2. 타입(Type)
1. 키워드
- 타입(Type)
- 변수(Variable)
- 비트(bit)와 바이트(Byte)
- 리터럴 상수(Literal Constant)와 심볼릭 상수(Symbolic Constant)
- 오버플로우(Overflow)
- 고정 소수점(Fixed Point)과 부동 소수점(Floating Point)
- 묵시적 타입 변환(Implicit Type Conversion)과 명시적 타입 변환(Explicit Type Conversion)
2. 변수
- 변수란 데이터를 저장하기 위해 프로그램에 의해 이름을 할당 받은 메모리 공간을 의미한다.
- 즉, 변수란 데이터를 저장할 수 있는 메모리 공간을 의미하며, 이렇게 저장된 값은 변경될 수 있다.
- C++에서 숫자 표현에 관련된 변수는 정수형 변수와 실수형 변수로 구분할 수 있다.
- 또한 정수형 변수는
char,int,long,long long타입 변수로, 실수형 변수는float,double타입 변수로 구분된다. - 관련된 데이터를 한 번에 묶어서 처리하는 사용자 정의 구조체 변수도 있다.
1) 변수의 이름 생성 규칙
- C++에서는 변수의 이름을 비교적 자유롭게 지을 수 있다.
- 변수의 이름은 해당 변수에 저장될 데이터의 의미를 잘 나타내도록 짓는 것이 좋다.
- C++에서 변수의 이름을 생성할 때 반드시 지켜야 하는 규칙은 다음과 같다.
1] 변수의 이름은 영문자(대소문자), 숫자, _(언더스코어)로만 구성된다.
2] 변수의 이름은 숫자로 시작될 수 없다.
3] 변수의 이름 사이에는 공백을 포함할 수 없다.
4] 변수의 이름으로 C++에서 미리 정의된 키워드는 사용할 수 없다.
5] 변수 이름의 길이에는 제한이 없다.
- C++에서는 변수의 이름에 대소문자를 구분하므로 주의해야 한다.
2) 비트와 바이트
- 컴퓨터는 모든 데이터를 2진수로 표현하고 처리한다.
- 비트란 컴퓨터가 데이터를 처리하기 위해 사용하는 데이터의 최소 단위이다.
- 이러한 비트에는 2진수의 값(
0과1)을 단 하나만 저장할 수 있다. - 바이트란 위와 같은 비트가
8개 모여서 구성되며, 한 문자를 표현할 수 있는 최소 단위이다.
3) 변수와 메모리 주소
- 변수는 기본적으로 메모리의 주소를 기억하는 역할을 한다.
- 메모리 주소란 물리적인 메모리 공간을 서로 구분하기 위해 사용되는 일종의 식별자이다.
- 즉, 메모리 주소란 메모리 공간에서의 정확한 위치를 식별하기 위한 고유 주소를 의미한다.
- 변수를 참조할 때는 메모리의 주소를 참조하는 것이 아닌, 해당 주소에 저장된 데이터를 참조하게 된다.
- 따라서 변수는 데이터가 저장된 메모리의 주소뿐만 아니라, 저장된 데이터의 길이와 형태에 관한 정보도 같이 기억해야 한다.
- 다음 그림은 메모리 상에 변수가 어떤 식으로 저장되는지를 보여준다.

- 위의 그림에서 하나의 메모리 공간에는
1바이트의 데이터가 저장되어 있다. - 해당 변수의 길이는 총
4개의 메모리 공간을 포함하므로, 해당 변수는 총4바이트의 데이터를 저장하고 있는 것이다.
4) 변수의 선언
- C++에서는 변수를 사용하기 전에 반드시 먼저 해당 변수를 저장하기 위한 메모리 공간을 할당 받아야 한다.
- 이렇게 해당 변수만을 위한 메모리 공간을 할당 받는 행위를 변수의 선언이라고 부른다.
- C++에서 변수를 선언하는 방법에는 다음과 같이 두 가지 방법이 있다.
