 해당HashSet에 이미 존재하는 요소를 추가하려고 하면, 해당 요소를 저장하지 않고false를 반환하는 것을 볼 수 있다. - 이때 해당
HashSet에 이미 존재하는 요소인지를 파악하기 위해서는 내부적으로 다음과 같은 과정을 거치게 된다.
1] 해당 요소에서 hashCode() 메서드를 호출하여 반환된 해시값으로 검색할 범위를 결정한다.
2] 해당 범위 내의 요소들을 equals() 메서드로 비교한다.
- 따라서
HashSet에서add()메서드를 사용하여 중복없이 새로운 요소를 추가하기 위해서는hashCode()와equals()메서드를 상황에 맞게 오버라이딩해야 한다.
- 다음 예제는 사용자가 정의한
Animal클래스의 인스턴스를HashSet에 저장하기 위해hashCode()와equals()메서드를 오버라이딩한 예제이다.
import java.util.*;
class Animal {
String species;
String habitat;
Animal(String species, String habitat) {
this.species = species;
this.habitat = habitat;
}
public int hashCode() {
return (species + habitat).hashCode();
}
public boolean equals(Object obj) {
if (obj instanceof Animal) {
Animal temp = (Animal) obj;
return species.equals(temp.species) && habitat.equals(temp.habitat);
} else {
return false;
}
}
}
class Test {
public static void main(String[] args) {
HashSet<Animal> hs = new HashSet<Animal>();
hs.add(new Animal("고양이", "육지"));
hs.add(new Animal("고양이", "육지"));
hs.add(new Animal("고양이", "육지"));
System.out.println(hs.size()); // 1
}
}
add()메서드를 통해 같은 값을 가지는Animal인스턴스를 여러 번 저장하지만,size()메서드를 통해 살펴본HashSet요소의 총 개수는1개만 저장되었음을 확인할 수 있다.
2) 해시 알고리즘(Hash Algorithm)
- 해시 알고리즘이란 해시 함수(Hash Function)를 사용하여 데이터를 해시 테이블(Hash Table)에 저장하고, 다시 그것을 검색하는 알고리즘이다.

- 자바에서 해시 알고리즘을 이용한 자료 구조는 위의 그림과 같이 배열과 링크드 리스트로 구현된다.
- 저장할 데이터의 기값을 해시 함수에 넣어 반환되는 값으로 배열의 인덱스를 구한다.
- 그리고 해당 인덱스에 저장된 링크드 리스트에 데이터를 저장하게 된다.
3) TreeSet<E> 클래스
TreeSet클래스는 데이터가 정렬된 상태로 저장되는 이진 탐색 트리(Binary Search Tree)의 형태로 요소를 저장한다.- 이진 탐색 트리는 데이터를 추가하거나 제거하는 등의 기본 동작 시간이 매우 빠르다.
- JDK 1.2부터 제공되는
TreeSet클래스는NavigableSet인터페이스를 기존의 이진 탐색 트리의 성능을 향상시킨 레드-블랙 트리(Red-Black Tree)로 구현한다. TreeSet클래스는Set인터페이스를 구현하므로, 요소를 순서에 상관없이 저장하고 중복된 값은 저장하지 않는다.
- 다음 예제는 여러
TreeSet메서드를 이용하여 집합을 생성하고 조작하는 예제이다.
TreeSet<Integer> ts = new TreeSet<Integer>();
// add() 메서드를 이용한 요소 저장
ts.add(30);
ts.add(40);
ts.add(20);
ts.add(10);
for (int e : ts) { // Enhanced for 문과 get() 메서드를 이용한 요소 출력
System.out.print(e + " ");
}
System.out.println();
ts.remove(40); // remove() 메서드를 이용한 요소 제거
// iterator() 메서드를 이용한 요소 출력
Iterator<Integer> iter = ts.iterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " ");
}
System.out.println();
System.out.println("이진 탐색 트리의 크기: " + ts.size()); // size() 메서드를 이용한 요소의 총 개수
// subSet() 메서드를 이용한 부분 집합 출력
① System.out.println(ts.subSet(10, 20));
② System.out.println(ts.subSet(10, true, 20, true));
// 10 20 30 40
// 10 20 30
// 이진 탐색 트리의 크기 : 3
// [10]
// [10, 20]
- 위의 예제처럼
TreeSet인스턴스에 저장되는 요소들은 모두 정렬된 상태로 저장된다.