1] 변수의 선언만 하는 방법
2] 변수의 선언과 동시에 초기화하는 방법
(1) 변수의 선언만 하는 방법
- 이 방법은 먼저 변수를 선언하여 메모리 공간을 할당 받고, 나중에 변수를 초기화하는 방법이다.
- 하지만 이렇게 선언만 된 변수는 초기화하지 않았기 때문에 해당 메모리 공간에는 알 수 없는 쓰레깃값만이 들어가 있다.
- 따라서 초기화하지 않은 변수는 절대로 사용해서는 안 된다.
- 위의 코드처럼 정수를 저장하기 위한 메모리 공간을 할당 받으면, 반드시 해당 타입의 데이터만을 저장해야 한다.
- 그렇지 않고 다른 타입의 데이터를 저장할 경우에는 저장된 데이터에 변형이 일어날 수도 있다.
(2) 변수의 선언과 동시에 초기화하는 방법
- C++에서는 변수의 선언과 동시에 그 값을 초기화할 수 있다.
- 또한, 선언하고자 하는 변수들의 타입이 같다면 이를 동시에 선언할 수 있다.
- 선언하고자 하는 변수의 타입이 서로 다르면 동시에 선언할 수 없다.
3. 상수
- 상수란 변수와 마찬가지로 데이터를 저장할 수 있는 메모리 공간을 의미한다.
- 하지만 상수가 변수와 다른 점은 프로그램이 실행되는 동안 메모리에 저장된 데이터를 변경할 수 없다는 것이다.
- C++에서 상수는 표현 방식에 따라 다음과 같이 나눌 수 있다.
1] 리터럴 상수
2] 심볼릭 상수
1) 리터럴 상수
- 리터럴 상수는 변수와는 달리 데이터가 저장된 메모리 공간을 가리키는 이름을 가지고 있지 않다.
- C++에서는 적절한 메모리 공간을 할당 받기 위하여, 기본적으로 변수든 상수든 타입을 가지고 있다.
- C++에서 상수는 타입에 따라 다음과 같이 정수형 리터럴 상수, 실수형 리터럴 상수, 문자형 리터럴 상수 등으로 구분할 수 있다.
1] 정수형 리터럴 상수는 123, -456과 같이 아라비아 숫자와 부호로 직접 표현된다.
2] 실수형 리터럴 상수는 3.14, -45.6과 같이 소수 부분을 가지는 아라비아 숫자로 표현된다.
3] 문자형 리터럴 상수는 'a', 'Z'와 같이 ''(따옴표)로 감싸진 문자로 표현된다.
(1) 정수형 리터럴 상수
- 정수형 리터럴 상수는
123,-456과 같이 아라비아 숫자와 부호로 직접 표현된다. - C++에서는 정수형 상수를 10진수뿐만 아니라 8진수나 16진수로도 표현할 수 있다.
- 이렇게 여러 가지 진법으로 표현된 정수형 상수의 출력을 위해
cout객체는dec,hex,oct조정자를 제공하고 있다. - 이 세 가지 조정자를
cout객체에 전달하면 사용자가 다시 변경하기 전까지 출력되는 진법의 형태를 계속 유지할 수 있다.
- 다음과 같이 숫자
10을 각각 10진수, 8진수, 16진수의 형태로 출력할 수 있다.
#include <iostream>
using namespace std;
int main() {
int a = 10;
cout << "숫자 10을 10진수로 표현하면 " << a << "이며, " << endl;
cout << oct;
cout << "숫자 10을 8진수로 표현하면 " << a << "이며, " << endl;
cout << hex;
cout << "숫자 10을 16진수로 표현하면 " << a << "입니다.";
return 0;
}
// 숫자 10을 10진수로 표현하면 10이며,
// 숫자 10을 8진수로 표현하면 12이며,
// 숫자 10을 16진수로 표현하면 a입니다.
(2) 정수형 리터럴 상수의 타입
- C++에서 정수형 리터럴 상수는 다음과 같은 경우를 제외하면 모두
int타입으로 저장된다.
1] 데이터의 값이 너무 커서 int 타입으로 저장할 수 없는 경우
2] 정수형 상수에 접미사를 사용하여, 해당 상수의 타입을 직접 명시하는 경우
- C++에서는 접미사를 상수의 끝에 추가하여, 해당 상수의 타입을 직접 명시할 수 있다.