- 또한, 위의 예제에서 사용된
subSet()메서드는TreeSet인스턴스에 저장되는 요소가 모두 정렬된 상태이기에 동작이 가능한 해당 트리의 부분 집합만을 보여주는 메서드이다.
1. public NavigableSet<E> subSet(E fromElement, E toElement)
2. public NavigableSet<E> subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive)
- ①번 라인에서 사용된
subSet()메서드는 첫 번째 매개변수로 전달된 값에 해당하는 요소부터 시작하여 두 번째 매개변수로 전달된 값에 해당하는 요소의 바로 직전 요소까지를 반환한다. - ②번 라인에서 사용된
subSet()메서드는 두 번째와 네 번째 매개변수로 각각 첫 번째와 세 번째 매개변수로 전달된 값에 해당하는 요소를 포함할 것인지 아닌지를 명시할 수 있다. - 즉, ②번 라인에서 네 번째 매개변수를
false로 변경하면20을 포함하지 않게 되므로, ①번 라인과 같은 결과를 출력할 것이다.
4) Set 인터페이스 메서드
Set인터페이스는Collection인터페이스를 상속받으므로,Collection인터페이스에서 정의한 메서드도 모두 사용할 수 있다.
6. Map 컬렉션 클래스
Map인터페이스는Collection인터페이스와는 다른 저장 방식을 가진다.Map인터페이스를 구현한Map컬렉션 클래스들은 키와 값을 하나의 쌍으로 저장하는 방식(Key-Value 방식)을 사용한다.- 여기서 키(Key)란 실질적인 값(Value)을 찾기 위한 이름의 역할을 한다.
Map인터페이스를 구현한 모든Map컬렉션 클래스는 다음과 같은 특징을 가진다.
1] 요소의 저장 순서를 유지하지 않는다.
2] 키는 중복을 허용하지 않지만, 값의 중복은 허용한다.
- 대표적인
Map컬렉션 클래스에 속하는 클래스는 다음과 같다.
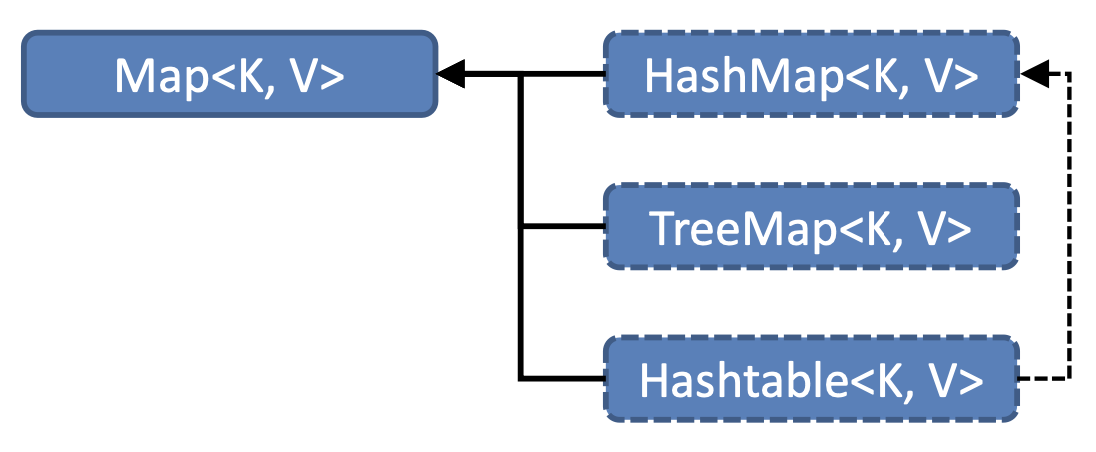
1] HashMap<K, V> 클래스
2] TreeMap<K, V> 클래스
3] Hashtable<K, V> 클래스
1) HashMap<K, V> 클래스
HashMap클래스는Map컬렉션 클래스에서 가장 많이 사용되는 클래스 중 하나이다.- JDK 1.2부터 제공된
HashMap클래스는 해시 알고리즘을 사용하여 검색 속도가 매우 빠르다. HashMap클래스는Map인터페이스를 구현하므로, 중복된 키로는 값을 저장할 수 없다.- 하지만 같은 값을 다른 키로 저장하는 것은 가능하다.
- 다음 예제는 여러
HashMap메서드를 이용하여 맵을 생성하고 조작하는 예제이다.
HashMap<String, Integer> hm = new HashMap<String, Integer>();
// put() 메서드를 이용한 요소 저장
hm.put("삼십", 30);
hm.put("십", 10);
hm.put("사십", 40);
hm.put("이십", 20);
System.out.println("맵에 저장된 키들의 집합: " + hm.keySet());
System.out.println();
for (String key : hm.keySet()) { // Enhanced for 문과 get() 메서드를 이용한 요소 출력
System.out.println(String.format("키: %s, 값: %s", key, hm.get(key)));
}
System.out.println();
hm.remove("사십"); // remove() 메서드를 이용한 요소 제거
// iterator() 메서드와 get() 메서드를 이용한 요소 출력
Iterator<String> keys = hm.keySet().iterator();
while (keys.hasNext()) {
String key = keys.next();
System.out.println(String.format("키: %s, 값: %s", key, hm.get(key)));
}
System.out.println();
hm.replace("이십", 20, 200); // replace() 메서드를 이용한 요소 수정
for (String key : hm.keySet()) {
System.out.println(String.format("키: %s, 값: %s", key, hm.get(key)));
}
System.out.println();
System.out.println("맵의 크기: " + hm.size()); // size() 메서드를 이용한 요소의 총 개수
// 맵에 저장된 키들의 집합: [이십, 삼십, 사십, 십]
//
// 키: 이십, 값: 20
// 키: 삼십, 값: 30
// 키: 사십, 값: 40
// 키: 십, 값: 10
//
// 키: 이십, 값: 20
// 키: 삼십, 값: 30
// 키: 십, 값: 10
//
// 키: 이십, 값: 200
// 키: 삼십, 값: 30
// 키: 십, 값: 10
//
// 맵의 크기: 3
- 위의 예제에서 사용된
keySet()메서드는 해당 맵에 포함된 모든 키 값들을 하나의 집합(Set)으로 반환해 준다.
2) TreeMap<K, V> 클래스
TreeMap클래스는 키와 값을 한 쌍으로 하는 데이터를 이진 탐색 트리(Binary Search Tree)의 형태로 저장한다.- 이진 탐색 트리는 데이터를 추가하거나 제거하는 등의 기본 동작 시간이 매우 빠르다.
- JDK 1.2부터 제공되는
TreeMap클래스는NavigableMap인터페이스를 기존의 이진 탐색 트리의 성능을 향상시킨 레드-블랙 트리(Red-Black Tree)로 구현한다. TreeMap클래스는Map인터페이스를 구현하므로, 중복된 키로는 값을 저장할 수 없다.- 하지만 같은 값을 다른 키로 저장하는 것은 가능하다.
- 다음 예제는 여러
TreeMap메서드를 이용하여 맵을 생성하고 조작하는 예제이다.