(3) 실수형 리터럴 상수의 타입
- C++에서 실수형 리터럴 상수는 모두 부동 소수점 방식으로 저장된다.
- 이러한 실수형 리터럴 상수는 모두
double타입으로 저장되며, 접미사를 추가하여 저장되는 타입을 직접 명시할 수도 있다.
(4) 포인터 리터럴 상수
- 널 포인터(Null Pointer)란 아무것도 가리키고 있지 않은 포인터를 의미한다.
- 지금까지 C++에서는 널 포인터를 표현하기 위해서 포인터를
0으로 초기화해 왔다. - 하지만 C++11부터는
nullptr키워드를 제공함으로써0으로 초기화된 널 포인터보다 더욱 제대로 널 포인터를 표현할 수 있게 되었다.
nullptr키워드를 사용한 리터럴 상수의 타입은 포인터 타입이며, 정수형으로 변환할 수 없다.- 아직도 C++에서는
0을 사용해 널 포인터를 명시할 수 있으며, 따라서nullptr == 0은 참(true)을 반환한다. - 하지만
nullptr리터럴 상수를 사용하는 것이 좀 더 안전한 프로그램을 만들 수 있다.
(5) 이진 리터럴 상수
- C++14부터는
0B또는0b의 접두사와0과1의 시퀀스를 가지고 이진 리터럴 상수를 표현할 수 있다.
2) 심볼릭 상수
- 심볼릭 상수는 변수와 마찬가지로 이름을 가지고 있는 상수이다.
- 심볼릭 상수는 선언과 동시에 반드시 초기화해야 한다.
- 이러한 심볼릭 상수는 매크로를 이용하거나,
const키워드를 사용하여 선언할 수 있다. - 하지만 매크로를 이용한 선언은 C의 문법이므로, C++에서는 가급적
const키워드를 사용하여 선언하도록 한다.
- C++에서 심볼릭 상수를 만드는 일반적인 방식은 다음과 같다.
- 위의 코드처럼
const키워드를 사용한 상수는 선언과 함께 반드시 초기화해야 한다. - 매크로를 이용한 선언보다
const키워드를 사용한 심볼릭 상수의 장점은 다음과 같다.
1] 상수의 타입을 명시적으로 지정할 수 있다.
2] 구조체와 같은 복잡한 사용자 정의 타입에서도 사용할 수 있다.
3] 해당 심볼릭 상수를 특정 함수나 파일에서만 사용할 수 있도록 제한할 수 있다.
4. 기본 타입
- 타입이란 해당 데이터가 메모리에 어떻게 저장되고, 프로그램에서 어떻게 처리되어야 하는지를 명시적으로 알려주는 역할을 한다.
- C++에서는 여러 형태의 타입을 제공하고 있는데, 이것을 기본 타입이라고 한다.
- 이러한 기본 타입은 크게 정수형, 실수형, 문자형 그리고 불 타입으로 나눌 수 있다.
1) 정수형 타입
- C++에서 정수란 부호를 가지고 있으며, 소수 부분이 없는 수를 의미한다.
- 정수형 데이터에
unsigned키워드를 추가하면, 부호를 나타내는 최상위 비트(MSB)까지도 크기를 나타내는 데 사용할 수 있다. unsigned정수로는 음의 정수를 표현할 수는 없지만,0을 포함한 양의 정수는 두 배 더 많이 표현할 수 있게 된다.- 음의 정수까지도 표현할 수 있는
signed키워드는 모든 타입에서 기본적으로 생략할 수 있다.
최상위 비트(MSB: Most Significant Bit)
- 최상위 비트란 1바이트를 구성하는 8개의 비트 중 최고값을 갖는 비트를 의미한다.
- 정수형 데이터의 타입을 결정할 때에는 반드시 자신이 사용하고자 하는 데이터의 최대 크기를 고려해야 한다.
- 타입이 표현할 수 있는 범위를 벗어난 데이터를 저장하면 오버플로우가 발생해 전혀 다른 값이 저장될 수 있다.