TreeMap<Integer, String> tm = new TreeMap<Integer, String>();
// put() 메서드를 이용한 요소 저장
tm.put(30, "삼십");
tm.put(10, "십");
tm.put(40, "사십");
tm.put(20, "이십");
System.out.println("맵에 저장된 키들의 집합: " + tm.keySet());
System.out.println();
for (Integer key : tm.keySet()) { // Enhanced for 문과 get() 메서드를 이용한 요소 출력
System.out.println(String.format("키: %s, 값: %s", key, tm.get(key)));
}
System.out.println();
tm.remove(20); // remove() 메서드를 이용한 요소 제거
// iterator() 메서드와 get() 메서드를 이용한 요소 출력
Iterator<Integer> keys = tm.keySet().iterator();
while (keys.hasNext()) {
Integer key = keys.next();
System.out.println(String.format("키: %s, 값: %s", key, tm.get(key)));
}
System.out.println();
tm.replace(20, "이십", "twenty"); // replace() 메서드를 이용한 요소 수정
for (Integer key : tm.keySet()) {
System.out.println(String.format("키: %s, 값: %s", key, tm.get(key)));
}
System.out.println();
System.out.println("맵의 크기: " + tm.size()); // size() 메서드를 이용한 요소의 총 개수
// 맵에 저장된 키들의 집합: [10, 20, 30, 40]
//
// 키: 10, 값: 십
// 키: 20, 값: 이십
// 키: 30, 값: 삼십
// 키: 40, 값: 사십
//
// 키: 10, 값: 십
// 키: 30, 값: 삼십
// 키: 40, 값: 사십
//
// 키: 10, 값: 십
// 키: 30, 값: 삼십
// 키: 40, 값: 사십
//
// 맵의 크기: 3
3) Hashtable<K, V> 클래스
Hashtable클래스는 JDK 1.0부터 사용해 온HashMap클래스와 같은 동작을 하는 클래스이다.- 현재의
Hashtable클래스는HashMap클래스와 마찬가지로Map인터페이스를 상속받는다. - 따라서
Hashtable클래스에서 사용할 수 있는 메서드는HashMap클래스에서 사용할 수 있는 메서드와 거의 같다. - 하지만 현재에는 기존 코드와의 호환성을 위해서만 남아있으므로,
Hashtable클래스보다는HashMap클래스를 사용하는 것이 좋다.
7. Iterator와 ListIterator
1) Iterator<E> 인터페이스
- 자바의 컬렉션 프레임워크는 컬렉션에 저장된 요소를 읽어오는 방법을
Iterator인터페이스로 표준화하고 있다. Collection인터페이스에서는Iterator인터페이스를 구현한 클래스의 인스턴스를 반환하는iterator()메서드를 정의하여 각 요소에 접근하도록 하고 있다.- 따라서
Collection인터페이스를 상속받는List와Set인터페이스에서도iterator()메서드를 사용할 수 있다.
- 다음 예제는 링크드 리스트를 반복자(
Iterator)를 사용하여 순회하는 예제이다.
LinkedList<Integer> lnkList = new LinkedList<Integer>();
lnkList.add(4);
lnkList.add(2);
lnkList.add(3);
lnkList.add(1);
Iterator<Integer> iter = lnkList.iterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " ");
}
// 4 2 3 1
Iterator인터페이스는 컬렉션의 각 요소에 접근할 수 있다.- 하지만 현재 자바에서는 될 수 있으면 JDK 1.5부터 추가된 Enhanced
for문을 사용하도록 권장하고 있다. - Enhanced
for문을 사용하면 같은 성능을 유지하면서도 코드의 명확성을 확보하고 발생할 수 있는 버그를 예방해 준다. - 하지만 요소의 선택적 제거나 대체 등을 수행하기 위한 경우에는 반복자를 사용해야만 한다.
2) Enumeration<E> 인터페이스
Enumeration인터페이스는 JDK 1.0부터 사용해 온Iterator인터페이스와 같은 동작을 하는 인터페이스이다.Enumeration인터페이스는hasMoreElements()와nextElement()메서드를 사용하여Iterator와 같은 작업을 수행한다.- 하지만 현재에는 기존 코드와의 호환성을 위해서만 남아있으므로,
Enumeration인터페이스보다는Iterator인터페이스를 사용하는 것이 좋다.