- 오버플로우란 해당 타입이 표현할 수 있는 범위를 넘는 데이터가 저장될 때 발생하는 현상을 가리킨다.
- 오버플로우가 발생하면 MSB를 벗어난 데이터가 인접 비트를 덮어쓰므로, 잘못된 결과를 얻을 수 있다.
- 다음의 코드는
int타입의 변수에 해당 타입이 저장할 수 있는 최댓값과 그 최댓값을 넘는 숫자를 대입하는 것이다.
#include <iostream>
using namespace std;
int main() {
int num = 2147483647;
cout << "변수 num에 저장된 값은 " << num << "입니다." << endl;
num = 2147483648;
cout << "변수 num에 저장된 값은 " << num << "입니다." << endl;
return 0;
}
// 변수 num에 저장된 값은 2147483647입니다.
// 변수 num에 저장된 값은 -2147483648입니다.
- 두 번째 실행 결과를 보면, 변수
num에 양수를 대입했지만 음수로 저장된 것을 확인할 수 있다. - 이처럼 오버플로우가 발생하면 전혀 예상하지 못한 결과를 얻을 수 있으므로, 데이터를 저장할 때는 언제나 해당 데이터 타입의 최대 크기까지 고려해야 한다.
- 컴퓨터는 내부적으로 정수형 중에서도
int타입의 데이터를 가장 빠르게 처리한다. - 따라서 정수형 데이터는 보편적으로
int타입을 가장 많이 사용한다.
2) 실수형 타입
- C++에서 실수란 소수부나 지수가 있는 수를 가리키며, 정수보다 훨씬 더 넓은 표현 범위를 가진다.
- 하지만 컴퓨터에서 실수를 표현하는 방식은 오차가 발생할 수밖에 없는 태생적 한계를 지닌다.
- 이러한 실수형 데이터의 오차는 C++뿐만 아니라 모든 프로그래밍 언어에서 발생하는 공통된 문제이다.
- 다음의 코드는 소수점을
16자리 가지는 실수를float타입과double타입의 변수에 각각 대입하는 것이다.
#include <iostream>
using namespace std;
int main() {
float num01 = 3.1415926535897932; // float 타입의 유효 자릿수는 소수점 6자리
cout << "변수 num01에 저장된 값은 " << num01 << "입니다." << endl;
double num02 = 3.1415926535897932; // double 타입의 유효 자릿수는 소수점 16자리
cout << "변수 num02에 저장된 값은 " << num02 << "입니다." << endl;
return 0;
}
// 변수 num01에 저장된 값은 3.14159274101257324219입니다.
// 변수 num02에 저장된 값은 3.14159265358979311600입니다.
- 변수
num01에는 소수점6자리까지만 정확한 값이 저장되어 있고, 소수점7자리부터는 틀린 값이 저장되어 있다. - 또한, 변수
num02에는 소수점15자리까지만 정확한 값이 저장되어 있고, 소수점16자리부터는 틀린 값이 저장되어 있는 것을 확인할 수 있다.
- 과거에는 실수를 표현할 때
float타입을 많이 사용했지만, 하드웨어의 발달로 인한 메모리 공간의 증가로 현재에는double타입을 가장 많이 사용한다.
3) 문자형 타입
- C++에서 문자형 데이터란 작은 정수나 문자 하나를 표현할 수 있는 타입을 가리킨다.
- 컴퓨터는 2진수밖에 인식하지 못하므로 문자도 숫자로 표현해야 인식할 수 있다.
- 따라서 어떤 문자를 어떤 숫자에 대응시킬 것인가에 대한 약속이 필요하게 된다.
- 이러한 약속 중에서 가장 많이 사용되는 것이 바로 아스키코드(ASCII)이다.
- 아스키코드는 영문 대소문자를 사용하는
7비트의 문자 인코딩 방식이다. - 아스키코드는 문자를
7비트로 표현하므로 총128개의 문자를 표현할 수 있다.
4) 불 타입
- 이전의 C++에서는 C와 마찬가지로
0인 값을 거짓으로,0이 아닌 값을 참으로 인식했다. - 하지만 C++11부터는
bool타입이라는 새로운 타입을 제공하고 있다. bool타입은 참(true)이나 거짓(false) 중 한 가지 값만을 가질 수 있는 불리언 타입이다.- C++에서는 어떤 값도
bool타입으로 묵시적 타입 변환이 가능하다. - 이때
0인 값은 거짓(false)으로,0이 아닌 값은 참(true)으로 자동 변환된다.
5) auto 키워드를 이용한 선언
- C++11부터는 변수의 초기화 값에 맞춰 변수의 타입을 추론할 수 있다.
- 즉, 변수를 초기화할 때 특정 타입을 명시하는 대신에,
auto키워드를 사용하여 초깃값에 맞춰 타입이 자동으로 선언되도록 설정할 수 있다. - 기존의
auto키워드는 자동 저장소 클래스에 있는 지역 변수를 선언하는 데 사용되는 기억 클래스 지정자였다. - 하지만 사용하는 의미가 거의 없었기 때문에 기존의
auto키워드는 거의 사용되지 않았다. - 하지만 C++11부터는
auto키워드의 의미를 재정의하여, 변수 선언 시 초깃값과 같은 타입으로 변수를 선언할 수 있도록 해준다. - 즉,
auto키워드를 사용하면 복잡한 형식의 변수를 간단하게 선언할 수 있다.
5. 부동 소수점 수
- 컴퓨터에서 실수를 표현하는 방법은 정수에 비해 훨씬 복잡하다.
- 왜냐하면 컴퓨터에서는 실수를 정수와 마찬가지로 2진수로만 표현해야 하기 때문이다.
- 따라서 실수를 표현하기 위한 다양한 방법들이 연구되었으며, 현재에는 다음과 같은 방식이 사용되고 있다.
1] 고정 소수점 방식
2] 부동 소수점 방식
1) 고정 소수점 방식
- 실수는 보통 정수부와 소수부로 나눌 수 있다.
- 따라서 실수를 표현하는 가장 간단한 방식은 소수부의 자릿수를 미리 정하여, 고정된 자릿수의 소수를 표현하는 것이다.
- 32비트 실수를 고정 소수점 방식으로 표현하면 다음과 같다.
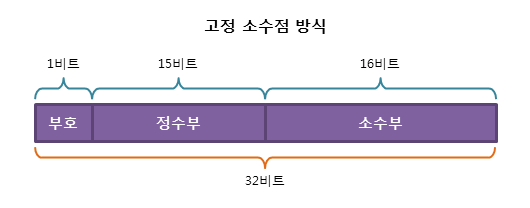
- 하지만 이 방식은 정수부와 소수부의 자릿수가 크지 않으므로, 표현할 수 있는 범위가 매우 적다는 단점이 있다.
2) 부동 소수점 방식
- 실수는 보통 정수부와 소수부로 나누지만, 가수부와 지수부로 나누어 표현할 수도 있다.
- 부동 소수점 방식은 이렇게 하나의 실수를 가수부와 지수부로 나누어 표현하는 방식이다.
- 고정 소수점 방식은 제한된 자릿수로 인해 표현할 수 있는 범위가 매우 작지만 부동 소수점 방식은 매우 큰 실수까지도 표현할 수 있다.
- 현재 대부분의 시스템에서는 부동 소수점 방식으로 실수를 표현하고 있다.
(1) C++ 부동 소수점 표현 방식
- C++에서는 부동 소수점을 다음 두 가지 방식으로 표현할 수 있다.
1] 3.14, -45.6과 같이 소수 부분을 가지는 아라비아 숫자로 표현한다.
2] e 또는 E를 사용하여 지수 표기법으로 표현한다.
- 다음 그림은 C++에서 지수를 표현하는 데 사용되는
E지수 표기법을 보여주는 그림이다.

(2) IEEE 부동 소수점 방식
- 현재 사용되고 있는 부동 소수점 방식은 대부분 IEEE 754 표준을 따르고 있다.
- 32비트의
float타입 실수를 IEEE 부동 소수점 방식으로 표현하면 다음과 같다.