3) ListIterator<E> 인터페이스
ListIterator인터페이스는Iterator인터페이스를 상속받아 여러 기능을 추가한 인터페이스이다.Iterator인터페이스는 컬렉션의 요소에 접근할 때 한 방향으로만 이동할 수 있다.- 하지만 JDK 1.2부터 제공된
ListIterator인터페이스는 컬렉션 요소의 대체, 추가 그리고 인덱스 검색 등을 위한 작업에서 양방향으로 이동하는 것을 지원한다. - 단,
ListIterator인터페이스는List인터페이스를 구현한List컬렉션 클래스에서만listIterator()메서드를 통해 사용할 수 있다.
- 다음 예제는 리스트 반복자를 사용하여 리스트의 모든 요소를 각각 순방향과 역방향으로 출력하는 예제이다.
LinkedList<Integer> lnkList = new LinkedList<Integer>();
lnkList.add(4);
lnkList.add(2);
lnkList.add(3);
lnkList.add(1);
ListIterator<Integer> iter = lnkList.listIterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " ");
}
System.out.println();
while (iter.hasPrevious()) {
System.out.print(iter.previous() + " ");
}
// 4 2 3 1
// 1 3 2 4
8. Comparable과 Comparator
1) Comparable<T> 인터페이스
Comparable인터페이스는 객체를 정렬하는 데 사용되는 메서드인compareTo()메서드를 정의하고 있다.- 자바에서 같은 타입의 인스턴스를 서로 비교해야만 하는 클래스들은 모두
Comparable인터페이스를 구현하고 있다. - 따라서
Boolean을 제외한Wrapper클래스나String,Time,Date와 같은 클래스의 인스턴스는 모두 정렬 가능하다. - 이때 기본 정렬 순서는 작은 값에서 큰 값으로 정렬되는 오름차순이 된다.
- 다음 예제는 인스턴스의 비교를 위해 사용자 정의 클래스인
Car클래스가Comparable인터페이스를 구현하는 예제이다.
class Car implements Comparable<Car> {
private String modelName;
private int modelYear;
private String color;
Car(String mn, int my, String c) {
this.modelName = mn;
this.modelYear = my;
this.color = c;
}
public String getModel() {
return this.modelYear + "식 " + this.modelName + " " + this.color;
}
public int compareTo(Car obj) {
if (this.modelYear == obj.modelYear) {
return 0;
} else if (this.modelYear < obj.modelYear) {
return -1;
} else {
return 1;
}
}
}
class Test {
public static void main(String[] args) {
Car car01 = new Car("아반떼", 2016, "노란색");
Car car02 = new Car("소나타", 2010, "흰색");
System.out.println(car01.compareTo(car02)); // 1
}
}
2) Comparator<T> 인터페이스
Comparator인터페이스는Comparable인터페이스와 같이 객체를 정렬하는 데 사용되는 인터페이스이다.Comparable인터페이스를 구현한 클래스는 기본적으로 오름차순으로 정렬된다.- 반면에
Comparator인터페이스는 내림차순이나 아니면 다른 기준으로 정렬하고 싶을 때 사용할 수 있다. - 즉,
Comparator인터페이스를 구현하면 오름차순 이외의 기준으로도 정렬할 수 있게 되는 것이다. - 이때
Comparator인터페이스를 구현한 클래스에서는compare()메서드를 재정의하여 사용하게 된다.
- 다음 예제는 요소를 내림차순으로 정렬하여 저장하는
TreeSet인스턴스를 생성하기 위해Comparator인터페이스를 구현하는 예제이다.
import java.util.*;
class DescendingOrder implements Comparator<Integer> {
public int compare(Integer o1, Integer o2) {
if (o1 instanceof Comparable && o2 instanceof Comparable) {
Integer c1 = (Integer) o1;
Integer c2 = (Integer) o2;
return c2.compareTo(c1);
}
return -1;
}
}
class Test {
public static void main(String[] args) {
TreeSet<Integer> ts = new TreeSet<Integer>(new DescendingOrder());
ts.add(30);
ts.add(40);
ts.add(20);
ts.add(10);
Iterator<Integer> iter = ts.iterator();
while (iter.hasNext()) {
System.out.print(iter.next() + " ");
}
}
}
// 40 30 20 10