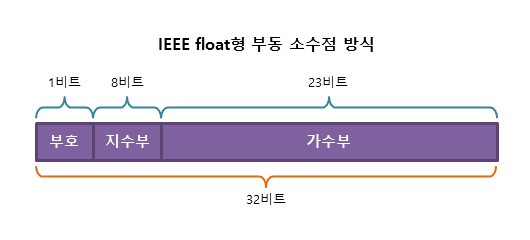
- 64비트의
double타입 실수를 IEEE 부동 소수점 방식으로 표현하면 다음과 같다.
(3) 부동 소수점 방식의 오차
- 부동 소수점 방식을 사용하면 고정 소수점 방식보다 훨씬 더 많은 범위까지 표현할 수 있다.
- 하지만 부동 소수점 방식에 의한 실수의 표현은 항상 오차가 존재한다는 단점을 가지고 있다.
- 부동 소수점 방식에서의 오차는 부동 소수점을 계산하는 공식에 의해 발생하는데, 이 공식을 사용하면 표현할 수 있는 범위는 늘어나지만 10진수를 정확하게 표현할 수는 없게 된다.
- 따라서 컴퓨터에서 실수를 표현하는 방법은 정확한 표현이 아닌 언제나 근사치를 표현할 뿐임을 항상 명심해야 한다.
- 다음의 코드는 부동 소수점 방식으로 실수를 표현할 때 발생할 수 있는 오차를 보여주는 것이다.
#include <iostream>
using namespace std;
int main() {
int i;
float sum = 0;
for (i = 0; i < 1000; i++) {
sum += 0.1;
}
cout << "0.1을 1000번 더한 합계는 " << sum << "입니다.";
return 0;
}
// 0.1을 1000번 더한 합계는 99.999입니다.
0.1을1000번 더한 합계는 원래100이 되어야 하지만, 실제로는99.999가 출력된다.- 이처럼 컴퓨터에서 실수를 가지고 수행하는 모든 연산에는 언제나 작은 오차가 존재하게 된다.
- 이것은 C++뿐만 아니라 모든 프로그래밍 언어에서 발생하는 기본적인 문제이다.
6. 타입 변환
- C++에서 다른 타입끼리의 연산은 우선 피연산자들을 모두 같은 타입으로 만든 후에 수행된다.
- 이처럼 하나의 타입을 다른 타입으로 바꾸는 행위를 타입 변환이라고 한다.
- C++에서는 다음과 같은 경우에 자동으로 타입 변환을 수행한다.
1] 다른 타입끼리의 대입, 산술 연산 시
2] 함수에 인수를 전달할 때
- 이때 표현 범위가 좁은 타입에서 표현 범위가 더욱 넓은 타입으로의 타입 변환은 큰 문제가 되지 않는다.
- 하지만 반대의 경우처럼 표현 범위가 좁은 타입으로의 타입 변환은 데이터의 손실이 발생한다.
1) 타입 변환의 종류
- C++에서 타입 변환은 크게 다음과 같이 두 가지 방식으로 나뉜다.
1] 묵시적 타입 변환(자동 타입 변환)
2] 명시적 타입 변환(강제 타입 변환)
(1) 묵시적 타입 변환(자동 타입 변환)
- 묵시적 타입 변환은 대입 연산이나 산술 연산에서 컴파일러가 자동으로 수행해 주는 타입 변환을 가리킨다.
- C++에서는 대입 연산 시 연산자의 오른쪽에 존재하는 데이터의 타입이 연산자의 왼쪽에 존재하는 데이터의 타입으로 묵시적 타입 변환이 진행된다.
- 산술 연산 시에는 데이터의 손실이 최소화되는 방향으로 묵시적 타입 변환이 진행된다.
- 다음의 코드는 대입 연산에서 일어나는 묵시적 타입 변환을 보여주는 것이다.
#include <iostream>
using namespace std;
int main() {
int num1 = 3.1415;
int num2 = 8.3E12;
double num3 = 5;
cout << "num1에 저장된 값은 " << num1 << "입니다." << endl;
cout << "num2에 저장된 값은 " << num2 << "입니다." << endl;
cout << "num3에 저장된 값은 " << num3 << "입니다." << endl;
return 0;
}
// num1에 저장된 값은 3입니다.
// num2에 저장된 값은 2147483647입니다.
// num3에 저장된 값은 5입니다.
- 첫 번째 연산은
int타입 변수에 실수를 대입하므로 소수 부분이 자동으로 삭제되어 데이터의 손실이 발생한다. - 두 번째 연산에서는
int타입 변수가 저장할 수 있는 최대 범위를 초과한 데이터를 저장하므로 전혀 알 수 없는 결과가 출력된다. - 하지만 세 번째 연산에서는 범위가 큰
double타입 변수에 범위가 작은int타입 데이터를 대입하므로 전혀 문제가 되지 않는다.
- 다음의 코드는 산술 연산에서 일어나는 묵시적 타입 변환을 보여주는 것이다.
#include <iostream>
using namespace std;
int main() {
double result1 = 5 + 3.14;
double result2 = 5.0f + 3.14;
cout << "result1에 저장된 값은 " << result1 << "입니다." << endl;
cout << "result2에 저장된 값은 " << result2 << "입니다." << endl;
return 0;
}
// result1에 저장된 값은 8.14입니다.
// result2에 저장된 값은 8.14입니다.
- 첫 번째 연산은
int타입 데이터와double타입 데이터의 산술 연산이다. - 따라서 데이터의 손실이 최소화되도록
int타입 데이터가double타입으로 자동 타입 변환된다. - 두 번째 연산은
float타입 데이터와double타입 데이터의 산술 연산이다. - 위와 마찬가지로 데이터의 손실이 최소화되도록
float타입 데이터가double타입으로 자동 타입 변환된다.
- 이렇게 컴파일러가 자동으로 수행하는 타입 변환은 언제나 데이터의 손실이 최소화되는 방향으로 이루어진다.
- 따라서 C++에서는 다음과 같은 방향으로 자동 타입 변환이 이루어진다.
char → short → int → long → float → double → long double 타입
- 참고로 산술 연산 시
bool타입 데이터인true는1로,false는0으로 자동 타입 변환된다.
(2) 명시적 타입 변환(강제 타입 변환)
- 명시적 타입 변환은 사용자가 타입 캐스트(Type Cast) 연산자를 사용하여 강제적으로 수행하는 타입 변환을 가리킨다.
- C++에서는 다음 두 가지 방식으로 명시적 타입 변환을 수행할 수 있다.
- 변환시키고자 하는 데이터나 변수의 앞과 뒤에
()(괄호)를 붙이고, 그()안에 변환할 타입을 적으면 된다. - C++에서는 이
()를 타입 캐스트 연산자라고 한다.
- 다음의 코드는 명시적 타입 변환을 보여주는 것이다.
#include <iostream>
using namespace std;
int main() {
int num1 = 1;
int num2 = 4;
double result1 = num1 / num2;
double result2 = (double)num1 / num2;
double result3 = double(num1) / num2;
cout << "result1에 저장된 값은 " << result1 << "입니다." << endl;
cout << "result2에 저장된 값은 " << result2 << "입니다." << endl;
cout << "result3에 저장된 값은 " << result3 << "입니다." << endl;
return 0;
}
// result1에 저장된 값은 0입니다.
// result2에 저장된 값은 0.25입니다.
// result3에 저장된 값은 0.25입니다.
- 첫 번째 연산의 결괏값은
0으로 출력된다. - 그 이유는 산술 연산에 대한 결괏값의 타입은 언제나 피연산자의 타입과 일치하기 때문이다.
- 즉,
int타입 데이터끼리의 산술 연산에 대한 결괏값은 언제나int타입 데이터로 나오게 된다. - 따라서 두 번째 연산에서처럼 하나의 피연산자를 명시적으로
double타입으로 변환해야만 정확한 결괏값을 얻을 수 있다. - 세 번째 연산은 C++에서만 사용할 수 있는 명시적 타입 변환 스타일의 사용법을 보여주고 있다.